
[和訳] Dockerリファレンスアーキテクチャ: Docker EEのベストプラクティスと設計の考慮点 (17.06版) #docker
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本稿は Docker Reference Architecture: Docker EE Best Practices and Design Considerations (EE-17.06) の和訳です。
はじめに
Docker Enterprise Edition (Docker EE)は、Docker社が提供するエンタープライズコンテナプラットフォームであり、ソフトウェアサプライチェーン全体を管理することを目的としています。これは、コンテナベースのアプリケーション開発、展開、および管理のための完全な統合ソリューションです。エンド・トゥ・エンドのセキュリティを統合したDocker EEは、インフラストラクチャを抽象化することでアプリケーションのポータビリティを向上し、アプリケーションを開発段階から本番環境へとシームレスに移行できます。
このリファレンスアーキテクチャで学ぶこと
このリファレンスアーキテクチャは、標準的な本番環境におけるDocker EEのデプロイ方法を説明しています。またDocker EEのコンポーネント、動作方法、デプロイの自動化方法、ユーザとチームの管理方法、プラットフォームの高可用性の提供方法、およびインフラストラクチャの管理方法についても詳しく説明します。
ただし一部の環境固有の設定は紹介していません。例えばロードバランサは、クラウドとオンプレミスで大きく異なるため取り扱いません。これらのタイプのコンポーネントには環境固有のリソースに関する一般的なガイドラインを用意するに留めています。
Dockerのコンポーネントについて
開発環境から本番環境にわたり、Docker EEはオンプレミスとクラウドの両方で、コンテナ化したアプリケーションの統一したプラットフォームを提供します。Docker EEでは、さまざまなアプリケーションのニーズを満たすために3つの形態を用意しています。Docker EE Standard (旧Docker Datacenter)とDocker EE Advancedは、次のコンポーネントを含みます:
- Docker EE Basic (旧CS Engine): オープンソース版Dockerコンテナランタイムとプラットフォームの商用サポート版
- Universal Control Plane (UCP): Webベースで統合的な、クラスタおよびアプリケーションの管理ソリューション
- Docker Trusted Registry (DTR): 弾力的でセキュアなイメージ管理レポジトリ
併せて、次の目標を達成するための統合ソリューションを提供します。
- アジリティ: プラットフォームとのインターフェイスにDocker APIを利用しているので、アプリケーションのデリバリを高速に処理します。
- ポータビリティ: プラットフォームは、アプリケーションのために、インフラの抽象化を行います。
- コントロール: デフォルトでセキュアである環境は、堅牢なアクセス制御とすべての操作ログを提供します。
これらの目標を達成するために、プラットフォームは弾力的で高可用でなければいけません。このリファレンスアーキテクチャでは、堅牢な構成例を提供します。
Docker EE Basic
Docker EEプラットフォームは、コンテナに対する操作、OSとの相互通信、Docker APIの提供、そしてSwarmクラスタの実行を担当します。Docker Engineは、OSリソース、ネットワーキング、そしてストレージなど、インフラの統合点でもあります。
Universal Control Plane (UCP)
UCPは、統合されたアプリケーション管理プラットフォームを提供することで、Docker EE Basicを拡張します。UCPはユーザに対する主要な結合点であり、アプリに対する統合点でもあります。UCPは監視のために、クラスタ内のすべてのノード上にエージェントを配置し、 コントローラノード 上に複数のサービスを配置します。このサービスは、ユーザ管理のための IDサービス 、ユーザとクラスタPKIのための 証明書認証局 (Certificate Authority; CA)、ウェブUIとAPIを提供するメイン コントローラ 、UCPの状態を保持するためのデータストア、後方互換のための Classic Swarm サービスを含みます。
Docker Trusted Registry (DTR)
DTRはDockerイメージの配布とセキュリティサービスを提供する、UCPと統合・管理されるアプリケーションです。DTRはUCPのID管理サービスを利用してシングルサインオン(SSO)を提供し、PKIと統合ための相互信頼を確立します。DTRは1つまたは複数の レプリカ 上で、いくつかのサービスとして実行しています。イメージの格納と配布のための レジストリ 、イメージ署名サービス、ウェブUI、API、イメージのメタデータとDTRの状態を保持するためのデータストアです。
Swarm Mode
複数ノードによって構成するシームレスなクラスタを提供するために、Docker EEはDocker Engineの Swarm Mode機能を使用しています。Swarm Modeはノード群を次の2種類に分けて管理します。サービスとして定義されたアプリケーションのワークロードを実行するノードである ワーカーノード と、ノードの「あるべき状態」の維持、クラスタの内部PKIの管理、APIの提供を行うノードである マネージャノード です。マネージャノードでもワークロードを実行することができます。ただし、Docker EE環境のマネージャノードではUCPコントローラを実行しているので、他に何も実行すべきではありません。
Swarm Modeのサービスモデルは、ワークロードや タスク 数(サービスのコンテナ数)についての宣言的な「あるべき状態」を提供しています。また、安定的に解決可能なホスト名を通してアクセス可能であり、オプションとしてエンドポイントも公開可能です。公開されたサービスは、クラスタ全体で予約したポートと任意のノードに対してアクセス可能で、Linuxカーネルの高性能スイッチング機能を採用した高速ルーティングレイヤである ルーティングメッシュ 経由でタスクに到達します。この一連の機能により、内部と外部両方のサービスディスカバリが可能となり、UCPの HTTPルーティングメッシュ (HRM)ではホスト名とサービス間のマッピングが可能となりました。
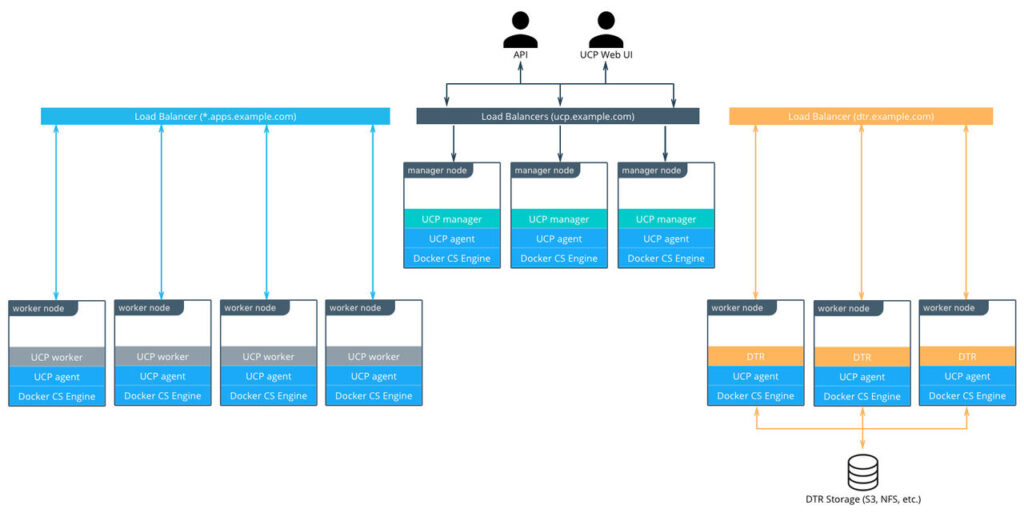
標準的なデプロイアーキテクチャ
この章では、3つのUCPコントローラ、3つのDTRノード、およびアプリケーションワークロード用の4つのワーカーノードによって構成した、10個のノードを使用するDocker EEの標準的なアーキテクチャを解説します。ワーカーノードの数は任意で、ほとんどの環境ではアプリケーションのニーズに応じて決まります。ただし、アーキテクチャやクラスタ構成はワーカーノードの数に限らず基本的に同じです。
環境へのアクセスは3つのロードバランサ (または3つのロードバランサ仮想ホスト)を通して、UCPコントローラ、DTRレプリカ、およびクラスタで実行するアプリケーションに対応するDNSエントリに対して行います。
