
大規模言語モデルによるナレッジグラフ自動化の概念検証[2]
ーLLM とコード処理を分離し、役割を明確化ー
はじめに
前回の記事 大規模言語モデルによるナレッジグラフ自動化の概念検証[1] に続き、今回も引き続き、大規模言語モデル(LLM)を活用したナレッジグラフの自動生成についての概念検証を行っています。
今回は、弊社のテックブログをソースデータとして選びました。それは、企業内に点在するさまざまなドキュメントや情報資源の構造と似ているからです。
- 社内には情報がたくさんあるけれど、それぞれが点在していて、全体像が見えにくい
- 暗黙知や属人的な感覚で運用されていることも多く、可視化されていない
- 時間が経つにつれ、情報のカオスは深まり、かつて頭の中でその「地図」を描けていた人たちは退職や異動でいなくなっていく
こうした状況の中で、まずは自社内の情報を対象に、地図化(=グラフ化)を試みながら、その可能性と限界を探っていきます。
ちなみに、前回使用した映画データベースのような整然としたサンプルは「きれいすぎて当たり前にうまくいく」との声もありました。そこで今回は、多様なジャンルの情報が集まっている弊社のテックブログを素材として選んでみました。
概念検証の概要
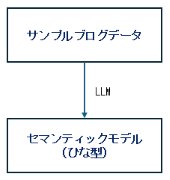
今回の検証は、大きく2つのステップに分けて進めています。
- サンプルのブログデータをもとに、セマンティックモデル(グラフ仕様書、ひな型)を作成
- 作成したセマンティックモデルを使って、複数のブログ記事からグラフ構造を抽出し、Neo4jに登録
ソースデータの抽出とセマンティックモデルの作成
今回の検証は、以下のステップで構成されています。
1.サンプルのソースデータ抽出
→ コードを用いて、対象となるテックブログ記事のデータを収集
2.エンティティとリレーションシップの抽出
→ 大規模言語モデル(LLM)を使って、記事内から意味的な要素(人物・技術・関連性など)を抽出
3.セマンティックモデルの作成(=グラフモデルの仕様書/ひな型)
→ LLMを活用して、抽出された要素をもとに構造的なグラフモデルを設計
4.サンプルグラフの構築
→ モデルに沿ってサンプルデータをグラフ化し、Neo4jに登録
5.評価とチューニング
→ 人によるレビューやクエリ検証を通じて、グラフ構造の過不足を評価・調整
6.セマンティックモデルの完成
ナレッジグラフ作成
今回の検証では、以下の流れでナレッジグラフの構築を進めました。
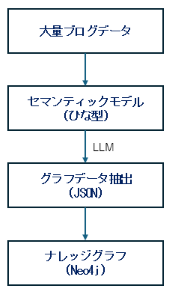
1.大量のソースデータからグラフデータを抽出(対象:サンプル50記事)
→ LLMを用い、事前に定義したプロンプトとセマンティックモデルに基づいて、記事からエンティティと関係性を抽出
2.抽出結果をJSON形式のグラフデータに変換
→ LLMからの出力をPythonコードで整理し、Neo4jに取り込める形式に整形
3.Cypherクエリを作成してNeo4jへ登録
→ JSONデータをもとにCypherクエリを生成し、Neo4jにノードとリレーションとして格納
4.評価とチューニング
→ 実際に生成されたグラフを人手でレビューし、クエリ実行可能性や意味的な妥当性を確認。必要に応じてモデルやプロンプトを調整
5.ナレッジグラフの完成
→ 評価・改善を経て、実用性のあるナレッジグラフとして整備実行環境について
もし実際に実行してみたい場合、現在のコードは Claude Sonnet 4 をベースにしており、Claude の APIキーが必要になります。
ただし、OpenAI やその他のクラウドサービスの APIキーしかお持ちでない場合でも、コードの一部をAIドリブンで簡単に改修できるはずです。
また、Neo4j の環境については、コミュニティ版または Docker 版を利用するのが最も手軽です。
https://neo4j.com/product/community-edition/
https://neo4j.com/docs/operations-manual/current/docker/docker-compose-standalone/
なお、Neo4j環境まで触れみたい場合、バージョンはv5.13以上にすべきです。今後の連載でVector Indexが必要になるためです。
コードは、Python 3.11をベースにしています。ソースデータの抽出とセマンティックモデルの作成
サンプル記事抽出
弊社のテックブログからの記事の抽出には、Pythonコードを使用しています。
今回の概念検証で開発したコードは、以下のGitHubリポジトリに格納されています。
https://github.com/awk256/neo4j-lab-semantic-model
├── cypher_output
├── files
├── graph
├── graph_extract
├── graph_extract copy
├── script
├── semantic
└── source_dataこのコードでは、ブログ記事の一覧からサブカテゴリごとに2件ずつ、合計50件分のサマリを抽出しています。なお、このステップでは LLMは使用していません。
| スクリプト | デスクリプション |
|---|---|
| category_extract.py | カテゴリリストを抽出 |
| python articles_list.py | すべての記事一覧とを取得 |
| python article_list_sample.py | すべての記事一覧からサンプル50記事を取得 |
| python article_text_extractor.py | サンプル50記事の一覧から記事のサマリを取得 |
概念検証に使用しているブログ記事は、すでに抽出済みです。
soruce_data/*.txt
そのため、この記事をご覧の方が、改めてコードを実行する必要はありません。
もしグラフ作成のコードを試してみたい場合は、提供しているサンプルコード内に含まれている50件分の記事データをそのままご利用ください。サンプル記事
title: "【Agile Kata Series】Part 1 : アジャイルのカタの概要"
url: "https://www.creationline.com/tech-blog/agile-devops/76256"
category: "アジャイル&DevOps"
category_uri: "https://www.creationline.com/tech-blog/agile-devops"
doc_id: "3be3acd080da"
fetched_at: "2025-09-13T08:48:29.669404+00:00"
source:
site: "www.creationline.com"
canonical_url: "https://www.creationline.com/tech-blog/agile-devops/76256"
lang: "ja"
authors:
- "中村知成"
published_at: "2024-12-30T02:55:00+00:00"
hash:
html_sha256: "1507a6e78e7f09bf611260e4e26d57c156f43497e631f33b69007b94f980ed57"
contents: |
今回から、シリーズもののブログを連載してみようと思います。お題は「アジャイルのカタ」についてです!
