
MongoDB Ops Managerのバックアップ&リストア #mongodb
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
MongoDBのOSS版もクラスタ―の構築・運用はできますが、大容量のデータベースのバックアップの運用は、MongoDB EA(有償版)しか対応できません。数百GBを超えるデータサイズを想像してみてください。mongodumpやexport、ファイルコピーなどのような方法では恐ろしく時間が掛かり、通常のバックアップウィンドウに収まりません。
MongoDB Ops Managerのバックアップは、クラスタ―との間で初期同期を一度を実行してから、継続的に差分を収集し、分刻みで同期を取っておきます。万が一、事故が起きた場合、日時分まで指定してポイントインリカバリが実行できます。今回は、MongoDB Ops Managerのオプションの一つであるバックアップ&リストアの実行方法をご紹介します。
[MongoDB Ops Managerとは]
MongoDB Enterprise Advanced(EA、有償版)の管理ツールであり、クラスタ―のプロビジョニング、監視、バックアップ&リストア、既存クラスタ―のリーバースなどがすべてGUIで実行できます。
Ops Managerのパックアッププロセス
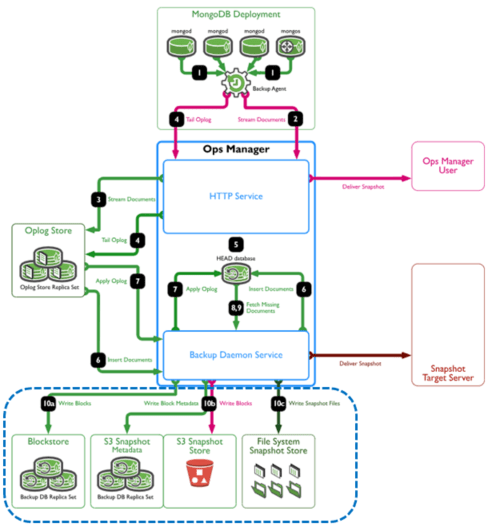
Ops Managerによるバックアッププロセスのフローは、次の図の通りです。ぞれぞれの構成要素や役割を理解することは、バックアップの構成設計やハードウェアの構成のためにとても重要です。Ops Managerでの設定作業自体は、ウィザードに従って簡単に実行できます。

バックアップエージェント
- バックアップエージェントは、クラスタ―のすべてのノードにインストールします。
- クラスタ―のバックアップエージェントは、10MB単位でOplogのスライス(増分データ)をOps Manager側(HTTP Service)に送り続けます。
- プライマリか、セカンダリのとちらかでOplogを取得するかは、バックアップ環境の設定に従います。
- 初期同期は、プライマリから取得し、HEAD databaseを経由でバックアップ媒体に初期スナップショットを取ります。
Oplog Store(MongoDB)
- Ops ManagerのHTTP Serviceは、クラスタ―からのOplogを受け取ってOplog Storeに蓄積します。
- Oplog Storeの実態はMongoDBです。
- Oplog Storeの正確なサイジングは困難ですが、大雑把に言うと「(1日のOplogの増加サイズの平均✖何日前までに遡ってポイントインリカバリを行うかの想定日数)+運用バッファを考慮したスペース」になります。