DTRレプリカはイメージ用の共有ストレージを使用します。S3互換のオブジェクトストレージ (デフォルト)と、NFSストレージの両方をこの章で扱います。

標準的な本番環境向けのDocker EEインフラストラクチャ
ノードのサイズ
ノードは、Docker Engineが稼働しているクラスタ内の(仮想または物理)マシンです。各ノードをプロビジョニングの際は、アプリケーションのワークロードが稼働しないように、ノードに対してUCPコントローラ、DTR、またはワーカーノードの役割を割り当てます。
CPU、RAMおよびストレージリソースに関してノードのサイズを決定するには、次の点を考慮してください:
1.すべてのノードは、UCP 2.2の最小要件を満たしている必要があります(2GBのRAMと3GBのストレージ)。より詳細な要件については、UCPのドキュメントを参照してください。
2. UCPコントローラノードには、他に何も稼働しないのであれば、最小要件以上を用意する必要はありません。
3. 理想的なワーカーノードのサイズは、各ノードにおけるワークロードに応じて異なるため、あらゆる場合に対応できる標準的なサイズを定義することは不可能です。
4. また、集積密度(ノードあたりのコンテナの平均数)、標準的なノード1種類だけが必要か複数の種類が必要かどうか、その他の操作上の考慮点なども、ノードサイズを決めるポイントとなります。
可能であれば、実際のワークロードの検証やテストを行ってから、ノードのサイズを決定することをお勧めします。まずは、あなたの環境における標準、またはデフォルトのマシンタイプを選択し、そのサイズのみを使うことから始めるとよいでしょう。その標準マシンタイプが、UCPコントローラに必要なリソースより多くのリソースを提供する場合は、コントローラ用のノードサイズを小さくするのが適切でしょう。最初の選択に関わらず、モデルを改善すべくリソースとコストの使用状況を監視することが重要です。
2つのシナリオ例:
- 標準ノードサイズが1種類: 2 VCPU、8 GB RAM、20 GBストレージ
- ノードサイズが2種類:
- UCPコントローラ用: 2 VCPU、8 GB RAM、20 GBストレージ
- ワーカーノード用: 4 VCPU、64 GB RAM、40 GBストレージ
お使いのOSによっては、Docker Engineのストレージ構成に何らかの設定が必要な場合があります。お使いのホストOSでサポートしている ストレージドライバ を確認するには、 サポートマトリックス を参照してください。これは direct-lvmでdevicemapper を使用するRHELまたはCentOSを使用している場合に特に重要です。
ロードバランサ
ロードバランサの設定は、DNSエントリの作成を含め、インストール前に行う必要があります。ほとんどのロードバランサがDocker EEで動作するでしょう。唯一の要件は、TCPパススルーとHTTPSエンドポイントでヘルスチェックを行う機能です。
このアーキテクチャ例では、3台構成のUCPコントローラによって、ノードの障害やコントローラの再構成時においても安定稼働を保証します。GUIまたはAPIによるUCPへのアクセスは、常にTLSを使用しています。ロードバランサは、443番ポート上の単純なTCPパススルーを行います。また、 https://UCPコントローラ/_ping のカスタムHTTPSヘルスチェックを使用するように構成します。
ucp.example.comなどのUCPホストのDNSエントリを作成し、ロードバランサを指し示すように設定してください。
3つのDTRレプリカの設定は、UCPコントローラの設定と同様です。繰り返しますが、ヘルスチェックである https://DTRレプリカノード/health を除いて、ノード上の443番ポートに対するTCPパススルーを設定しましょう。
dtr.example.comなどのDTRホストのDNSエントリを作成し、ロードバランサを指し示すように設定します。これはDTRに格納するDockerイメージのフルネームの一部になるため、できるだけ簡潔にすることが重要です。例えば、“user_a”ユーザが所有する“webserver”イメージはdtr.example.com/user_a/webserverという名前になります。
アプリケーションロードバランサは、UCPのHTTPルーティングメッシュ(HRM)を介して公開する、サービス用のHTTPエンドポイントへのアクセスを提供します。HRMは、ポートを公開し、ucp-hrmオーバーレイネットワークに接続しているサービスに対して、ドメイン名をマッピングするリバースプロキシを提供します。一例として、votingアプリケーションはvoteサービスの80番ポートを公開するとします。HRMは、http://vote.apps.example.comに対するアクセスをucp-hrmオーバーレイネットワーク上の80番ポートに割り当てます。そしてアプリケーションのロードバランサ自身は、*.apps.example.comをクラスタ内のノードにマッピングします。
UCP上のアプリケーションのロードバランシングの詳細については、Universal Control Plane 2.0: サービスディスカバリとロードバランシング を参照してください。
DTRストレージ
DTRは通常、大量のイメージを格納する必要があります。ノード上のストレージではなく外部ストレージ(S3、NFSなど)を使用して、DTRレプリカ間でそれらを共有することになります。DTRはレプリカ間でメタデータと構成情報を複製します。ただし、イメージレイヤ自体は複製しません。ストレージのサイズを決定するには、環境で使用されている既存のイメージのサイズから始め、そこから拡張していくようにしましょう。
既存の運用経験を活かすためにも、ご使用の環境での既存のストレージソリューションを使用することが最善です。新しいソリューションを選択する必要がある場合は、レジストリ運用の仕様に近い、S3互換のオブジェクトストレージの使用を検討してください。
ストレージソリューションの選択の詳細については、 Docker CaaS用のストレージソリューションの概要 を参照してください。
おすすめのDocker EEインストール方法
この章では、アーキテクチャのインストールプロセスについて説明し、チェックリストも提供します。これはより詳細な情報を提供し、どのような場合にも適合するドキュメントの代わりではありません。ここではDocker EE環境を導入、設定、アップグレード、および拡張するための反復可能な(そして理想的には自動化された)プロセスの定義を支援することが目標です。
Docker EE StandardまたはAdvancedのインストールにおける3つの主要な段階は次の通りです:
- インフラストラクチャのデプロイと設定(ホスト、ネットワーク、ストレージ)
- Docker Engineのインストールと設定、およびホスト上でアプリケーションとして実行
- Docker Engine上で動作するコンテナとして提供されるUCPとDTRのインストールと設定
インフラに関する考慮点
インストールドキュメント には、Docker EE StandardおよびAdvancedのインフラストラクチャ要件の詳細を記載しています。インフラストラクチャコンポーネントを標準化し、かつ再現可能な構成を提供するには、環境内の既存またはプラットフォーム固有のツールを使用することをお勧めします。
