


MongoDB Enterprise Advanced
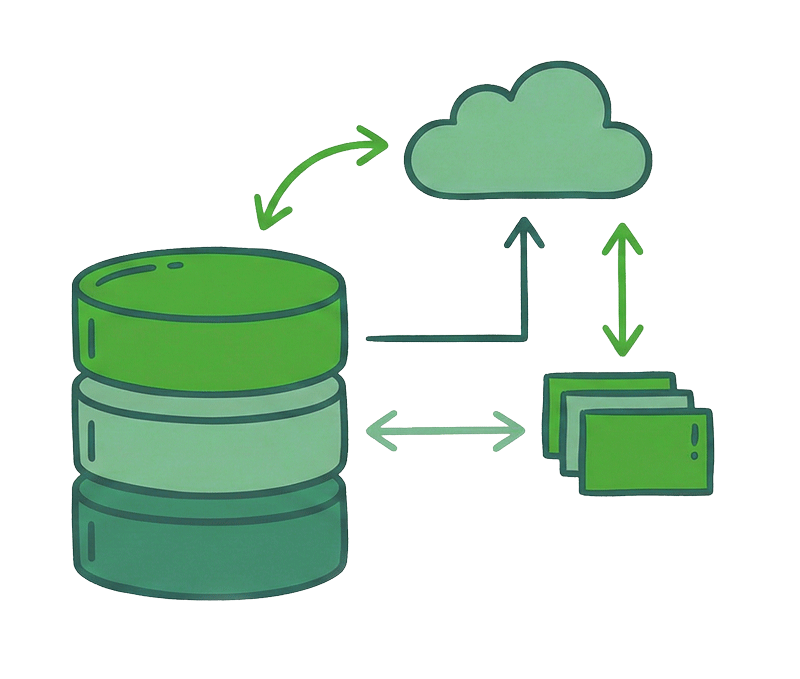
MongoDB Enterprise Advanced は、本番アプリケーション向けのモダンなデータベースを実行するための最も柔軟な方法です。
MongoDB Enterprise Advanced サブスクリプションには、MongoDB Enterprise Server の商用ライセンスが含まれています。MongoDB Enterprise Server は、MongoDB Community Edition には含まれていないいくつかの機能を提供します。これには、セルフマネージド型デプロイメント向けのインメモリ・ストレージエンジン、セルフマネージド型デプロイメントの監査機能、およびセルフマネージド型デプロイメントでの Kerberos 認証が含まれます。

ドキュメントモデルでイノベーションを加速
MongoDB は、その直感的なドキュメントモデルにより、データ管理を簡素化し、データをシンプルなドキュメントに統合します。これにより、複雑さが解消され、ダウンタイムが削減され、開発者はデータモデルを迅速に適応させる能力を得ます。その結果、イノベーションの加速と生産性の向上が推進されます。
運用の可視性と制御
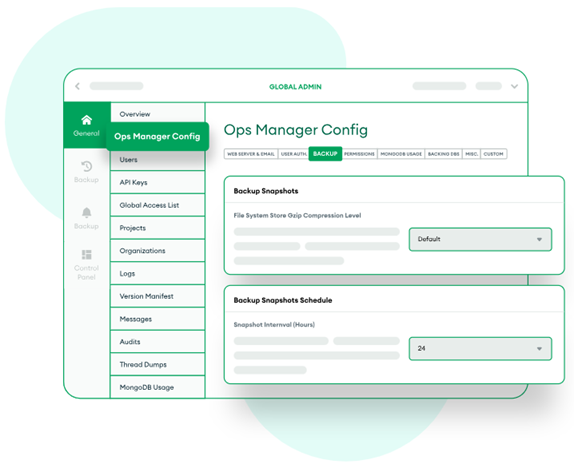
管理タスクを自動化し、データベースのパフォーマンスを常に把握できます。MongoDBのOpsManager(データベース管理ツール)は、デプロイメントの実行をシンプルにします。