Part 1 : アジャイルのカタの概要
Part 2 : アジャイルのカタの要素 - 改善のカタ / コーチングのカタ / アジャイル
Part 3 : カタ体験ワークショップの紹介 ~ Kata in the Classroom ~
Part 4 : カタの派生 - カンバンのカタ / プロダクトのカタ / EBM
アジャイルのカタとは
アジャイルのカタの公式サイト
(
日本での周知サイトはこちら
)では、以下のように説明されています。
1
The Agile Kata is a universal pattern for continuous agile improvement.
(継続的かつアジャイルに改善するための共通パターン、それがアジャイルのカタ)
また、同サイトには
概要を表す以下のようなポスター
も掲載されています。
アジャイルのカタの特徴
アジャイルを実践する際に普遍的に導入できる、必要最低限の軽量なプロセス
アジャイルが対象とする複雑な領域において、「探索-把握-対応」のステップで対処
冒頭で紹介した「普遍的なパターン」という定義の通り、アジャイルのカタはアジャイル的な進め方全般で普遍的に適用できます。制約は緩く、他のプロセスほど導入時のオーバーヘッドは多くありません。
例えば、スクラムを厳密に実践しようとした場合、「スクラムマスターは誰がやる?」「(ソフトウェア開発以外の文脈での)インクリメントはどう定義する?」など、いくつか引っかかりそうな場面が出てきます。実践経験が豊富なチームならば適切に適応しながらカスタマイズできますが、それでもカスタマイズするというオーバーヘッドは発生するでしょう。一方で、アジャイルのカタでは、必要最低限のステップのみ定義されているので、アジャイルを志向しているどのチーム・プロジェクト・組織でも適用できます。
また、必要最低限のプロセスの中でも、アジャイルが対象とする複雑な問題領域に適切に対処できるステップが組み込まれています。アジャイルのカタの構成要素である、「改善のカタ」がその中核を提供しています。
アジャイルのカタを構成する要素
トヨタのカタ
アジャイル
改善のカタ
コーチングのカタ
Agile Mindset : アジャイルマインドセット
Measure Value : 価値に基づく計測
Agile Coaching : アジャイルコーチング
Collaboration : コラボレーション
Agile Leadership : アジャイルリーダーシップ
上記の表が、アジャイルのカタを構成する要素です。「トヨタのカタ」に「アジャイル」の要素で拡張したものが、「アジャイルのカタ」です。
トヨタのカタ(改善のカタ・コーチングのカタ)については、
こちらのスライド
が参考になるでしょう。アジャイルの要素は、上述したポスターの要素に矢印と一緒に図示されていますね。構成要素の詳細に関しては、シリーズPart 2で説明しようと思います。
アジャイルのカタのユースケース
上述したように、アジャイルのカタはあらゆる場所で普遍的に利用できるパターンです。とはいえ、具体的にどこで適用しているのか?が分かると、よりイメージしやすいかと思います。以下は、ユースケースの一例です。
レトロスペクティブとして
アジャイルチームのプロセスとして(スクラムやカンバンなどの代替・補完)
アジャイルな組織変革を進める際のプロセスとして
プロダクト開発以外でも、ビジネスアジリティを追求する部門で(人事・調達・財務・法務部門など)
プロダクトマネジメントの場で
私が実際にカタを適用している場所は、下記の場面です。明示的にアジャイルのカタの流れを見せながら進めるときもありますし、頭の中に思い浮かべながら話を進めることもあります。
クライアントへの提案時に、クライアントが進みたい方向を問いかけながら明確にする場で
アジャイルなプロダクト開発組織を目指して、変革への取り組みを推進する場で
VSMワークショップ後に、改善アクションを検討・実施していく場で
チーム・個人の目標設定の場で
他社の事例ですが、
KINTOテクノロジーズさんでは勉強会運営にアジャイルのカタを参考にしている
というのもありますね。
シリーズ第一弾として、今回はアジャイルのカタの概要を紹介しました。いかがでしたでしょうか?引き続き、次回以降の記事も用意していこうと思います。概要では触れなかった詳細や、実際の事例なども少しずつ紹介していけるとよさそうですね。
また、今回の記事で興味を惹かれた方は、2024年12月に出版されたばかりの下記の本もオススメです。カタの構成要素や想定ユースケースなどが詳細に記載されているので、より深くカタを知れることでしょう。
余談:アジャイルのカタとEBMの関連
「アジャイルのカタ」シリーズは、
EBM
の関連・補足記事としても考えています。
EBMで触れているアウトカムやインパクト・重要価値領域(CV/UV/T2M/A2I)を、「価値に基づく計測」に利用できる
EBMのゴール設定や、ゴール達成のためのステップの流れ自体が、改善のカタを参考にしたと推測される
つまり、EBMを実践しようとしている人にとっても、有益な記事になることでしょう。EBMとの関連性の詳細は、シリーズ後半のPartで紹介していければと思います。
脚注
2024/12/28現在、公式サイト上に以前は掲載されていたバージョン2.0のドキュメントが掲載されていません。ポスターはバージョン3.0なので、ドキュメントの更新作業が行われているのかもしれません。
2025/01/06追記:バージョン2.0ドキュメントの公式サイトでの配布を終了し、以降は
サーバントワークス様のサイト
で参考資料として公開されるとのことです。そちらを参照ください。
2025/04/22追記:
アジャイルのカタ - 日本での周知サイト
が公開されたので、翻訳文もそちらに合わせました
↩︎
EBMについて興味関心があり、
ご相談があれば以下よりお問い合わせください
中村知成
Twitter
大切にしている価値観:「現場で働くチームの役に立ちたい!」
そのために
- エンドユーザーへ価値を届けることを見据えつつ
- その価値を産み出すチームもより活き活きと動けるように
を目指しています!