ネットワーク
Dockerコンポーネントはネットワーク経由で通信する必要があり、ドキュメントにクラスタの内部通信用に 解放すべきポート をリストアップしています。クラスタの内部ネットワークを誤って構成すると、追跡が困難な問題が発生する可能性があります。まずは比較的簡単な環境から始める方がよいでしょう。このリファレンスアーキテクチャでは、すべてのホストが単一サブネットに存在し、コンテナに対してオーバーレイネットワークを提供することを想定しています。
詳細を確認してオプションを評価するには、 Dockerリファレンスアーキテクチャ: 拡張可能で可搬性に優れたDockerコンテナネットワーク を参照してください。
ファイアウォール
Docker EEへのアクセスは、Web UIまたはリモートAPIに関わらず、443番ポート(DTRでは443番ポートと80番ポート)のみを使用して行います。これにより、外部ファイアウォールの設定が簡単になります。ほとんどの場合、80番ポート、443番ポート、22番ポートの開放だけで済みます。22番ポートはDocker EEがSSHアクセスを必要としないため、SSHアクセスはオプショナルです。アプリケーションへのアクセスは、HTTPSを使用するロードバランサ経由となります。他のTCPサービスを外部に公開する場合は、これらのポートをファイアウォールで開放します。前章で説明したように、クラスタ内の通信にはいくつかのポートを開放する必要があります。例えば、クラスタ内の一部のノード間にファイアウォールがある場合、またはコントローラノードをワーカーノードから分離するには、関連するポートも開放する必要があります。
オーバーレイネットワークを暗号化してアプリケーション内で使用する場合、ESP (Encapsulating Security Payload)またはIPプロトコル番号50のトラフィックも許可する必要があります。ESPはTCPまたはUDPに基づいておらず、セキュリティペイロード/データのエンド・トゥ・エンドのカプセル化に使用します。
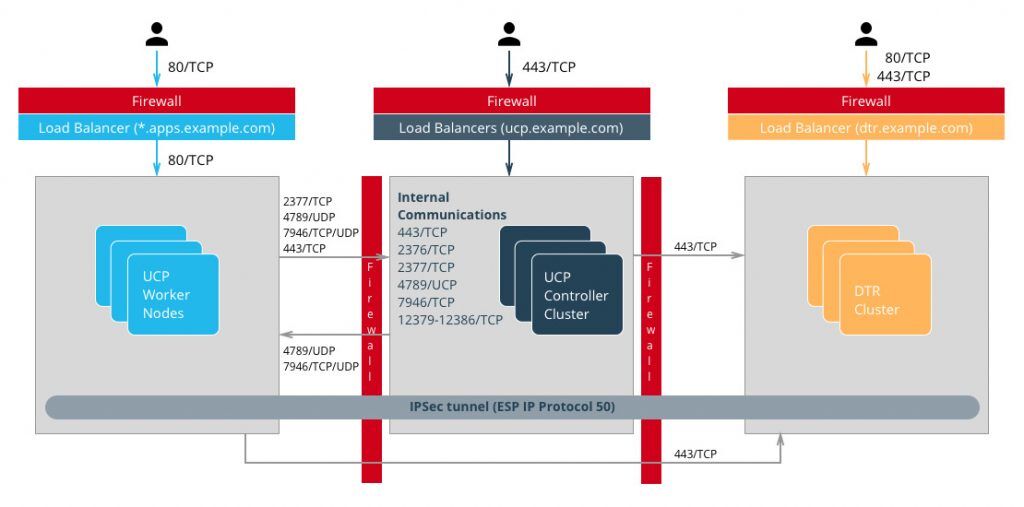
Dockerのポート
ロードバランサ
ロードバランサの詳細については、前章を参照してください。Docker EEのインストール前に、ロードバランサをインストールする必要があり、適切なホスト名でプロビジョニングする必要があります。外部(ロードバランサ)ホスト名は、HAおよびTLS証明書にも使用します。Docker EEのインストール中またはインストール後に、これらを再構成する必要のない方が簡単です。
ロードバランサの設定の詳細については、前章の Dockerのコンポーネントについてを参照してください。
共有ストレージ
レジストリに格納するイメージ用のDTR共有ストレージは、すべてのDTRノードからアクセス可能でなければなりません。S3またはNFSコマンドラインクライアントを使用して動作テストし、DTRストレージ構成を後でデバッグしないで済むようにしましょう。
ホスト設定
ホストの設定は、使用するOSと既存の設定基準によって異なりますが、OSのインストール後に行う必要がある重要な手順がいくつかあります:
- 時刻同期 にNTPまたは同様のサービスを使用します。クロックスキュー(時刻同期のずれ)は、特にRaftアルゴリズムが使われている箇所(UCPとDTR)でのデバッグが難しくなります。
- 静的IPアドレス は、すべてのホストのUCPに必要です。
- ホスト名 は、クラスタ内のノード識別に使用します。ホスト名は永続的な方法で設定する必要があります。
- ホストファイアウォール は、インストールドキュメントで指定したすべてのポートでクラスタ内の通信を開放する必要があります。
- ストレージ は、必要に応じて設定する必要があります。例えば、devicemapperドライバは、Docker Engineをインストールする前に論理ボリュームを設定しておく必要があります。
Docker EE Basicのインストールの考慮点
Docker EEの詳細なインストール手順は、マニュアル に記載しています。インターネットにアクセスできないマシンにインストールするには、これらのパッケージを自前のプライベートリポジトリに追加します。パッケージをインストールした後、Dockerサービスがシステムブート時に起動するように設定していることを確認します。
Docker EE Basicのパラメータを変更する最善の方法は、/etc/docker/daemon.json設定ファイルを使用することです。これにより、異なるシステムとOS間で一貫した方法で構成を再利用できるようになります。オプションの完全なリスト については、ドキュメントを参照してください。
Dockerサービスを開始し、docker infoでパラメータを確認して、Docker Engineを正しく構成していることを確認してください。
UCPのインストールの考慮点
UCPインストーラは、Docker EE Basicを実行している一連のマシンから実際のクラスタを作成します。これには、Swarmクラスタの作成とUCPコントローラのインストールを含みます。 インストールガイド で説明しているデフォルトのインストールモードは対話式です。
完全自動化された再現可能なデプロイを実施するには、インストーラにさらに情報を提供します:
docker run --rm -v /var/run/docker.sock:/var/run/docker.sock \
-v /tmp/docker_subscription.lic:/config/docker_subscription.lic \
-e UCP_ADMIN_PASSWORD=password --name ucp docker/ucp install \
--host-address IPアドレスかインターフェイス \
--san manager1.example.com --san ucp.example.com
これらの各オプションについては、次章で説明します。
外部証明書
デフォルトでは、UCPは自己署名のTLS証明書を使用します。本番環境では、信頼できるCAによって生成した証明書を使用することをお勧めします。大抵の企業の場合、組織内部のCAになります。
必要な証明書とキーは次の通りです:
- ルートCAの公開証明書であるca.pem
- TLS証明書であるcert.pem。このファイルには中間CAの公開証明書も含める必要があります。SANにはUCPのすべてのIPアドレスやホスト名を持っている必要があります。SANにはロードバランサのホスト名(例:ucp.example.com)や個々のコントローラのホスト名(例: ucp-controller1.example.com)も含みます。これにより、それらのIPアドレスやホスト名での直接アクセスを可能とします。
- TLS秘密鍵であるkey.pem
これらのファイルをインストール時に自動的に追加するには、UCPをインストールするマシン上のucp-controller-server-certsというDockerボリュームに前述のファイル名で追加し、--external-server-certインストールパラメータで指定します。
また、インストール後にウェブUIから証明書を追加することもできます。
ライセンスファイル