- Oplog Storeをクラスタ―にすべきかどうかよく聞かれます。MongoDBのクラスタ―構築・運用経験がない場合、運用ツールのために手作業でクラスタ―を構築するとは、残酷な話です。バックアップ構成が壊れてもクラスタ―にはまったく影響ないし、Ops Manager側の設定を削除し再構築できます。オンサイトの内規とか縛りが無ければ、とりあえずスタンドアロンで検討してみてはいかがでしょうか。
- Oplog StoreのためのMongoDBのサブスクリプション購入は必要ありません。
HEAD database
- Backup Daemon Serviceは、Oplog StoreのOplog(差分データ)でHEAD databaseに整合性の取れた完全なデータセット(MongoDB)を再現します。
- Backup Daemon Serviceは、バックアップスケジュールに従ってHEAD databaseからスナップショットを取ってバックアップ先に保存します。
- HEAD databaseは、Backup Daemon Serviceが管理しているので、MongoDBプロセスを気にする必要はなく、データベースファイルを格納するディレクトリを指定するだけで良いです。
- HEAD databaseは、MongoDBのクラスタ―のデータサイズとほぼ同等なサイズのストレージが必要です。圧縮方式がSnappyなので圧縮効果はあまり期待できません。
Backup Daemon Service
- HEAD database生成管理し、スケジュールに従ってスナップショットを実行します。
- リストアやポイントインリカバリを実行します。
Ops Managerのバックアップ方式
Ops Managerのバックアップ方式は、スナップショットを格納する媒体の違いで3種類提供されています。バックアップ方式によって、ハードウェアの構成が大きく異なります。
-
MongoDBに格納する方式(Blockstore)
データベースのスナップショットをMongoDBに保存するタイプです。この方式を運用するためには、スタンドアロンのMongoDBか、クラスタ―が必要です。 -
Amazon S3に格納する方式(S3 Snapshot)
データベースのスナップショットをS3に保存する方式です。 -
ストレージに格納する方式(File System Snapshot Store)
データベースのスナップショットをSAN、NASなどのストレージに格納する方式です。
バックアップ運用のためには、相応するハードウェアが構成されている必要があります。下記のリンクを参照してください。
バックアップ設定の事前準備
今回は、データベースのスナップショットをストレージに格納する方式をベースにしてバックアップ設定を説明します。この方式は、構成がシンプルというメリットがあります。なお、ここではOps Manager全体を1台のサーバーに構成しています。
Oplog Store作成