中村知成の記事一覧
1回目のセマンティックモデル作成
サンプルグラフの作成
1回目のサンプルグラフを抽出してみました。
この段階では特に制約を設けず、ソースデータから可能な限りすべてのエンティティとリレーションシップを抽出しています。
以下がその結果のグラフですが、情報が過剰に細分化され、やみくもに複雑な構造になってしまいました。
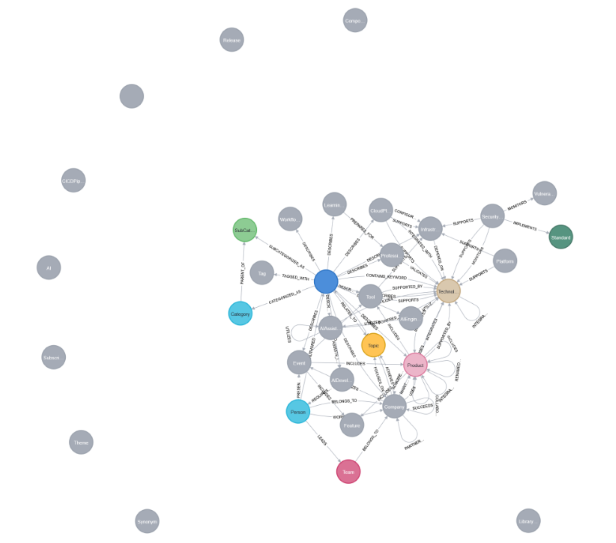
ドメインモデル
(Person)-[:BELONGS_TO]->(Team)
(Person)-[:AUTHORED]->(BlogPost)
(Person)-[:PRESENTED_AT]->(Session)
(Company)-[:WRITES]->(BlogPost)
(Company)-[:ORGANIZES]->(Event)
(Company)-[:MAINTAINS]->(Product)
(Company)-[:SUPPORTS]->(Technology)
(Company)-[:SPONSORS]->(Event)
(BlogPost)-[:CATEGORIZED_AS]->(Category)
(BlogPost)-[:SUBCATEGORIZED_AS]->(SubCategory)
(BlogPost)-[:TAGGED_WITH]->(Tag)
(BlogPost)-[:CONTAINS_KEYWORD]->(Keyword)
(BlogPost)-[:DESCRIBES]->(Event)
(BlogPost)-[:DESCRIBES]->(Session)
(BlogPost)-[:DESCRIBES]->(Feature)
(BlogPost)-[:DESCRIBES]->(Product)
(BlogPost)-[:RELATES_TO]->(Topic)
(Category)-[:PARENT_OF]->(SubCategory)
(Event)-[:INCLUDES]->(Session)
(Session)-[:COVERS]->(Theme)
(Session)-[:RELATES_TO]->(Topic)
(Session)-[:USES_TOOL]->(Tool)
(Product)-[:HAS_VERSION]->(Release)
(Product)-[:INCLUDES]->(Platform)
(Product)-[:INTEGRATES]->(Component)
(Release)-[:INCLUDES]->(Feature)
(Feature)-[:AVAILABLE_IN]->(SubscriptionTier)
(Feature)-[:SUPPORTED_BY]->(Technology)
(Platform)-[:SUPPORTS]->(Technology)
(Platform)-[:ENHANCED_BY]->(Feature)
(Platform)-[:CONTAINS]->(Component)
(Technology)-[:IMPLEMENTS]->(Standard)
(Keyword)-[:SYNONYM_OF]->(Synonym)
(Tool)-[:POWERED_BY]->(AI)
(Tool)-[:GENERATES]->(CypherQuery)
(Tool)-[:VISUALIZES]->(GraphData)評価とチューニング
このモデルで特に問題だったのは、キーワード自体は存在しているものの、リレーションシップにハルシネーション(誤生成)が含まれていたことです。
例えば、「人がチームに所属する」という構造は一般常識としては自然ですが、実際のブログ本文にはその組織との関係性が明示されていないため、グラフ上ではノードが孤立するという現象が発生しました。
この問題は、プロンプトを調整してフィルタリングすることにしました。
2回目のセマンティックモデル作成
今回は、プロンプトで「ブログ記事を検索するためのナレッジグラフ作成が目的であること」と「最低限の構成」にするように要求しました。
エンティティの抽出
その結果、エンティティの種類は当初の26種類から、5種類まで絞り込みました。
ただし、誤解のないように補足すると、この5種類がブログ検索において最適な分類というわけではありません。今回の検証では、あくまでもプロセス自体に重きを置いており、最適解を求めることを目的とはしていません。
1. BlogPost (ブログ記事)
役割: システムの中心的なコンテンツエンティティ
主要属性:
title (タイトル)
url (URL)
abstract (要約)
published_date (公開日)
2. Person (執筆者)
役割: コンテンツの作成者を管理
主要属性:
name (名前)
display_name (表示名)
集計属性: articles_count, first_article_date, last_article_date
3. Category (カテゴリ)
役割: 階層的な分類体系
主要属性:
name (カテゴリ名)
parent_category (親カテゴリ)
level (階層レベル: 0=ルート, 1=サブ)
description (説明)
4. Tag (タグ)
役割: 柔軟なラベリングシステム
主要属性:
name (タグ名)
usage_count (使用回数)
trending_score (トレンドスコア)
5. Keyword (キーワード)
役割: 自動抽出された技術用語
主要属性:
word (キーワード)
type (種別: technology, concept, methodology, tool, framework)
domain (技術領域)
synonyms (同義語)リレーションシップの抽出
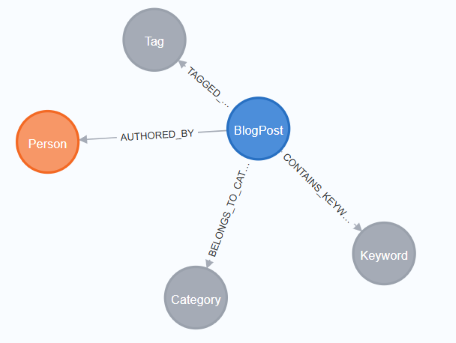
(BlogPost)-[:AUTHORED_BY]->(Person)
(BlogPost)-[:BELONGS_TO_CATEGORY]->(Category)
(BlogPost)-[:TAGGED_WITH]->(Tag)
(BlogPost)-[:CONTAINS_KEYWORD {frequency, importance}]->(Keyword)
(BlogPost)-[:RELATED_TO {similarity_score}]->(BlogPost)
(Category)-[:HAS_PARENT]->(Category)セマンティックモデル作成
これで作成した「セマンティックモデル」です。
セマンティックモデルは、グラフの仕様書のようなものと考えて良いでしょう。
筆者はこれを「グラフのひな型」とも呼んでいます。
LLMを使ってグラフデータを抽出する際には、このセマンティックモデルに従って処理が進められます。
つまり、セマンティックモデルはソースデータの分析結果から導き出された構造的な設計図であり、
同時に、グラフ生成のための指針・プロセスとしても機能します。
セマンティックモデル
{
"graph": {
"nodes": [
{
"name": "BlogPost",
"japanese_name": "ブログ記事",
"description": "検索対象となる記事コンテンツの中核エンティティ",
"attributes": [
{
"name": "title",
"type": "string",
"required": true,
"searchable": true,
"description": "記事タイトル",
"example": "知っておくべきDevOpsの4原則"
},
{
"name": "url",
"type": "string",
"required": true,
"description": "記事のURL",
"example": "https://www.creationline.com/tech-blog/agile-devops/agile/50178"
},
{
"name": "abstract",
"type": "text",
"searchable": true,
"description": "記事要約",
"example": "DevOpsの4つの重要な原則について解説"
},
{
"name": "published_date",
"type": "date",
"required": true,
"description": "公開日",
"example": "2022-04-15"
}
]
},
{
"name": "Person",
"japanese_name": "執筆者",
"description": "記事の著者情報と執筆統計の管理",
"attributes": [
{
"name": "name",
"type": "string",
"required": true,
"searchable": true,
"description": "著者名",
"example": "admin"
},
{
"name": "display_name",
"type": "string",
"description": "表示用名前",
"example": "管理者"
},
{
"name": "articles_count",
"type": "integer",
"computed": true,
"description": "執筆記事数(集計値)",
"example": 25
},
{
"name": "first_article_date",
