
AI 開発の実験レポート:プロダクトを繰り返し再構築して観察する設計判断の変化(第2ラウンド)
本稿は、生成 AI を利用したアプリケーション開発の第2ラウンドにおける実験内容と観測結果を記録したものである。第1ラウンドで得た知見を踏まえ、開発条件を固定した状態でプロダクトを再構築し、設計判断、品質、開発プロセスの傾向を整理した。モデル固定、並列開発、テストおよびセキュリティ対策、ドキュメント生成、UX 設計などについて、事実ベースで記述する。
2ラウンド目では、気にしていなかった費用の面やUXについても触れていく。また、直接は実施していないが設計を改善するためのドメイン分析の必要性やSpecKitを用いた仕様駆動開発のメリットや冗長な点についても触れていく
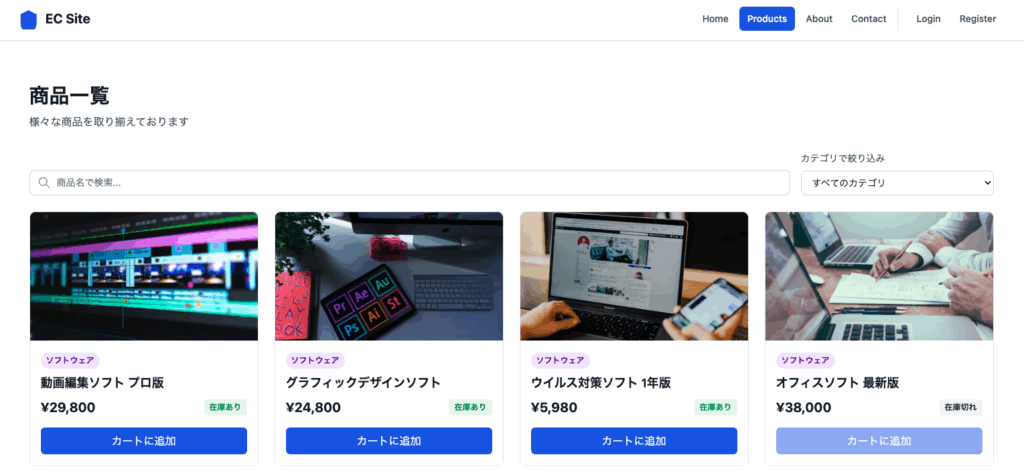
機能はシンプルではあるが、ログインの認証機能、商品一覧、商品の詳細、決済、あとは管理者用の各種管理画面を約30時間バックグラウンドでCursorを稼働させ続けて開発した。
2. 開発条件
モデル・ツール
- ツールはCursorを利用。モデルは Sonnet 4.5 に固定した。
- 仕様整理には Speckit を使用した。
- コードは人間が一行も書かず、すべて生成 AI に出力させた。
仕様化とバックログ管理
- 初回セッションで得た機能一覧をもとにバックログを作成した。
- 各バックログには BDD(振る舞い駆動開発)の受け入れ条件を付与した。
- 設計判断は ADR(Architecture Decision Record) として整理した。
- 品質基準はセキュリティ面では、OwaspZap等を基準にDASTを実施、ESListを用いたSASTを実施。非機能面ではISO25010、機能テストはJSTQBの基準をベースに実施した
テスト・セキュリティ・レビュー
- 単体・結合テストには Jest を使用するよう指示した。
- テストコードは生成させたが、実行結果の確認は行っていない。
- セキュリティは OWASP ZAP に準拠するよう指示した。
- GitHub を利用したが、CI パイプラインは使用していない。
実装フロー
- バックログ間の依存関係を事前に確認し、依存がない項目は並列で実行した。
- 動作確認は、不審な動作が見られる場合に限定し、最終確認をプルリクエスト直前にまとめて行った(コマンドを作成して処理内容とフォーマットを統一した)
- AI Agentの作業引き継ぎには、定型のログをルールとして指示した(自由に作成させていたら冗長でトークン消費が激しかったため)
ドキュメント
- 引き継ぎ資料は AI が読みやすい構造を優先し、最後に人間向けの要約を付与した。
- UI については Google のデザインガイドを明示的に適用した。
3. 開発の進め方(第1ラウンドとの違い)
バックログの構造と並列性
第1ラウンドではバックログ粒度にばらつきがあり、依存関係の整理が不十分だったので、第2ラウンドではユースケース単位でバックログを作成し、依存関係を AI と確認したうえで並列実行を行った。
動作確認方法の明確化