クラスタ―の差分データ(Oplog)を集めて保存するためのMongoDBです。ここでは、ポート番号を27018にし、Ops Managerのレポジトリーデータベースとは競合しないようにしています。この作業は、Ops Managerのサーバー又は、Oplog Store(MongoDB)を運用するサーバーにログインして作業を行います。Oplog Storeはサイズの見積が正確にできないので、本番ではストレージの割り当てに注意してください。
$ sudo mkdir -p /data/backupdb
$ sudo chown mongod. /data/backupdb$ sudo su -
# sudo -u mongod mongod --bind_ip 10.0.0.4 --port 27018 --dbpath /data/backupdb --logpath /data/backupdb/mongodb.log --wiredTigerCacheSizeGB 1 --fork# mongo 10.0.0.4 --port 27018
> use admin
switched to db admin
> db
admin
> db.createUser(
{
user:"root",
pwd:"password",
roles: ["root"]
}
)
> db.auth('root','password)
1
> exit;
ユーザIDとパスワードは、Oplog Storeの設定で必要になります。控えておいてください。
では、MongoDBプロセスを起動します。
# sudo -u mongod mongod --port 27018 --dbpath /data/backupdb --logpath /data/backupdb/mongodb.log --wiredTigerCacheSizeGB 1 --fork --auth
HEAD databaseのディレクトリ作成
HEAD databaseを格納するディレクトリを作成します。本番運用では、クラスタ―のデータサイズに相応するストレージをマウントする必要があります。
$ sudo mkdir -p /backup/hddir
$ sudo chown mongodb-mms. /backup/hddir
File System Snapshot Storeのディレクトリ作成
今回は、データベーススナップショット(バックアップ)をストレージに格納する方式です。スナップショットを保存するディレクトリを作成します。本番運用では、保存するスナップショットの数に比例するサイズのストレージをマウントする必要があります。
$ sudo mkdir -p /backup/snapshot
$ sudo chown mongodb-mms. /backup/snapshot
バックアップ環境設定
スタート
バックアップ設定対象のプロジェクトを選択し、バックアップ設定を開始します。
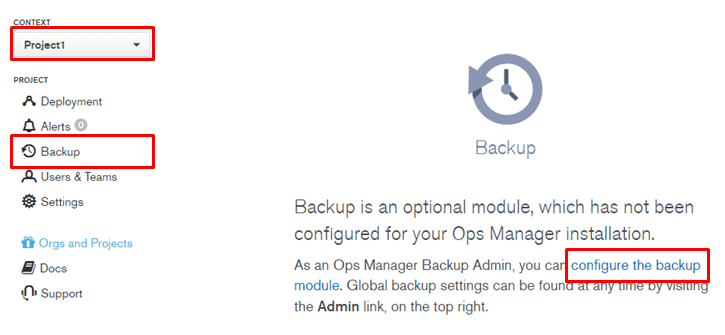
HEAD databaseのディレクトリ設定