"type": "date",
"computed": true,
"description": "初回執筆日(集計値)",
"example": "2020-01-15"
},
{
"name": "last_article_date",
"type": "date",
"computed": true,
"description": "最新執筆日(集計値)",
"example": "2025-09-15"
}
]
},
{
"name": "Category",
"japanese_name": "カテゴリ",
"description": "記事の構造化された分類管理",
"attributes": [
{
"name": "name",
"type": "string",
"required": true,
"searchable": true,
"description": "カテゴリ名",
"example": "DevOps"
},
{
"name": "display_name",
"type": "string",
"description": "表示用カテゴリ名",
"example": "DevOps"
},
{
"name": "parent_category",
"type": "string",
"nullable": true,
"description": "親カテゴリ名(ルートの場合はnull)",
"example": "agile-devops"
},
{
"name": "level",
"type": "integer",
"enum": [
0,
1
],
"description": "階層レベル(0=ルート, 1=サブカテゴリ)",
"example": 1
},
{
"name": "articles_count",
"type": "integer",
"computed": true,
"description": "所属記事数(集計値)",
"example": 42
},
{
"name": "description",
"type": "text",
"searchable": true,
"description": "カテゴリ説明文",
"example": "DevOpsの手法、ツール、プロセスに関する記事"
}
]
},
{
"name": "Tag",
"japanese_name": "タグ",
"description": "記事の柔軟なラベリングと使用統計管理",
"attributes": [
{
"name": "name",
"type": "string",
"required": true,
"searchable": true,
"description": "タグ名",
"example": "GitLab"
},
{
"name": "normalized_name",
"type": "string",
"computed": true,
"description": "正規化タグ名(検索用)",
"example": "gitlab"
},
{
"name": "usage_count",
"type": "integer",
"computed": true,
"description": "使用回数(集計値)",
"example": 28
},
{
"name": "first_used",
"type": "date",
"computed": true,
"description": "初回使用日(集計値)",
"example": "2022-01-10"
},
{
"name": "last_used",
"type": "date",
"computed": true,
"description": "最終使用日(集計値)",
"example": "2025-09-15"
},
{
"name": "trending_score",
"type": "float",
"computed": true,
"description": "トレンドスコア(最近の使用頻度)",
"example": 7.2
}
]
},
{
"name": "Keyword",
"japanese_name": "キーワード",
"description": "記事から自動抽出される技術用語・概念の管理",
"attributes": [
{
"name": "word",
"type": "string",
"required": true,
"searchable": true,
"description": "キーワード",
"example": "継続的インテグレーション"
},
{
"name": "normalized",
"type": "string",
"computed": true,
"description": "正規化形(英語名等)",
"example": "continuous_integration"
},
{
"name": "type",
"type": "string",
"enum": [
"technology",
"concept",
"methodology",
"tool",
"framework"
],
"description": "キーワード種別",
"example": "concept"
},
{
"name": "domain",
"type": "string",
"description": "技術領域",
"example": "DevOps"
},
{
"name": "frequency",
"type": "integer",
"computed": true,
"description": "全記事での出現回数(集計値)",
"example": 15
},
{
"name": "articles_count",
"type": "integer",
"computed": true,
"description": "含有記事数(集計値)",
"example": 8
},
{
"name": "synonyms",
"type": "array<string>",
"description": "同義語リスト",
"example": [
"CI",
"Continuous Integration"
]
}
]
}
],
"relationships": [
{
"type": "AUTHORED_BY",
"japanese_type": "執筆者",
"source": "BlogPost",
"target": "Person",
"cardinality": "many_to_one",
"description": "記事の執筆者を表す",
"required": true
},
{
"type": "BELONGS_TO_CATEGORY",
"japanese_type": "カテゴリ分類",
"source": "BlogPost",
"target": "Category",
"cardinality": "many_to_one",
"description": "記事のカテゴリ分類を表す",
"required": true
},
{
"type": "TAGGED_WITH",
"japanese_type": "タグ付け",
"source": "BlogPost",
"target": "Tag",
"cardinality": "many_to_many",
"description": "記事のタグ付けを表す",
"required": false
},
{
"type": "CONTAINS_KEYWORD",
"japanese_type": "キーワード含有",
"source": "BlogPost",
"target": "Keyword",
"cardinality": "many_to_many",
"description": "記事に含まれるキーワードを表す",
"required": false,
"properties": [
{
"name": "frequency",
"type": "integer",
"description": "記事内での出現回数",
"example": 5
},
{
"name": "importance",
"type": "string",
"enum": [
"primary",
"secondary",
"mentioned"
],
"description": "重要度",
"example": "primary"
}
]
},
{
"type": "RELATED_TO",
"japanese_type": "関連記事",
"source": "BlogPost",
"target": "BlogPost",
"cardinality": "many_to_many",
"description": "類似度による関連記事を表す",
"required": false,
"properties": [
{
"name": "similarity_score",
"type": "float",
"description": "類似度スコア",
"example": 0.85
}
]
}
],
"constraints": [
{
"type": "unique",
"entity": "BlogPost",
"attributes": [
"id"
]
},
{
"type": "unique",
"entity": "BlogPost",
"attributes": [
"url"
]
},
{