ライセンスファイルは、/configのバインドマウント(ボリューム)もしくはコマンドラインでインストールできます。 -v /path/to/docker_subscription.lic:/config/docker_subscription.lic でファイルの場所を指定します。
管理者パスワード
インストールを自動化するには、--admin-passwordインストールパラメータを使用してadminパスワードを指定する必要があります。管理者のユーザ名は、デフォルトではadminです。変更するには--admin-usernameを使用します。
インストールパラメータの完全なリストは、 インストールコマンドドキュメント に記載しています。
ノードの追加
最初のコントローラノードのインストールが完了したら、2つのコントローラノードをインストールし、クラスタに追加する必要があります。UCPはクラスタ内のマネージャノード上にコントローラノードの完全な複製を設定します。したがって、2つのコントローラノードで、正しいトークンを持つdocker swarm joinを実行するだけで追加が可能です。正確なコマンドは、1番目のコントローラノードでdocker swarm join-token managerを実行すると取得できます。
ワーカーノードがクラスタに参加するには、任意のコントローラノード上でdocker swarm join-token workerを実行し、先程と似たようなコマンドを取得します:
$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-00gqkzjo07dxcxb53qs4brml51vm6ca2e8fjnd6dds8lyn9ng1-092vhgjxz3jixvjf081sdge3p \
192.168.65.2:2377
すべて正しく行われたことを確認するには、https://ucp.example.comでUCPにログインしてください。
DTRのインストールの考慮点
DTRのインストール方法は、UCPの方法に似ています。1つのノードをインストールして構成し、レプリカを追加して完全な高可用性の設定を構成します。最初のインスタンス、そしてレプリカをインストールするには、インストーラでクラスタ内の対象のノードを指定します。
インストール後に証明書とイメージストレージを設定する必要があります。共有ストレージを設定すると、joinコマンドを使用して2つのレプリカが追加できるようになります。
デプロイの検証
すべてのインストールが完了したら、デプロイを検証するためのテストを行うことができます。UCPコントローラおよびDTRを実行するノードに対するワークロードのスケジューリングを無効にします。
基本テストの考慮点:
- https://ucp.example.comにログインするのと同じように、マネージャノードに直接ログインします。例えば https://manager1.example.com に対してログインします。クラスタとすべてのノードが正常であることを確認します。
- ドキュメントの例 に従って、アプリケーションがデプロイできることをテストします。
3.ユーザのClient Bundleをダウンロードし、CLIでクラスタに接続できることをテストします。 docker-compose が実行できるかどうかをテストします。 - イメージの構築・出荷における完全なワークフローを用いてDTRをテストします。ストレージを正しく構成できていて、イメージを適切な場所に保存していることを確認してください。
新しい環境と更新を検証するための、標準的な自動テストスイートを構築することをお勧めします。標準的な機能を確認するだけでも、設定におけるほとんどの問題を見つけることができるでしょう。管理者権限を持たないユーザでこのテストを実行するようにしてください。このテスト用のユーザは、プラットフォーム上の実際のユーザとほぼ同じ権限を持つようにします。各テスト実行の際の時間を測定することで、基盤となるインフラストラクチャの設定における問題を特定することもできます。またテストスイートの一部として、実際にアプリをデプロイする完全な工程も組み込んで、確実な検証を行うようにしましょう。
Docker EEにおけるHA(High Availability)機能
本番環境においては、重要なサービスのダウンタイムを最小に留めることは重要な要件です。そのため、UCPとDTRではHAをどのように達成しているか、障害時に何を行っているかを理解することが重要となります。UCPとDTRは、同じ手法でHAを提供しています。ただし、UCPではSwarmの機能に密接に関係しています。基本的には、核となるサービスをクラスタ構成で多重化することで、任意のノードが障害を起こした時に他のノードが代わりに稼働するように設定します。ロードバランサで固定のホスト名を提供することで、実際に処理を行っているノードがどれなのか、ユーザは気にしないでよくなります。実際にHA機能を提供するのは、水面下のクラスリングメカニズムです。
Swarm
UCPのHA機能は、Docker Engineのクラスタリング機能であるSwarmが提供しています。Docker Engineドキュメントの詳細の通り、Swarmクラスタを管理するアルゴリズムは2つ存在します:
- ワーカーノードのためのGossipプロトコル
- マネージャノードのためのRaftコンセンサスアルゴリズム
Gossipプロトコルは eventually consistent (結果整合性)であり、クラスタ内にデータ変更が行われた際に、そのデータを反映したノードとそうでないノードが共存する可能性があります(このデータ変更がウイルスのように広がっていくので、 epidemic protocol (伝染性プロトコル)とも呼ばれます)。1つの変更がクラスタ全体に反映されるまで待つ必要がないので、非常に規模の大きいクラスタを運用する際にこの手法が適しています。マネージャが取り扱うタスクは高い同期性を持つ情報に基く必要があります。なぜなら、クラスタとサービスのすべての状態に基く決定を下す必要があるからです。
実際には、可用性を妨げずに 一貫性 を保証するのは困難です。なぜなら、データの書き込みはすべてのクラスタメンバーで合意が形成されなければならないからです。一つでも応答を返さない、あるいは応答が遅いクラスタメンバーが存在すると、クラスタ全体の性能に影響します。これはCAP理論 によって説明できます。簡単に言うと、分散システムの分断耐性:Partition (P)のためには、一貫性:Consistency (C)と可用性:Availability (A)のどちらかを選択しなければいけないということです。Raftのような合意形成アルゴリズムは、この課題を Quorum (定足数)という手法で対応しています。参加者の過半数があるデータに合意すれば、そのデータが十分に正しいとします。そして残りの参加者はそのデータを新しく得ます。つまり書き込みを行うには、3ノードのうち2ノード、5ノードのうち3ノード、7ノードのうち4ノードの合意を得れば十分ということです。