HEAD databaseを格納するディレクトリ(ストレージ)とバックアップデーモンのマッピングを行います。事前準備しておいたディレクトリを入力します。
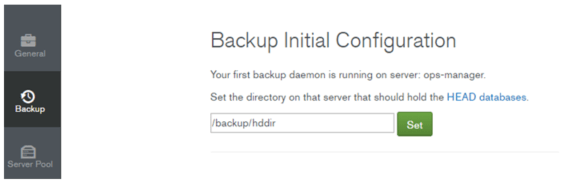
HEAD databaseのディレクトリと権限が正しければ、Enable Daemonをクリックし、バックアップデーモンの設定を継続します。
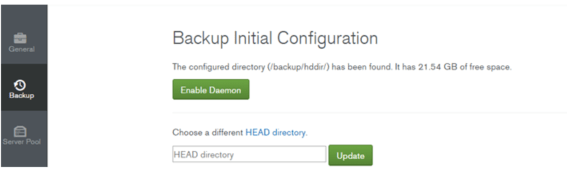
バックアップ環境の初期化
バックアップ方式を選択します。
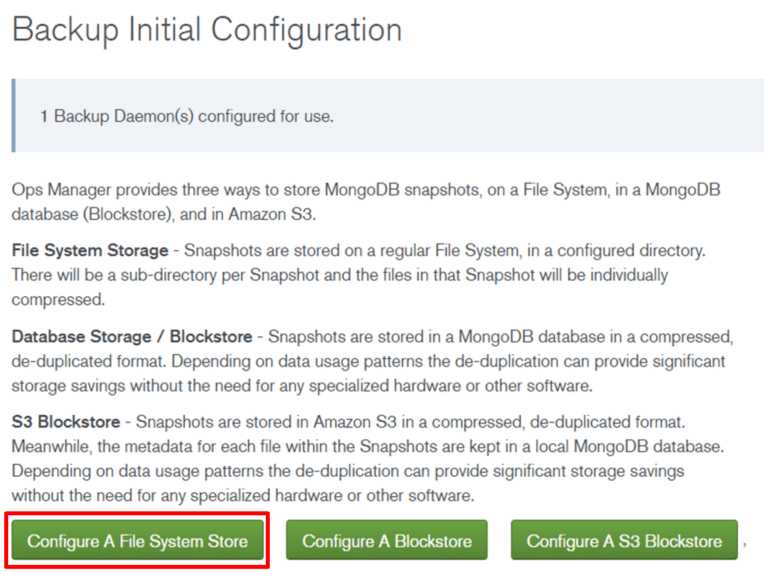
File System Storeとして事前準備しておいたディレクトリを入力します。
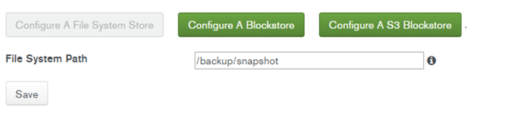
クラスタ―のOplogを一時的に保管する集めるバックアップDBを設定する。事前準備で用意しておいたOplog Store(MongoDB)の接続情報を設定します。Saveボタンを押すと、接続テストが行われます。
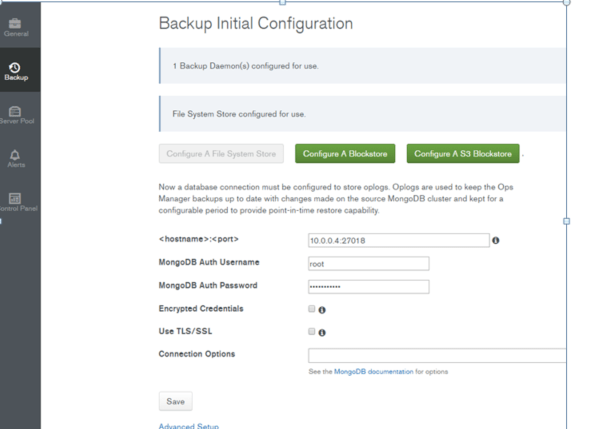
一連の設定が正しければ、バックアップ環境が揃っている旨のメッセージが表示されます。これで環境は揃いました。
バックアップオプションの設定
スタート
再び、バックアップメニューを表示します。バックアップのジョブ一覧が表示されているはずです。オプション(…)をクリックし、バックアップ設定を継続します。
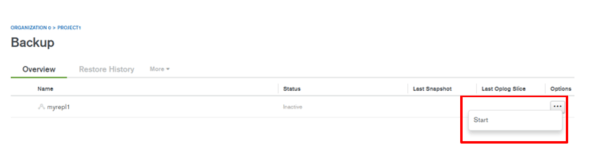
ここでは、Oplogをプライマリから取るか、セカンダリから取るかを設定します。特別な理由がなければ、セカンダリでいいです。
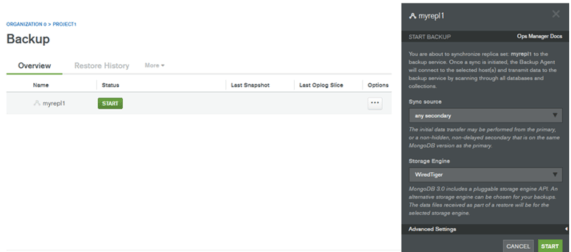
初期同期の開始
初めてのバックアップジョブ設定の直後では、クラスタ―から既存のデータをすべて持ってくる作業が自動的に始まります。
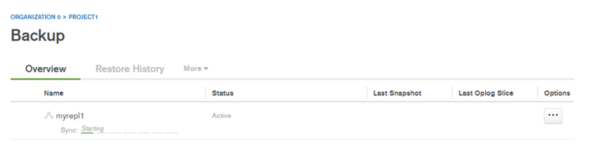
初期同期の完了すると、同期時刻が表示されます。この画面からはOplogの同期時刻も確認できます。
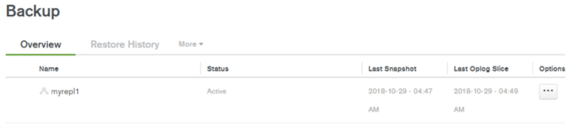
バックアップスケジュールの設定
最後にスナップショットの間隔、スナップショットの保存期間、ポイントインリカバリは何日まで遡りたいのかの日数、バックアップウィンドウ(バックアップを行うタイミング)などを設定します。バックアップジョブ一覧のオプション(…)をクリックし、バックアップスケジュール編集(Edit Snapshot Schedule)を選んでください。
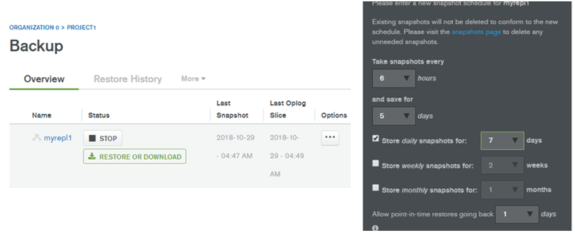
- スナップショットの間隔は、6h,8h,12h,24hの4パターンです (Take snapshot every)。