"type": "unique",
"entity": "Person",
"attributes": [
"name"
]
},
{
"type": "unique",
"entity": "Category",
"attributes": [
"name"
]
},
{
"type": "unique",
"entity": "Tag",
"attributes": [
"name"
]
},
{
"type": "unique",
"entity": "Keyword",
"attributes": [
"word"
]
}
],
"indexes": [
{
"type": "text",
"entity": "BlogPost",
"attributes": [
"title",
"abstract"
]
},
{
"type": "btree",
"entity": "BlogPost",
"attributes": [
"published_date"
]
},
{
"type": "text",
"entity": "Category",
"attributes": [
"description"
]
}
]
}
}サンプルグラフ
こちらが、今回作成したサンプルグラフです。
サンプルグラフは、プロンプトで「セマンティックモデル+サンプルデータ」に対して指示を出すことで生成されています。つまり、セマンティックモデルを適用した結果がどのような構造になるのかを確認するための検証にもなっています。
とはいえ、疑問に思う方もいるかもしれません。なぜセマンティックモデルが、あたかも整然とした「グラフの仕様書」のような形になっているのか?
その理由は大きく2つあります。
1つ目は、LLM自体が、すでにグラフ構造的な知識表現をある程度学習していること。
2つ目は、Few-Shot(少数ショット学習)の形式で、具体的な例をプロンプトとして与えていることです。
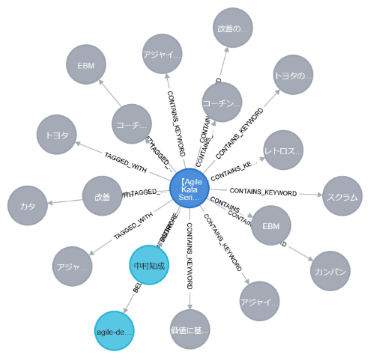
メターグラフ
メターグラフは、グラフデータベース内のグラフ構造そのものを記述するグラフです。つまり「グラフについてのグラフ」であり、以下の情報を含みます:
- ノードラベルの種類
- リレーションシップタイプの種類
- それらの接続パターン
- 各要素のプロパティの型
上記でみたセマンティックモデルは、このメターグラフの定義になります。
call db.schema.visualization評価とチューニング
今回は、大きなチューニングは行っていません。
実施したのは、出力に含まれていた 「language: ja」 や 「content: 記事の全サマリ」 といった不要なメタ情報を除外するため、セマンティックモデル側からこれらの項目を削除した程度です。
ナレッジグラフ作成
ここからは、50件のサンプル記事を使ってグラフを作成していきます。
具体的には、各記事とセマンティックモデルをLLMに渡し、セマンティックモデルに沿ったグラフデータをJSON形式で出力させるという手順を採用しました。
この方法に至るまでには、いくつかの試行錯誤がありました。
たとえば、記事から直接Cypherクエリを生成するアプローチも検討しましたが、構文エラーが発生することがあり、安定性に課題がありました。
そのため、今回は 構造的なJSONを経由してからCypherへ変換するという流れを採用しています。
なお、この方法がすべてのケースにおいて最適というわけではありません。
ただ、今回のようなケースで、かつ継続的にメンテナンスすることを前提とした運用においては、現実的かつ有効な手段である可能性が高いと考えています。
制約(Constraints)とインデックス作成
グラフ作成の前処理として、LLMを活用し、セマンティックモデルから制約とインデックスを抽出し、事前に設定しています。
セマンティックモデルには、ノードの一意性制約やインデックスの情報まで含まれており、
これらを使って、Neo4j上にあらかじめスキーマ的な準備を行いました。
これは、グラフデータを大量に生成・登録する際に、以下のような問題を防ぐためです。
- 制約(Uniqueness Constraint):ノードの重複を防ぎ、一意性を保証する
- インデックス(Index):検索やマッチ処理のパフォーマンスを向上させる
大量のデータを取り扱う場合、一意性の保証と処理速度の確保は非常に重要です。
そのため、これらの設定はグラフ作成前に必ず行うようにしています。
// BlogPostノードの制約(urlで一意性確保)
CREATE CONSTRAINT blog_post_url_unique FOR (bp:BlogPost) REQUIRE bp.url IS UNIQUE;
// Personノードの制約
CREATE CONSTRAINT person_name_unique FOR (p:Person) REQUIRE p.name IS UNIQUE;
// Categoryノードの制約
CREATE CONSTRAINT category_name_unique FOR (c:Category) REQUIRE c.name IS UNIQUE;
// Tagノードの制約
CREATE CONSTRAINT tag_name_unique FOR (t:Tag) REQUIRE t.name IS UNIQUE;
// Keywordノードの制約
CREATE CONSTRAINT keyword_word_unique FOR (k:Keyword) REQUIRE k.word IS UNIQUE;
// BlogPostの全文検索インデックス
CREATE FULLTEXT INDEX blog_post_fulltext_index FOR (bp:BlogPost) ON EACH [bp.title, bp.content, bp.abstract];
// BlogPostの公開日インデックス(範囲検索用)
CREATE INDEX blog_post_published_date_index FOR (bp:BlogPost) ON (bp.published_date);
// Categoryの説明文全文検索インデックス
CREATE FULLTEXT INDEX category_description_fulltext_index FOR (c:Category) ON EACH [c.description];
// 検索性能向上のための追加インデックス
CREATE INDEX person_display_name_index FOR (p:Person) ON (p.display_name);
CREATE INDEX tag_normalized_name_index FOR (t:Tag) ON (t.normalized_name);
CREATE INDEX keyword_normalized_index FOR (k:Keyword) ON (k.normalized);
CREATE INDEX keyword_type_index FOR (k:Keyword) ON (k.type);
CREATE INDEX category_level_index FOR (c:Category) ON (c.level);
CREATE INDEX blog_post_language_index FOR (bp:BlogPost) ON (bp.language);結果を確認してみてください。
show indexes
show constraintsLLMを利用してグラフ作成
ここからは、グラフの作成プロセスを段階的に追いながらご紹介していきます。
使用しているデータとコードは、以下のリンクから取得可能です。
https://github.com/awk256/neo4j-lab-semantic-model
Step1: 記事からJSON形式でグラフデータを抽出し、標準出力
以下のコードは、1本のブログ記事からグラフデータを抽出し、その結果を標準出力に表示しています。
python graph_data_extract_1.py --source ../source_data/tech-blog_agile-devops_76638.txt
グラフデータ
{
"nodes": [
{
"id": "bp_001",
"labels": [
"BlogPost"
],
"properties": {
"url": "https://www.creationline.com/tech-blog/agile-devops/76638",
"title": "【Agile Kata Series】Part 2 : アジャイルのカタの要素 – 改善のカタ / コーチングのカタ / アジャイル",
"abstract": "トヨタのカタ(改善のカタ・コーチングのカタ)とアジャイルの要素について詳しく解説。科学的思考の実践を通じた適応力・改善力・革新力の向上手法を紹介。",
"published_date": "2025-01-07"
}
},
{
"id": "person_001",
"labels": [
"Person"
],
"properties": {
"name": "中村知成",
"display_name": "中村知成"
}
},
{
"id": "category_001",
"labels": [
"Category"
],
"properties": {
"name": "agile-devops",
"display_name": "アジャイル&DevOps",