データとビジネスの保護
高度なアクセス制御とデータセキュリティ機能がお客様のデータベースを保護し、コンプライアンスや顧客の要件を満たすのに役立ちます。MongoDBは、既存のセキュリティインフラストラクチャやツールとシームレスに統合します。
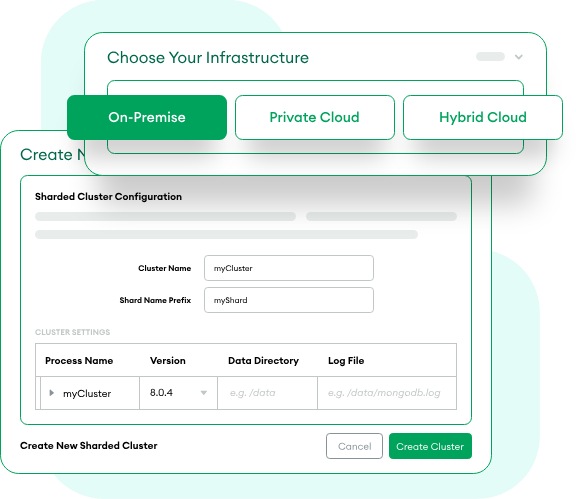
どこでもMongoDBを実行
MongoDB Enterprise Advanced は、本番アプリケーション向けのモダンなデータベースを実行するための最も柔軟な方法です。また、Ops Manager を利用することで、オンプレミス、プライベートクラウド、およびハイブリッドクラウドでの直感的なデプロイメントを可能にします。
MongoDB Community Editionとの違い
MongoDB Enterprise Advanced サブスクリプションには、MongoDB Enterprise Server の商用ライセンスが含まれています。MongoDB Enterprise Server は、MongoDB Community Edition には含まれていないいくつかの機能を提供します。これには、セルフマネージド型デプロイメント向けのインメモリ・ストレージエンジン、セルフマネージド型デプロイメントの監査機能、およびセルフマネージド型デプロイメントでの Kerberos 認証が含まれます。

Atlas Search
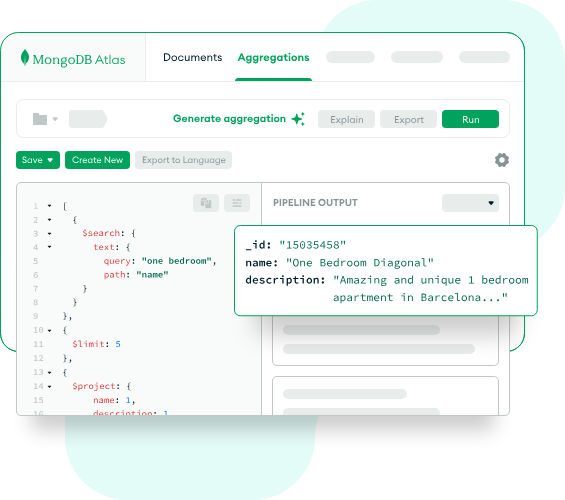
Atlas Searchは、データベース、検索エンジン、同期メカニズムを、単一の、統合された、フルマネージドのプラットフォームに統合します。Atlas Searchは、関連性に基づいた検索機能をアプリケーションに直接構築するための、最もシンプルで、最も速く、最も簡単な方法です。
Atlas は、プロビジョニング、パッチ適用、スケーリング、ディザスタリカバリを自動化し、堅牢なセキュリティと、検索操作やデータベースパフォーマンスに対する高度な可視性を提供します。
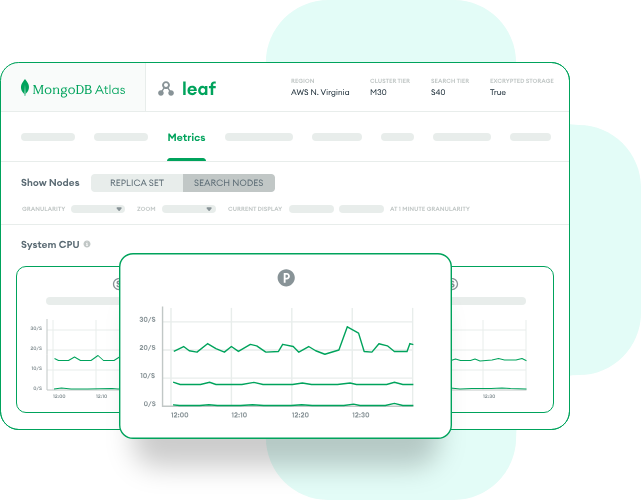
Atlas Vector Search
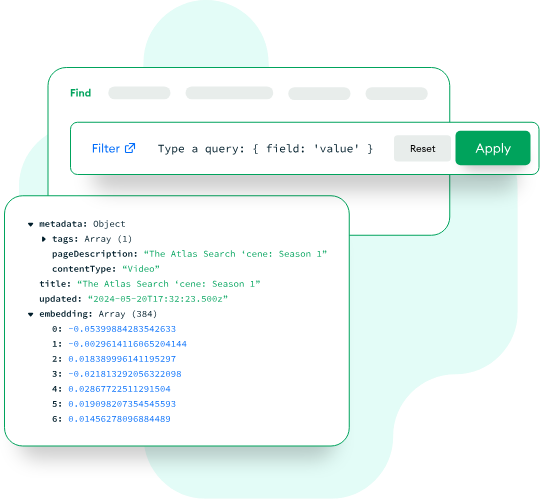
あらゆる種類のデータに対して、セマンティック検索と生成AIを活用したインテリジェントなアプリケーションを構築しましょう。オペレーショナルデータベースとベクター検索を、完全なベクターデータベース機能を備えた単一の統合されたフルマネージドプラットフォームに統合します。
Atlas Stream Processing
大規模な複雑なイベントデータの処理を必要とするアプリケーション構築の方法を変革しましょう。API、クエリ言語、およびデータモデル全体にわたって、単一の統合されたプラットフォームを使用し、データベースに保存されている重要なデータと並行してストリーミングデータを継続的に処理します。
ストリーミングデータを扱う際、スキーマ管理はデータの正確性と開発者の生産性にとって極めて重要です。ドキュメントモデルは、開発者にリアルタイムデータを用いたアプリケーションを構築するための、柔軟で自然なデータモデルを提供します。