- デフォルトの保存期間は、2-5日です(and save for)。保存期間が過ぎたスナップショットは、問答無用で削除されます。スナップショットの保存期間は、365日間まで伸ばすことができます。
- スナップショットは常にフルバックアップに相当します。ストレージの消費は、スナップショットの数に比例して増加することに注意してください。
- ポイントインリカバリを実行するための差分データは、Oplog Storeに保存しています。ポイントインリカバリの有効日数を長くすると、Oplog Storeのサイズが膨張します。当初の見積サイズを超えないように注意してください。
さらに詳しいことは、次のリンクを参照してください。
Snapshot Frequency and Retention Policy
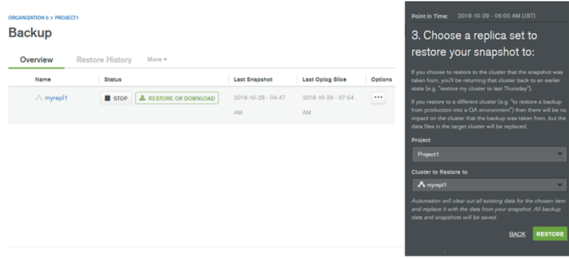
リストア
リストアの開始は、オプション(…)のRestoreをクリックしてください。
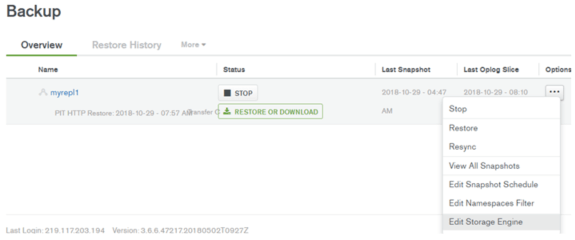
ポイントインタイムリカバリの場合、日付と、時間、分を設定して実行します。
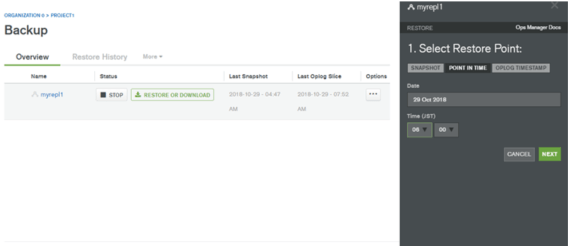
DOWNLOADとは
スナップショットをクラスタ―にリストアする代わりにスナップショットを任意の場所にダウンロードできます。ダウンロードされるファイルの中身は、MongoDBのデータベースファイルです。適切に配置してMongoDBのプロセスを起動すると、そのままデータベースとして使用できます。この機能の用途は様々です。本番データでテストを行ったり、特定のコレクションだけを入れ替えると言った用途に利用することができると思います。
リストアを実行する場合はリストアするクラスタ―を選択します(CHOOSE CLUSTER TO RESTORE TO)
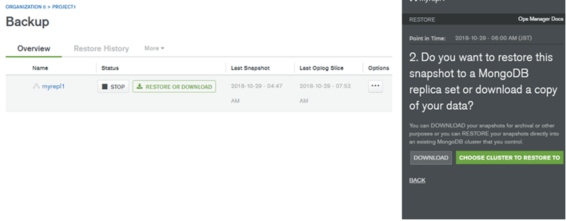
リストア(RESTORE)をクリックすると、リストアが実行されます。
まとめ
3台のレプリケーション構成なのにさらにバックアップが必要なのかという突っ込みがあるかも知れませんが、プライマリに間違ったデータを投入した場合、レプリカも一瞬にして汚染されてしまいます。このように、なにかしらの理由でバックアップ運用が必要になった場合、Ops Managerは最良の選択です。一旦、Ops Managerを導入してからだと、クラスターの構築やバックアップの設定は、簡単に実装できます。さらに見事に働いてくれます。とは言え、マニュアルを片手にバックアップ設定をしようとすると、予備知識があってもかなり苦戦します。この記事では筆者の経験から地雷的なポイントはすべて除去したつもりです。これからMongoDB EAの導入検討をなさっている方や、バックアップ運用を検討なさっている方に役に立てば幸いです。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)