"level": 0,
"description": "アジャイル開発とDevOpsの手法、プロセス、ツールに関する記事"
}
},
{
"id": "tag_001",
"labels": [
"Tag"
],
"properties": {
"name": "アジャイル",
"normalized_name": "agile"
}
},
{
"id": "tag_002",
"labels": [
"Tag"
],
"properties": {
"name": "カタ",
"normalized_name": "kata"
}
},
{
"id": "tag_003",
"labels": [
"Tag"
],
"properties": {
"name": "トヨタ",
"normalized_name": "toyota"
}
},
{
"id": "tag_004",
"labels": [
"Tag"
],
"properties": {
"name": "改善",
"normalized_name": "kaizen"
}
},
{
"id": "tag_005",
"labels": [
"Tag"
],
"properties": {
"name": "コーチング",
"normalized_name": "coaching"
}
},
{
"id": "tag_006",
"labels": [
"Tag"
],
"properties": {
"name": "PDCA",
"normalized_name": "pdca"
}
},
{
"id": "tag_007",
"labels": [
"Tag"
],
"properties": {
"name": "EBM",
"normalized_name": "ebm"
}
},
{
"id": "tag_008",
"labels": [
"Tag"
],
"properties": {
"name": "OKR",
"normalized_name": "okr"
}
},
{
"id": "keyword_001",
"labels": [
"Keyword"
],
"properties": {
"word": "科学的思考",
"normalized": "scientific_thinking",
"type": "methodology",
"domain": "アジャイル",
"synonyms": [
"科学的アプローチ",
"仮説検証"
]
}
},
{
"id": "keyword_002",
"labels": [
"Keyword"
],
"properties": {
"word": "改善のカタ",
"normalized": "improvement_kata",
"type": "methodology",
"domain": "トヨタ生産システム",
"synonyms": [
"改善の型",
"Improvement Kata"
]
}
},
{
"id": "keyword_003",
"labels": [
"Keyword"
],
"properties": {
"word": "コーチングのカタ",
"normalized": "coaching_kata",
"type": "methodology",
"domain": "トヨタ生産システム",
"synonyms": [
"コーチングの型",
"Coaching Kata"
]
}
},
{
"id": "keyword_004",
"labels": [
"Keyword"
],
"properties": {
"word": "アジャイルマインドセット",
"normalized": "agile_mindset",
"type": "concept",
"domain": "アジャイル",
"synonyms": [
"アジャイル思考",
"Agile Mindset"
]
}
},
{
"id": "keyword_005",
"labels": [
"Keyword"
],
"properties": {
"word": "価値に基づく計測",
"normalized": "value_based_measurement",
"type": "methodology",
"domain": "アジャイル",
"synonyms": [
"価値計測",
"Value-based Measurement"
]
}
},
{
"id": "keyword_006",
"labels": [
"Keyword"
],
"properties": {
"word": "Evidence-Based Management",
"normalized": "evidence_based_management",
"type": "framework",
"domain": "アジャイル",
"synonyms": [
"EBM",
"エビデンスベースドマネジメント"
]
}
},
{
"id": "keyword_007",
"labels": [
"Keyword"
],
"properties": {
"word": "アジャイルコーチング",
"normalized": "agile_coaching",
"type": "methodology",
"domain": "アジャイル",
"synonyms": [
"Agile Coaching"
]
}
},
{
"id": "keyword_008",
"labels": [
"Keyword"
],
"properties": {
"word": "アジャイルリーダーシップ",
"normalized": "agile_leadership",
"type": "concept",
"domain": "アジャイル",
"synonyms": [
"Agile Leadership"
]
}
}
],
"relationships": [
{
"type": "AUTHORED_BY",
"start": "bp_001",
"end": "person_001",
"properties": {}
},
{
"type": "BELONGS_TO_CATEGORY",
"start": "bp_001",
"end": "category_001",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_001",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_002",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_003",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_004",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_005",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_006",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_007",
"properties": {}
},
{
"type": "TAGGED_WITH",
"start": "bp_001",
"end": "tag_008",
"properties": {}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_001",
"properties": {
"frequency": 8,
"importance": "primary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_002",
"properties": {
"frequency": 12,
"importance": "primary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_003",
"properties": {
"frequency": 8,
"importance": "primary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_004",
"properties": {
"frequency": 6,
"importance": "primary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_005",
"properties": {
"frequency": 4,
"importance": "secondary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_006",
"properties": {
"frequency": 5,
"importance": "secondary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_007",
"properties": {
"frequency": 4,
"importance": "secondary"
}
},
{
"type": "CONTAINS_KEYWORD",
"start": "bp_001",
"end": "keyword_008",
"properties": {
"frequency": 3,