このように合意形成が働くので、Swarmでクラスタを設定する際には、奇数台のノード数を設定することが必要になります。Swarmに3台のマネージャノードを設定すれば、クラスタは1台のノードを失っても残りのノードで一時的な運用が継続できます。クラスタが5台の場合は、一時的に2台まで失うことができます。逆に言えば、3台マネージャを持つクラスタでは、2台のマネージャが書き込みの合意形成ができればよい(マネージャが5台なら3台)です。ただし、マネージャ数を増やすと、マネージャ間でのデータの複製も増加するので、パフォーマンスやスケーラビリティを損なう可能性があります。4台構成は3台構成に比べて1台増えた分のメリットはありません。過半数は3のままなので、障害で失うことができるノードが1台であることに変わらず、むしろ同期のためのデータ量が増えてしまいます。実際には、より壊れやすくなっただけと言えます。
3台のマネージャノードのうち2台を失った場合、クラスタは機能しなくなります。既存のサービスとコンテナは稼動し続けますが、新しい要求は処理されません。 クラスタ内に1台だけマネージャノードが残る結果になっても、単一マネージャモードに「切り替え」ません。これは単に「過半数でないノード」です。 単純にワーカーノードをマネージャノードに昇格しても、定足数を満たすことはできません。障害が起きたノードはまだコンセンサスグループのメンバーであり、障害回復ののち、オンラインに戻る必要があります。
UCP
UCPはすべてのクラスタノード上で、ucp-agentというグローバルサービスを実行します。このエージェントは、すべてのSwarmマネージャノードにUCPコントローラをインストールします。SwarmマネージャとUCPコントローラは1対1に対応しています。ただし、役割は異なります。そのエージェントを使用することで、UCPはSwarmのHA機能を頼っています。ただし、Swarmとは異なる独自のRaftコンセンサスグループに基いた、複製データストアも持っています:
- ucp-auth-store: ID管理データ用の複製データベース
- ucp-kv: UCP構成データ用の複製キーバリューストア
DTR
DTRの複製モデルはUCPの仕組みと同様です。ただし、Swarmとは同期しません。DTRの場合は、1つの複製コンポーネントを持ちます。そのデータストアは、一度に複製する必要がある多くの情報を持ち得ます。これはRaftコンセンサスに基づいています。
UCPコントローラとDTRレプリカのクラスタへの(再)参加時は、どちらも多くの情報を複製する可能性があります。再構成処理によっては、クラスタメンバーを一時的に使用不能にしてしまうかもしれません。3台構成のクラスタの場合は、3つ目のノードを再設定する前に、1つ目と2つ目のノードの同期の完了を待つとよいでしょう。さもないと定足数を失うおそれがあります。一時的に定足数を失ったクラスタの回復は簡単ですが、クラスタが不安定な状態になることには変わりません。クラスタが致命的な状態に陥らないようにコントローラの状態を監視することが重要です。
バックアップとリストア
複数のノードを使用するHA構成では、メンテナンスのための計画的なノードのダウンタイムを含む、一時的な障害の場合でも継続的な可用性を提供するようにうまく機能します。全クラスタの喪失、永続的な定足数の喪失、およびストレージ障害によるデータ損失を含むその他の場合は、バックアップからのリストアが必要です。
UCPのバックアップ
UCPのバックアップは、コントローラノード上でdocker/ucp backupコマンドで実施できます。この際、ノード上のUCPコンテナはすべて停止し、UCPの構成と状態のフルバックアップを実行します。バックアップは機密情報を含むので、常に--passphraseオプションを使用し、バックアップを暗号化すべきです。このバックアップには、UTRだけでなくDTRでも使用しているオーガニゼーション、チーム、ユーザも含みます。定期的なバックアップをスケジューリングしましょう。手入力なしでコマンドを実行する方法の例は次の通りです:
UCPID=$(docker run --rm -i --name ucp -v /var/run/docker.sock:/var/run/docker.sock docker/ucp id)
docker run --rm -i --name ucp -v /var/run/docker.sock:/var/run/docker.sock docker/ucp backup --id $UCPID --passphrase "secret" > /tmp/backup.tar
このバックアップは次の2通りの用途があります:
- コントローラを復元するために、docker/ucp restoreコマンドを使用する(そのコントローラからのバックアップのみが使用可能)。
- 新しいクラスタをインストールするために、docker/ucp install --from-backupコマンドを使用する(ユーザと設定を流用する)。
DTRのバックアップ
DTRバックアップは、構成情報、イメージのメタデータと証明書を含みます。イメージ自体は別途、ストレージから直接バックアップする必要があります。ユーザとオーガニゼーションは、UCPが管理・バックアップすることに注意してください。
バックアップは、docker/dtr restoreコマンドを使用して新しいDTRを作成する場合にのみ使用できます。
ID管理
Docker EE (UCPとDTR)のコンポーネント内のリソース(イメージ、コンテナ、ボリューム、ネットワークなど)と機能にアクセスするには、少なくともアカウントと対応するパスワードが必要です。Docker EE内は、アカウントをID情報として内部データベースに格納します。ただし、それらのアカウントと関連するアクセス管理情報を生成するもととなる情報は、手動で作成(managedかinternal)するか、外部のディレクトリサーバ(LDAP)やActive Directory (AD)に接続することで取得します。これらのアカウントに対するアクセスの承認は、次章で説明する粗い粒度・細かい粒度のパーミッション拡張によって管理されています。
リソースに対するRBACとアクセス管理
UCPは機能性の高いロールベースのアクセス管理機能を提供し、エンタープライズ系のID管理ツールとセキュリティ要件との連携・統合が容易にできるよう設計しています。UCPは粗い粒度と細かい粒度の両方のセキュリティアクセス制御を管理できると共に、単一のUCPクラスタ上でマルチテナント化したリソースグループをコレクションとして一括管理することもできます。
UCPにおけるアクセス許可はこれらのリソースを対象に、ロールをSubject (対象)に提供することによって行います。アクセス許可の内容は、システム内でユーザが何をできて、何をできないかを定義したものです。
UCPでのデフォルトのロールとして次のものがあります: None(権限なし)、View Only(閲覧のみ)、Restricted Control(制限つきコントロール)、Schedulerスケジューリング許可)、Full Control(完全なコントロール)
これらのロールに関する内容の説明と、お互いにどのような関係にあるかについてはリファレンスアーキテクチャの Docker EEのセキュリティとベストプラクティス に記載しています。それぞれのロールは、ロールに関連付けられたパーミッションを定義する処理セットを持っています。独自のパーミッションセットを組み合わせることで、追加のカスタムロールを定義することもできます。カスタムロールはそれぞれの組織やセキュリティ制御が要求する、粒度の高いアクセス制御に適応するために利用することができます。
