
”パナマ文書”をグラフデータベースで高速に検索する事例の勉強会に行ってきた。 #neo4j

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
世の中のジャーナリストの中には、政治家や企業が怪しげな取引を行うことで巨万の富を得ているらしいことに憤慨している人が多くいるんですね。そんな人たちの中で最近モチキリの話題はそう、「パマナ文書」です。なんでもこれまでのリークネタと比べるととてつもないぐらいに情報量が大きいんです。これまでのリークがギガバイト単位なら今回のものはテラバイトです。実際に社会に与えたインパクトも大きくてアイスランドの首相さんはこれがきっかけで辞任に追い込まれたとか。
そんな政治ネタをクリエーションラインが扱うのもどうかと思うんですが、実際にはNeo4jというグラフデータベースを使ったデータ分析の事例なんですよね、中身は。ということで日本Neo4jユーザー会主催のイベントで弊社の鈴木、李、木内が登壇しましたのでここでレポートします。
今回の勉強会はNeo4jユーザー会主催のNeo4jというグラフデータベースについての勉強会の一環で2016年5月20日に恵比寿ガーデンプレイス6階のクラウドワークスさんのラウンジをお借りして行われました。参加者は約100名程度、今回はハンドアウトも無いので皆さん何故か真剣です。
今回の最初のトークはロンドンで行われたイベントの報告から。
最初に登壇したのは弊社の鈴木いっぺいです。先日ロンドンで行われたGraphConnect Europe 2016というイベントでの発表のサマリーをプレゼンテーションしました。このイベントは、Neo4jの開発元である、NeoTechnology社が主催していて、The International Consortium of Investigative Journalists(ICIJ)というジャーナリストの団体がプレゼンターとして登壇しています。ICIJは過去にも様々なリークネタを公開して、社会的に問題がある事件をリークという形で世に問うているということでしょうか。今回のパナマ文書は電子メールや文書など様々なものを全部まとめると2.6TBになるそうで考えただけで凄そうです。
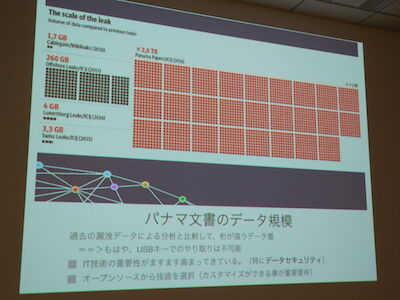
パナマ文書のデータサイズは全部で2.6TBです!
この膨大な情報量の中からデータベース化できる部分が約3百万に及ぶドキュメントで、これを整形してNeo4jに取り込んでグラフデータの検索を行うというのが今回の目標です。鈴木のプレゼンテーションで驚いたのは、このアプリケーションを作ったのはたった3人のエンジニアだったということです。十分に頭を使い、パブリッククラウドサービスを使いこなせば、少人数でも素早く開発できるし、データの量はさほど問題にならないんだな、というのが参加した私の印象です。
次に登壇したのは弊社の李です。李はインプレスから『Cypherクエリー言語の事例で学ぶグラブテータベースNeo4j』という書籍を書くほどにグラフデータベースに魅入られています。
『Cypherクエリー言語の事例で学ぶグラブテータベースNeo4j』についてはこちらを参照してください。http://www.impressrd.jp/news/151029/NP
通常のリレーションルデータベースではこれまでは実現できない領域をビジネスドメインにするNeo4jですが、その生い立ちとv2.0からv3.0になって変わった部分などを解説しました。グラフデータベースのおさらいをしておくと18世紀から続く数学理論で、これまでのリレーショナル・データベースでは難しかったモノとモノの関係を表現できるデータベースです。これをオープンソースソフトウェアとして開発してるのがNeo Technology社です。現在は、無償で使えるコミュニティ版と商用のエンタープライズ版があります。v3.0になってより進化したということでグラフデータベースではもはや唯一の存在ということらしいです。
詳しくはNeo4jのサイトを御覧ください。http://neo4j.com/

グラフデータベースのデータ処理の基本。
最後に登壇した木内は、実際にパナマ文書の中の4分の1を占めるデータベース化されていた情報をNeo4jに取り込んで検索を行うというデモを行いました。まずはパナマ文書の説明です。パナマ文書の多くの部分は非定型の電子メールです。他にもイメージファイルやテキストファイルが含まれており、その中の一部だけをグラフデータベースに取り込んだというわけです。
データベース化というのはCSVの形式で保存されているデータということになります。実際には最も多いのはメールのデータということですので、内容の分析はは人手で処理するしかなかそうですね。ということはこれからもっとスゴイ情報が出てくるのかも。
今回はこのCSVをNeo4jにロードしてグラフデータベースにしています。パナマ文書自体が公開されるまでの処理の概要は大雑把に言えば、パナマの法律事務所、Mossack Fonesca社にあったデータがハックされて流出、それをドイツの新聞社がICIJと一緒になって分析したという流れですね。それの一部がグラフデータベースになったわけです。
実際のグラフデータの概要は、役員情報に住所、仲介業社名、登記業社名、など主に4つの情報が存在しています。それを「役員が登録している住所」などのように役員と住所を「登録している」という関係性で繋ぐということをしています。元となる情報(Node)に対して辺(Relation)を設定して点と点を繋ぐことをするわけですね。それがだいたい合計200万行のCSVで定義されているものをNeo4jに入れて分析を行うわけです。
Neo4jの中ではオンメモリに主なノードとなる情報が格納され、それ以外の属性情報はHDDに格納されます。多くのデータはオンメモリですので、高速な検索が行えるわけですね。
実際にデータをNeo4jにロードするには2つの方法があります。Cypher QueryというSQLに似た言語でロードを行うと非常に時間がかかります(12日!)ので、今回はCSVを読み込むためのスクリプトを使いました。これを利用すると約30秒でロードすることができました。
ここからは木内得意のライブデモ!ということで実際にNeo4jをローカルのPCで立ち上げてデモを行います。例えば「日本という住所を持つ役員が何人いるのか?」という検索ができます。結果はグラフィカルなチャートでみることができます。赤い丸が役員、ピンクは中間会社のようにどの情報がどういう関係性で繋がれているのかがひと目でわかりますが、写真でお見せすることができないので想像してください。
実際に検索されたノードの詳細を見ることもできます。一つ一つのデータが全て関係性で繋がれていてそれをたどることで色々な分析が行えます。また全体の傾向や分類を行うことも可能です。
このデモではグラフデータベースを使うと関係性に基づいた情報を効率よく分析などに使えることをお見せしました。これまでリレーショナルデータベースでは難しかった関係性に関する情報の処理にグラフデータベースを使う有効性が見えてきたような気がします。是非皆さんの参考になればと思います。
実際にNeo4jのユーザーインターフェースはとても使いやすいので別の機会に是非、実際のデモをご紹介したいと思います。