Atlas Charts
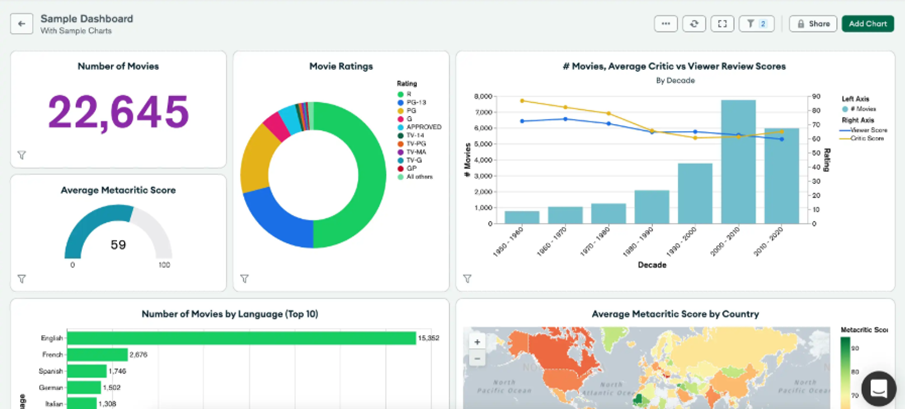
Charts は、MongoDB Atlas のデータを利用して迅速、シンプル、かつ強力にデータ ビジュアライゼーションを実行し、リアルタイムのビジネスの洞察をすばやく簡単に取得できます。
Charts を導入すると、数回クリックするだけで複数のチャートを使用して簡単にダッシュボードを作成できます。Charts は自動更新されるので、データをリアルタイムに確認できます。
MongoDBの提供モデルの比較表
MongoDB Enterprise Advanced
MongoDB Atlas

あなたの課題を一緒に解決しませんか?
まずはお気軽にご相談ください。経験豊富なエンジニアがお客様の課題をお聞きし、
最適なソリューションをご提案いたします。