Subjectは個人ユーザか、オーガニゼーションに属するチームです。通常、チームはLDAP/ADグループや検索フィルタで既定します。ユーザを手動で追加することも可能です。ただし、ハイブリッドのユーザ構成は不可能です。言い方を変えると、チーム内のユーザリストはディレクトリサーバ(ADなど)から導入するか、手動で構築するかのいずれかで、共存できません。
コレクションとは、UCP内のオブジェクトのグループです。コレクションは、1つまたは複数のノード、スタック、コンテナ、サービス、ボリューム、ネットワーク、シークレット、コンフィグで構成できます。また他のコレクションを保持することも可能です。ノードあるいはスタック、または任意のリソースをコレクションに関連付けるには、そのリソースがコレクションとラベルcom.docker.ucp.access.labelを共有する必要があります。リソースは、ゼロまたは複数のコレクションに関連付けることができ、コレクションにはゼロあるいは複数のリソース、または他の子コレクションを含めることができます。コレクション内のコレクションは、リソースオブジェクトを階層的に持つことができ、アクセス管理をかなり単純化することができます。階層の最上位にあるコレクションへのアクセス権限は、下位の層のすべてのコレクション(子コレクションを含む)も継承します。
このアプローチの非常に単純なユースケースを考えてみましょう。Prodという最上位のコレクションと、Prod内に各アプリケーションに対応する追加の子コレクションを定義するとします。これらの子コレクションには、スタック、サービス、コンテナ、ボリューム、ネットワーク、シークレットなど、アプリケーションが利用するリソースオブジェクトを含みます。IT運用チームのすべてのメンバーが、すべてのProdコレクションのリソースにアクセスする必要があるとします。この設定では、アプリケーションの数が多い場合でも(話を広げて、Prodコレクションに子コレクションがあっても)、UCP内のIT運用チームにはProdコレクションに対してのみFull Controlのアクセス権限を与えることができます。このアクセス権限はProdコレクション内に含まれるすべてのコレクションも継承します。同時に、特定のアプリケーション開発チームのメンバーに対して、特定のアプリケーションのコレクションにのみアクセス権限を提供することもできます。このモデルは、各チームには特定のリソースのコレクションに対するロールを割り当てるという、従来のロールベースのアクセス制御(RBAC)を実装しています。
認証管理 (Managed)
認証・認可のManagedモードは、Docker EE StandardおよびAdvancedのデフォルトモードです。このモードでは、アカウントはDocker EE APIを使用して直接作成します。ユーザアカウントは、UCP UIの User Management → Users → Create User のフォームで作成できます。またアカウントは、eNZiと呼ばれる認証・認可のRESTfulサービスへHTTPリクエストを行うことによって、自動的に作成・管理することもできます。
「Managed」モードを使用したユーザ管理は、デモ目的またはDocker EEにアクセスするユーザが非常に少ない場合のみで推奨します。
長所:
- セットアップが簡単で早い
- トラブルシューティングが容易
- 静的なロールを持つ少数のユーザ群に適切
- UCPインターフェイスだけで管理可能
短所:
- ユーザ数が多い場合や、複数のアプリケーションでロールを管理する必要がある場合にユーザアカウント管理が煩雑
- ユーザのパーミッション追加・削除などライフサイクルのすべての変更作業は、ユーザごとに手動で行う必要がある
- ユーザは手動で削除する必要があるため、アクセス権限の変更に手間がかかり、システムの安全性を損ねるおそれがある
- LDAPや外部システムによる統合アプリの作成/デプロイの高度な設定ができない
LDAP / AD 統合
ユーザアクセス管理のために、LDAP方式によるユーザ認証機能を有効にすることができます。名前が示す通り、このモードでは、Active DirectoryやOpenLDAPなどの外部ディレクトリサーバからのユーザアカウントの自動同期を有効にします。
この方法は、大量のユーザを持ち、認証/認可を集中管理するIDストアで運用する組織である、エンタープライズ企業にとって特に受け入れやすいユースケースでしょう。これらの企業の多くは、MicrosoftのActive Directoryなどのディレクトリサーバや、LDAPをサポートするシステムを採用しているはずです。さらにそのような企業では、社員の入社・退社、ライフサイクル管理のための成熟した手順をすでに持っているはずです。これらすべての仕組みを、Docker EEのアクセス制御のプロセスでシームレスかつ効率的に活用することができます。
長所:
- すでに確立しているアクセス制御の手順を利用して、権限を付与および取り消す機能
- LDAPに基づく集中管理されたシステムから、ユーザとパーミッションを管理し続ける機能
- LDAPから削除したユーザが次回の同期時にDocker EEからも自動的に削除することでセキュリティを向上するセルフクリーニング機能
- フラットファイルのような上流システム、LDAPプロキシを使用するデータベーステーブル、AD/LDAPグループによるアクセスの自動的な時間ベースのプロビジョニング解除機能など、複雑な設定を行う機能
短所:
- Managedモードに比べて複雑さが増加
- 外部システム(LDAP)に関する知識が必要なため、管理者に要求する知識がより高度
- 追加のコンポーネント(LDAP)が加わる分だけ、問題解決に必要な時間が増大
- 上位のLDAP/ADシステムでの変更が、Docker EEにも変更を与える結果となり、予期せぬ影響を及ぼす可能性
お勧めのベストプラクティスは、リソースへのユーザアカウントのアクセスを制御するために、グループメンバーシップを使用することです。理想的には、そのようなグループメンバーシップの管理は、集中型のID管理またはRBACシステムによって実現できます。これにより、集中管理型の外部のディレクトリサーバを通して、Docker EE内の認証・認可ルールを標準的で柔軟でスケーラブルなモデルとして提供します。このID管理システムを通して、ディレクトリサーバはユーザの登録および削除、そして役割と責任の変更を同期した状態に保ちます。
Docker EEの認証モードを変更するには、UCP UIから admin → Admin Settings → Authentication & Authorization のフォームにアクセスし、 LDAP ENABLEDフィールドをYesに切り替えます。
ディレクトリサーバから検出してDocker EEに同期するアカウントには、固有のプライベートコレクションにデフォルトパーミッションを自動的に割り当てます。非プライベートコレクションにアクセス許可を追加で割り当てるには、必要なロールを割り当てた適切なチームに、ユーザを追加する必要があります。
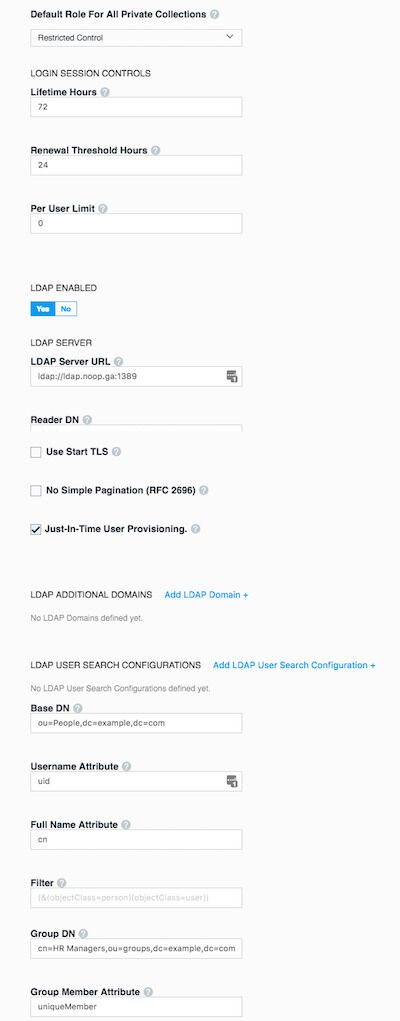
認証設定 - LDAP
LDAP設定オプションの詳細については、 LDAP統合 のドキュメントを参照してください。
