
12/9(水) Spark Meetup Decemberイベントレポート
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
![]()
クリエーションラインの藤田です。12月9日に都内某所で行なわれたSpark Meetup December( http://connpass.com/event/23159/ )に参加してきました。
私はスタッフとしてエレベータの乗り換え階にて参加者の誘導を行なっていました。参加者が次々に来場し、会場が賑やかになっていきます。ちょっとしたハプニングにより予定を10分ほどオーバーしましたが、Spark Meetup Decemberが始まりました。

-
Spark Wrapup: 2014-2015
最初にクリエーションライン木内さん、鈴木さんよりSpark Analytics 2015、Spark Summit EUの報告がありました。これまでもSparkには様々な機能が追加されてきましたが、2016年も勢いは衰えなさそうです。
本当にあったApache Spark障害の話
つづいてサイバーエージェントの井上さんから「本当にあったApache Spark障害の話」の発表です。内容はSparkのトラブルシューティングに関するものでした。1年近くSparkを使って実際に起った障害を話してくださいました。Sparkのバージョンを1.4.0から1.5.1に上げた際にジョブがfailした件やexecutorが応答しなくなり、ジョブが完了できずメモリが足りなくなった件など、自分達がどう対処したのかを説明してくれました。前者はSQLContextをHiveContextに変更することで解決し、後者はspark.speculationの設定で遅延タスクを再起動することで解決するそうです。またscalaで開発するときに使用するsbtでのテストがfailするのはsbtバージョンが0.10以上で対応した並列実行が原因で並列実行を無効化する必要があるそうです。
障害の解決策だけでなく解決策を探る過程も話してくれて、どのような考え方をしていたのかが分かり勉強になりました。
Spark Streamingの基本とスケールする時系列データ処理
MapR Technologiesの草薙さんの発表は「Spark Streamingの基本とスケールする時系列データ処理」と題して、Sparkの基本的な事項から時系列データの簡単なユースケースの説明をしてくれました。まず時系列データの説明やそのデータを使った処理の例を上げたり、Sparkを使って分散処理することの利点(障害に強い)を話してくれました。その後にSparkのRDDやtransformationとactionの簡単な説明をし、コードを示しながらデータの取得・HBaseへの読み書き・データのフィルタ処理など丁寧に説明してくれました。最後にはMapRでできるHadoopやSparkのオンライン学習の紹介をしてくれました。

Sparkの基本的な操作からStreaming処理、HBaseの操作方法等を丁寧に発表してくれました。Sparkの初学者にも分かり易い説明だったと思います。MapRでは英語ではありますが、タダでSparkのオンライン学習ができるようでぜひ私も利用してみたいです。
Spark Streamingによるリアルタイムユーザ属性推定
5分程度の休憩を挟んで、最後にリクルートテクノロジーズの佐伯さんより「Spark Streamingによるリアルタイムユーザ属性推定」の発表です。ユーザが求める情報をマッチングし満足度を向上させるためにユーザ属性を調べます。データのない新規ユーザに対してもSpark Streamingを使うことで、リアルタイムに情報収集と属性推定が実現できるそうです。データの取得・転送からStreaming処理、処理結果の反映と製作したサービスのSpark以外の部分も説明をしてくれました。SparkにはMLlibという機械学習用のライブラリがあるのですが、要件を満たすものがなく事前に用意したモデルを使って属性推定を行なったそうです。また開発チームにはJavaが書ける人たちとScalaが書ける人たちがいたが言語間での型変換をSparkがimplicitに行なってくれたため、JavaとScalaの共存が楽だったそうです。
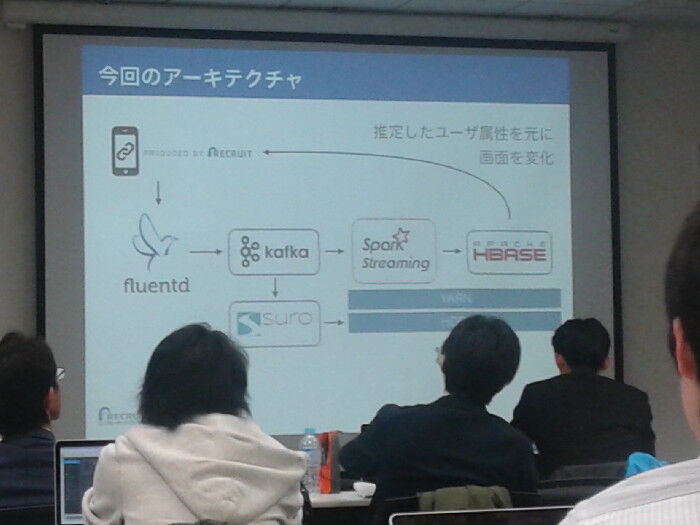
個人的にはユーザの属性推定にどのようなモデリングを使用したのか気になりましたが、公開してもらえず少々残念でした。ただ実際にサービスを提供するときにどのようにSparkを組み込んでいるかを話していただき、勉強になったと思います。
全ての発表が終わったあとには情報交換会が行なわれました。軽食を取りつつ、LTが行なわれたり、各人交流を深めあっていました。
まとめ
私もSparkを使っていますが、個別に機能を使うことが多く今回発表があったように実践的な開発をしたことが無いので大変興味深く聴かせて頂きました。またMLlib系を普段使っていてSpark Streamingには馴染みがないのですが、それでも理解できる分かり易い説明でした。IoT分野との連帯では取得したセンサー値などをStreamingで扱うことになるでしょうから、今後のために勉強をしたいです。




を試作")