"importance": "secondary"
}
}
]
}Step2: サンプル記事50項目からグラフデータを抽出し、ファイルに格納
以下では、50件のサンプル記事を読み込み、そこからグラフデータを抽出してローカルディスクに保存しています。
python graph_data_extract_2.py
- input:
- source_data/*.txt
- output:
- graph_extract/*.jsonNeo4jに接続し、グラフ作成
Step1: JSONのグラフデータからCypherを生成し、標準出力
以下のコードは、グラフデータから、Cypherを生成し、標準出力しています。
python graph_data_to_cyhper_extract_1.py --input ../graph_extract/tech-blog_agile-devops_76256_graph.jsonこのCypherは、LLMを介さずに、PythonコードでJSON形式のグラフデータから直接行っており、ノードやリレーションシップの重複を避け、冪等性(同じ操作を繰り返しても状態が変わらないこと)を保証する構成になっています。
このような作りにしておくことで、グラフの継続的な更新やメンテナンスが求められるシーンでも安定して運用することができます。
Cypher Query
// ===== ノード作成 =====
MERGE (n:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
SET n.title = '【Agile Kata Series】Part 1 : アジャイルのカタの概要', n.abstract = 'アジャイルのカタの概要について解説。継続的かつアジャイルに改善するための共通パターンとして、普遍的に適用できる軽量なプロセスを紹介。トヨタのカタとアジャイルの要素を組み合わせた構成要素や、レトロスペクティブ、組織変革、プロダクト開発などでの具体的なユースケースを説明。', n.published_date = '2024-12-30';
MERGE (n:Person {name: '中村知成'})
SET n.display_name = '中村知成';
MERGE (n:Category {name: 'agile-devops'})
SET n.display_name = 'アジャイル&DevOps', n.parent_category = null, n.level = 0, n.description = 'アジャイル開発とDevOpsに関する記事カテゴリ';
MERGE (n:Tag {name: 'アジャイル'})
SET n.normalized_name = 'agile';
MERGE (n:Tag {name: 'カタ'})
SET n.normalized_name = 'kata';
MERGE (n:Tag {name: '改善'})
SET n.normalized_name = 'improvement';
MERGE (n:Tag {name: 'トヨタ'})
SET n.normalized_name = 'toyota';
MERGE (n:Tag {name: 'コーチング'})
SET n.normalized_name = 'coaching';
MERGE (n:Tag {name: 'EBM'})
SET n.normalized_name = 'ebm';
MERGE (n:Keyword {word: 'アジャイルのカタ'})
SET n.normalized = 'agile_kata', n.type = 'methodology', n.domain = 'アジャイル', n.synonyms = ['Agile Kata'];
MERGE (n:Keyword {word: '改善のカタ'})
SET n.normalized = 'improvement_kata', n.type = 'methodology', n.domain = '改善', n.synonyms = ['Improvement Kata'];
MERGE (n:Keyword {word: 'コーチングのカタ'})
SET n.normalized = 'coaching_kata', n.type = 'methodology', n.domain = 'コーチング', n.synonyms = ['Coaching Kata'];
MERGE (n:Keyword {word: 'トヨタのカタ'})
SET n.normalized = 'toyota_kata', n.type = 'methodology', n.domain = '改善', n.synonyms = ['Toyota Kata'];
MERGE (n:Keyword {word: 'レトロスペクティブ'})
SET n.normalized = 'retrospective', n.type = 'methodology', n.domain = 'アジャイル', n.synonyms = ['振り返り'];
MERGE (n:Keyword {word: 'スクラム'})
SET n.normalized = 'scrum', n.type = 'framework', n.domain = 'アジャイル', n.synonyms = ['Scrum'];
MERGE (n:Keyword {word: 'カンバン'})
SET n.normalized = 'kanban', n.type = 'methodology', n.domain = 'アジャイル', n.synonyms = ['Kanban'];
MERGE (n:Keyword {word: 'EBM'})
SET n.normalized = 'evidence_based_management', n.type = 'framework', n.domain = 'マネジメント', n.synonyms = ['Evidence-Based Management', 'エビデンスベースドマネジメント'];
MERGE (n:Keyword {word: 'アジャイルマインドセット'})
SET n.normalized = 'agile_mindset', n.type = 'concept', n.domain = 'アジャイル', n.synonyms = ['Agile Mindset'];
MERGE (n:Keyword {word: '価値に基づく計測'})
SET n.normalized = 'value_based_measurement', n.type = 'concept', n.domain = 'マネジメント', n.synonyms = ['Measure Value'];
// ===== リレーションシップ作成 =====
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Person {name: '中村知成'})
MERGE (start)-[r:AUTHORED_BY]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Category {name: 'agile-devops'})
MERGE (start)-[r:BELONGS_TO_CATEGORY]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: 'アジャイル'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: 'カタ'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: '改善'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: 'トヨタ'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: 'コーチング'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Tag {name: 'EBM'})