次のリストはLDAP認証を設定する際に、考慮すべき重要な構成オプションを示します:
- LDAP認証モードでは、アカウントを検出したとき、そのユーザがシステムにログインするまでUCP内にアカウントを作成しないことがあります。これは、LDAP設定の Just-In-Time User Provisioning によって制御しています。この設定を有効にすることをお勧めします。
- ディレクトリサーバからアカウントを検出してインポートするためのユーザアカウントを、ディレクトリサーバ上に設定する必要があります。このユーザアカウントの権限は、強力である必要はありません。実際、必要なorganizationalUnits (ou)を表示してグループメンバーシップを照会することができる読み取り専用アカウントとすることを推奨します。このアカウントの詳細は Reader DN および Reader Password フィールドで設定します。 Reader DN はdistinguishedName形式である必要があります。
- 可能であれば、セキュアLDAPを使用してください。
- LDAP認証に切り替える前に、LDAP設定の LDAP TEST LOGIN を使用して接続可能であることを確認します。
- このフォームに入力したテスト接続が成功すると、同期ボタンは次の間隔を待たずに、すぐに同期を実行するオプションを提供します。このオプションを選択すると、LDAP接続を実行し、ユーザをインポートするためのフィルタを実行します。
- 設定が完了し保存されると、同期条件に一致する有効なLDAP/ADアカウントを使用してログインすることが可能になります。サポートするログイン属性は、uidとsAMAccountNameのみです。Docker EE内でログインが成功するには、LDAP/ADシステム内のアカウントが正常である必要があります。
- 同期の進行状況と発生したエラーは、コントローラノード上で次のコマンドを実行することで表示および分析が可能です: docker logs ucp-controller
オーガニゼーションとチーム
Docker EEに存在する、LDAP同期またはマニュアルのいずれかの方法で作成したユーザアカウントは、チームに編成できます。チームは、オーガニゼーションに含める必要があります。作成した各チームには、チームメンバーが関係するコレクションに対して操作を行うことを許可するロールが与えられます。
チームを作成するには、最初にオーガニゼーションを作成する必要があります。オーガニゼーションは、 User Management → Organizations & Teams → Create Organization で作成できます。
enterprise-applications というオーガニゼーションを作成する例を考えてみましょう:
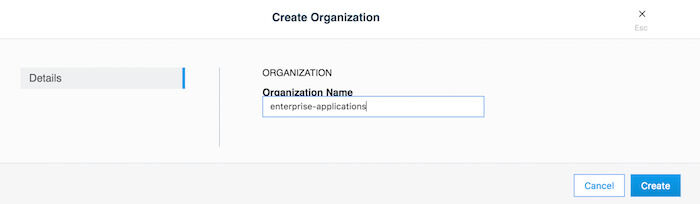
オーガニゼーションの作成
チームは、UCP UIでオーガニゼーションををクリックし、 Create Team をクリックすることで作成できます。後で説明するeNZi APIを使用しても同じことを達成できます。メンバーはチームに1人ずつ追加することができます。LDAP認証モードを使用している場合は、チームにメンバーを追加する別の方法があります。LDAP認証モードを有効に設定することで、ディレクトリサーバから検出したアカウントを自動同期する方法です。より細かいフィルタを適用して、検出したアカウントをどのチームに配置するかを決定することができます。チームは複数のユーザを持つことができ、ユーザはゼロから複数のチームのメンバーになることができます。次はenterprise-applicationsオーガニゼーション内にDev TeamとOps Team作成する例です。
まずオーガニゼーションを作成します:
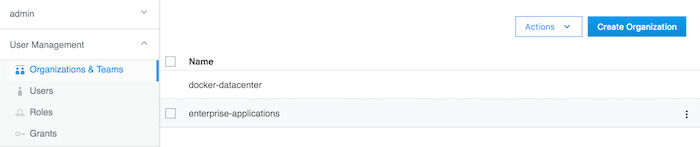
オーガニゼーションの作成
オーガニゼーションを作成すると、その内部にDev Teamを作成することができます:
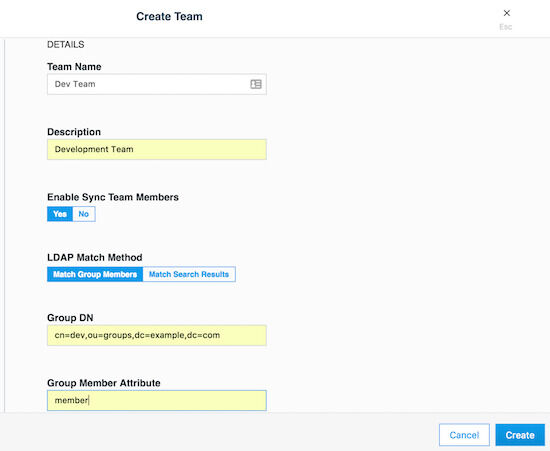
Dev Teamの作成
その後、Ops Teamも作成できます:
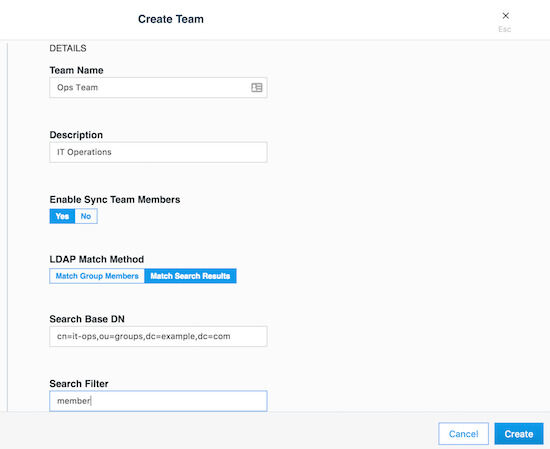
Ops Teamの作成
コレクション
コレクションは先に説明したように、リソースのセットを任意にグループ化するために使用できる論理的な構造です。コレクションを作成するには、 Collections → Create Collectionのフォームを使用します。次はproductionというコレクションを作成する例です。
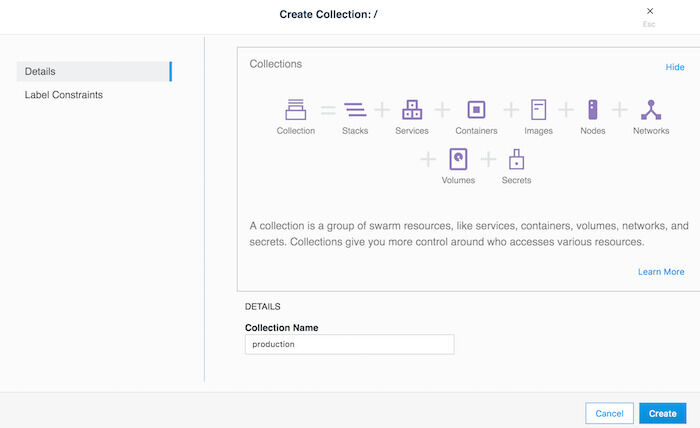
productionコレクションの作成
この例でのproductionコレクションは、他のアプリケーションのコレクションを保持するためだけに使用します。そのようなコレクションの1つとして、請求アプリケーション (Billing Application)をproductionコレクション内に作成します。 Collections → production → View Children → Create Collection とクリックしていきます。
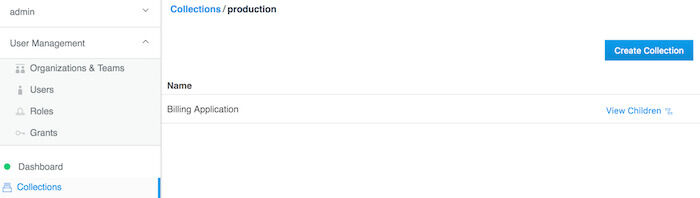
billingコレクションの作成
この時点で、コレクション内の機能に基づいて、チームにロールを割り当てるためのアクセス権を作成することができます。
このことは次にあげる具体的な例で、より簡単に理解できるでしょう:
wwwと呼ばれる、nginxの公式イメージに基づいたWebサーバというシンプルなアプリケーションがあるとします。また、このwwwアプリが、本番環境にデプロイした請求アプリケーション (Billing Application) の1つであるとします。このアプリケーションにアクセスする必要があるのは次の3つのチームです:
- developers
- testers
- operations
一般的にtesters(テストチーム)は View Onlyのアクセスしか必要としません。一方で、operations(運用チーム)は環境の管理と維持のためにFull Controlが必要です。developers(開発チーム)は、アプリケーションのライフサイクルのうち、トラブルシューティング、再起動、および制御のためのアクセスが必要です。ただし、ホスト側のファイルシステムへのアクセスを必要とする処理や特権付きコンテナの起動は禁止すべきです。このような特別なアクセス権限をRestricted Control(制限付きコントロール)と呼びます。
アクセス権の付与
アクセス権の付与は、UCP の User Management → Grants → Create Grant からウィザードを使用して作成することができます。 Swarmコレクションはすべてのコレクションの最上位です。View Children をクリックすると、すべてのサブコレクションを表示します。productionコレクションは、その内の一つになります。productionコレクションに対応する View Children をクリックして、Billing Applicationのコレクションにアクセスします。Select Collectionをクリックして詮索します。画面は次のようになります:
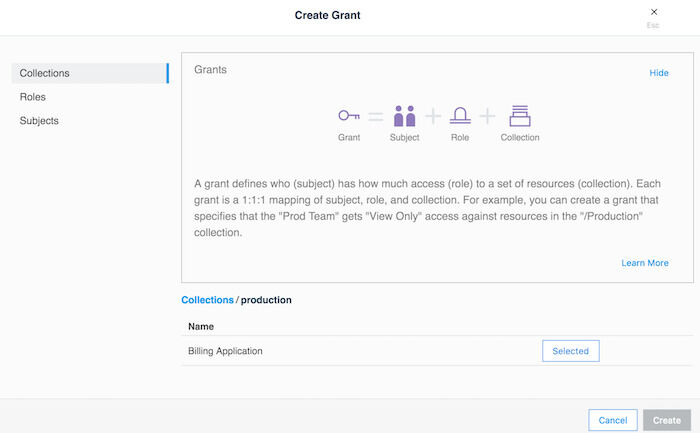
コレクションの選択
この章では、「最小権限・最小パーミッション」と「責任の分割」の原則に従った典型的なユースケースを示しています。これは前章で説明したアプリケーション例であるwwwのアクセス要件に対処することを目的としています。
引き続き Create Grant インターフェイスで、 Roles をクリックします。ドロップダウンリストから Restricted Control ロールを選択します。次に Subjects をクリックします。 Organizations を選択し、 Organization ドロップダウンリストからenterprise-applicationsを選択します。そして Team ドロップダウンからDev Teamを選択します。最後に Create をクリックします。
その後、productionコレクションのみを選択し、Full Controlロールを選択し、サブジェクトとしてOps Teamを選択する以外は、同じ手順を繰り返して別の権限を作成します。
さらに、Billing Applicationコレクションのみを選択し、View Onlyロールを選択し、サブジェクトとしてTest Teamを選択する以外は、同じ手順を繰り返して別の権限を作成します。
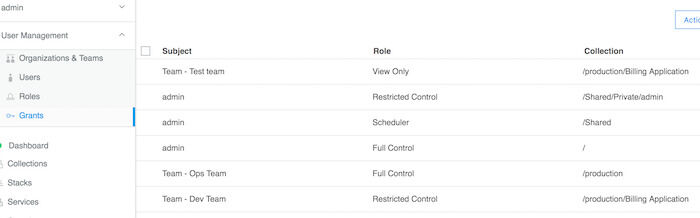
権限付与の作成
この権限付与の設定により、各チームはBilling Applicationsコレクション内の任意のアプリケーションに対して、その機能に基づく適切なレベルのアクセス権を取得します。
wwwアプリケーションとBilling Applicationsコレクションを関連付けるには、次のようにサービスを作成する前にコレクションを選択する以外は、通常の方法でサービスを作成します:
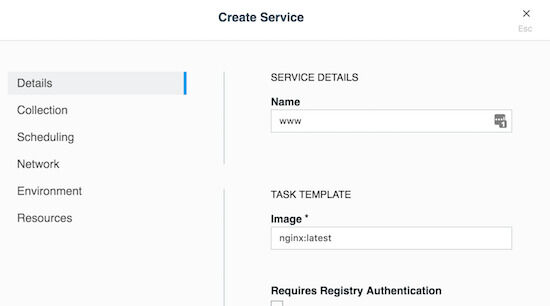
wwwサービスの作成
コレクションを選択します:
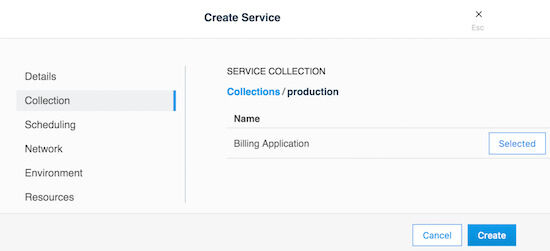
サービスのコレクションを選択
LDAPフィルタを使用する際の戦略
UCPへのアクセスを必要とするユーザはすべて、企業のディレクトリサーバシステムから供給するとします。これらのユーザは、Docker EEインフラストラクチャを管理する必要がある管理者ユーザと、UCP内に構成した各チームのすべてのメンバーになります。また、Docker EEへのアクセスを必要とするユーザ(管理者、開発者、テスター、運用者を含む)の総数は、ディレクトリサーバ内のユーザ全体のサブセットであると仮定します。
ユーザを組織する際にお勧めの戦略は、まず所属チームに関わらず、Docker EEの全ユーザを識別するための重要なメンバーシップグループを作成することです。このグループをDocker_Usersと呼びましょう。ユーザはこのグループのメンバーとして直接参加してはいけません。その代わり、Docker_Usersグループは他のグループのみをメンバーとして含みます。ここでは、これらのグループをdev、test、およびopsとしましょう。この例では、これらのグループは、ディレクトリサーバ内の 入れ子グループ 構造の一部です。入れ子グループによって、上位グループから下位サブグループへのアクセス権の継承を行います。
注: 一部のディレクトリサーバは、デフォルトの設定で入れ子グループの機能やmemberOf属性をサポートしていません。そうであれば、有効にする必要があります。お使いのディレクトリサーバがこれらの機能をまったくサポートしていない場合は、ユーザーを編成して照会する代替手段を使用する必要があります。Microsoft Active Directoryは、これらの2つの機能をサポートしています。
ユーザアカウントは、ディレクトリサーバのサブグループのメンバーとして追加する必要があります。これは、組織単位内の既存のレイアウトや、これらのユーザの既存のグループメンバーシップには影響を与えてはいけません。サブグループは、チームの定義における Group DN の値として使用する必要があります。
最後に、任意のユーザアカウントのすべてのアクセスを停止する必要が生じた場合、Docker_Usersグループに所属するグループメンバーシップからそのユーザアカウントを削除すると、そのユーザのすべてのアクセスが無効になります。入れ子グループの性質上、Docker内のすべての追加アクセスが自動的に無効となります。つまり、手動操作や追加手順を必要とせずに、次回の同期時にすべてのチームメンバーシップからユーザアカウントが無効になります。このステップは企業のID管理システム内の、標準的な入社・退社の自動プロビジョニング手順に統合することができます。
認証API (eNZi)
AuthN APIまたはeNZi (「エンズィ」と発音)は、Docker EEの集中的な認証・認可サービスとフレームワークです。このAPIはDocker EEに完全に統合・設定しているので、UCPだけでなくDTRともシームレスに動作します。これはアカウント、チームとオーガニゼーション、ユーザセッション、アパーミッション、ラベルによるアクセス制御、OpenID Connectによるシングルサインオン(Web SSO)、そして外部のLDAPベースのシステムから、Docker EEにアカウント詳細を同期する機能などを管理するコンポーネントとサービスです。
通常の日常的な作業では、ユーザとオペレーターはAuthN APIとその機能について意識する必要はありません。ただし、その機能を活用して多くの一般的な機能を自動化したり、UCP UIを完全にバイパスしてデータを直接管理したり操作したりすることができます。
RESTFul AuthN APIエンドポイントに関する情報は、 AuthN API ドキュメントをご覧ください。
AuthNへのアクセスは、HTTP経由で公開されたRESTful AuthN APIか、enziコマンドによる2つの方法で実行できます。
例えば次のコマンドは、curlとjqを使用して、Docker EEのすべてのユーザアカウントをHTTP経由のAuthN APIで取得します:
$ curl --silent --insecure --header "Authorization: Bearer $(curl --silent --insecure \
--data '{"username":"管理者のユーザ名","password":"管理者のパスワード"}' \
https://UCPのドメイン名/auth/login | jq --raw-output .auth_token)" \
https://UCPのドメイン名/enzi/v0/accounts | jq .
AuthNサービスは、UCPコントローラノード上のCLIで呼び出すこともできます。接続するには、UCPコントローラノードで次のコマンドを実行します:
$ docker exec -it ucp-auth-api sh
実行後のプロンプト(#)で、次のようにenziサブコマンドを入力して、データベーステーブルの状態を表示します:
enzi db-status
注: 詳細な例については、 Docker EE StandardおよびAdvancedの管理パスワードの回復 を参照してください。