MERGE (start)-[r:TAGGED_WITH]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'アジャイルのカタ'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 15, importance: 'primary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: '改善のカタ'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 8, importance: 'primary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'コーチングのカタ'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 5, importance: 'secondary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'トヨタのカタ'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 4, importance: 'secondary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'レトロスペクティブ'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 3, importance: 'secondary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'スクラム'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 3, importance: 'mentioned'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'カンバン'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 2, importance: 'mentioned'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'EBM'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 6, importance: 'secondary'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: 'アジャイルマインドセット'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 2, importance: 'mentioned'}]->(end);
MATCH (start:BlogPost {url: 'https://www.creationline.com/tech-blog/agile-devops/76256'})
MATCH (end:Keyword {word: '価値に基づく計測'})
MERGE (start)-[r:CONTAINS_KEYWORD {frequency: 2, importance: 'mentioned'}]->(end);
Step2: 1記事のグラフデータからCypherを生成し、Neo4jに投入
以下のコードは、1記事のグラフデータからCypherを生成し、Neo4jに登録しています。
python graph_data_to_cyhper_extract_2.py --input ../graph_extract/tech-blog_agile-devops_76256_graph.jsonグラフが正しく作成されているかを確認してみましょう。
以下のようなグラフが表示されていれば、処理は正常に完了しています。
MATCH (b:BlogPost)-[AUTHORED_BY]->(p:Person) RETURN b,p
Step3: 50記事のグラフデータからCyhperを生成し、Neo4jに投入
以下のコードは、50件分のグラフデータを順に処理し、それぞれからCypherを生成してグラフを作成しています。
python graph_data_to_cyhper_extract_3.py2025-10-02 14:35:09,579 - INFO - 対象ファイル数: 50
2025-10-02 14:35:09,579 - INFO - - ../graph_extract/tech-blog_chatgpt-ai_ai_69246_graph.json
2025-10-02 14:35:09,579 - INFO - - ../graph_extract/tech-blog_cloudnative_chef_23515_graph.json
2025-10-02 14:35:09,579 - INFO - - ../graph_extract/tech-blog_others_yorozunomichi_40863_graph.json
...中略
============================================================
2025-10-02 14:35:28,849 - INFO - 処理中: ../graph_extract/tech-blog_others_kaizen_70055_graph.json
2025-10-02 14:35:28,849 - INFO - 出力ファイル: ../cypher_output/tech-blog_others_kaizen_70055_graph.cypher
2025-10-02 14:35:28,849 - INFO - グラフデータを読み込み中: ../graph_extract/tech-blog_others_kaizen_70055_graph.json
2025-10-02 14:35:28,850 - INFO - グラフデータ読み込み完了: ノード数=13, リレーション数=11
2025-10-02 14:35:28,850 - INFO - Cypher構文を生成中...
2025-10-02 14:35:28,850 - INFO - Cypher構文生成完了: 50 ステートメント
2025-10-02 14:35:28,850 - INFO - Cypher構文を保存: ../cypher_output/tech-blog_others_kaizen_70055_graph.cypher
2025-10-02 14:35:28,850 - INFO - Cypher構文を実行中...
2025-10-02 14:35:29,168 - INFO - --- before
2025-10-02 14:35:29,168 - INFO - after
2025-10-02 14:35:29,168 - INFO - @@ stats @@
2025-10-02 14:35:29,168 - INFO - nodes_created: 11
2025-10-02 14:35:29,168 - INFO - relationships_created: 11
2025-10-02 14:35:29,169 - INFO - properties_set: 57
2025-10-02 14:35:29,169 - INFO - ✔️ tech-blog_others_kaizen_70055_graph.json の処理完了
2025-10-02 14:35:29,169 - INFO -
============================================================
2025-10-02 14:35:29,169 - INFO - 全体結果:
2025-10-02 14:35:29,169 - INFO - 成功: 50 ファイル
2025-10-02 14:35:29,169 - INFO - 失敗: 0 ファイル
2025-10-02 14:35:29,169 - INFO - 合計: 50 ファイル
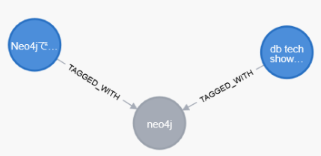
2025-10-02 14:35:29,169 - INFO - ✔️ すべてのファイルの処理が完了しました処理が完了したら、グラフが正しく作成されているかを確認してみてください。
MATCH (t:Tag { name: "neo4j"})--(n) RETURN t,n
OR
MATCH (t:Tag { name: "Neo4j"})--(n) RETURN t,nここでは、タグ名を使って Neo4j 上で検索を行ってみます。
今回は、25のサブカテゴリからそれぞれ2本ずつサンプル記事を抽出しているため、合計50件の記事分のグラフが生成されているはずです。
Neo4j 関連のデータが 2 件含まれていれば、想定通りに抽出できていると考えられます。
まとめ
今回の検証を通じて、グラフデータのモデリングにおいて LLM を非常に有効に活用できることがわかりました。ただし、セマンティックモデルの設計段階では、人によるチューニングが不可欠になる場面もあると感じています。
一方で、一度セマンティックモデルが完成すれば、その後の記事からグラフデータを抽出する工程は、LLM を経由して自動化できる可能性があるとも見えてきました。
とはいえ、現実の企業における情報資源は、そう単純ではありません。すべての情報が、リンクやサマリを綺麗に取得できるとは限らず、むしろそれはレアケースかもしれません。これは、実際に弊社でも課題として感じている部分です。
さらに、そもそも LLM が「意味として理解できる形」にデータを整えるための前処理の段階そのものが、依然として大きなハードルとして残っています。
とはいえ、すべてを一気に解決するのは現実的ではありません。
まずはアプローチ可能なところから取り組んでいくことが重要だと考えています。
本連載では、そうした現実的な制約や課題も踏まえた上で、
ナレッジグラフの活用(GraphRAG)に向けた概念検証を、継続的に進めていく予定です。
以下が、連載の構想(予定を含む)です:
お楽しみに。
🧭連載
- 全工程を LLM のコンソール上で完結
- LLM とコード処理を分離し、役割を明確化
- GraphRAGへの道とNeo4j Vector Index
- 自然言語で探索する GraphRAG 検索の実践
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