すべての生成結果を検証すると時間とコストが増えるため、検証範囲を限定した。基本的にはAIに品質保証を委任。レポートを確認して、不審な挙動がある場合のみ個別確認を行い、最終確認をプルリク前にまとめて行う方式に統一した。
ドキュメント形式の統一
AI が解析しやすい文章構造と語彙に統一することで、仕様解釈の揺れを抑えた。これにより、指示内容と生成結果の差異が減少した。
4. 観測したこと
モデル利用時間とコスト
開発時間は約 30 時間となり、Sonnet 4.5 の使用コストは 200 ドルを超えた。モデルを固定してすべての処理を行う場合、コストが高くなることが確認された。
並列実行の挙動
依存関係のないバックログを並列で処理したところ、GitHub 上でコンフリクトは発生しなかった。依存関係がはっきりしていれば並列開発が成立することが確認できた。
UI と UX の特性
UI はコンポーネント単位で整っており、画面単体では問題が少なかった。一方で画面間の遷移や体験の一貫性は弱く、UX レベルでの調整は AI 任せでは不足する傾向があった。
ポストモーテム のコスト
AIを用いた開発の最大のメリットはポストモーテムを含むふりかえりを好きなタイミングで実施できること。しかし、本件では、全ファイルを読み込ませたふりかえりを多数実施したせいで不測のコストが生じた。4エージェントを並列で各々全てのドキュメントを読み込ませたおかげで毎回8ドルのコストがかかっていたことを後に知った。
5. 現時点での仮説
テスト生成の限界
AI は形式的なテストを生成するが、実際の網羅性は保証されない。AI の自己報告ではテストカバレッジ 100% とされていたが、実測値は 38.9% だった。形式的に整えようとする傾向があり、実装全体の網羅には至らない。
モデル固定の非効率性
生成作業のすべてを Sonnet 4.5 で行う必要はなく、作業内容に応じたモデル選択のほうがコスト削減につながる。今の時点での感想はプランニングや複雑な作業はCodexやGPT5(相当賢い)、レポーティングやGPTが作成して理解できない箇所はSonnetを用いて補完、コーディングやタスクの作業はComposer1がいいかと思っている。
品質基準と指示内容
UI、セキュリティ、品質について基準を明示すると、一定の整合性が保たれる。ただし細かく指示するとトークン消費が増えるため、BDD のように振る舞いレベルでの基準設定が適していると感じた。ただしAWSのKiroはEARS記法を用いてより最適なプロパティ検証を行なっていることもあり、最適解は探索していく必要があると感じている。
ポストモーテムの実施方式
コード全体を対象にしたポストモーテムは負担が大きいため、バックログ単位、またはプルリクマージ直後に小規模で毎回振り返る方が現実的だし、こまめにフィードバックを適用できると感じた。AI駆動開発を進めれば進めるほど、小さなチームでアジャイル開発を実施している感覚に陥る。チームでバックログを2週間単位で作っていくのではなく、AIAgentたちと1日単位でスプリントを繰り返していく感覚だ。とするのであればブランチをマージするタイミングでふりかえりを行なってフィードバックを取り入れるのは自然だと感じている。
UX 改善にはドメイン理解が必要
UX はデザインガイドだけでは向上しない。ユースケースとデータ境界の整理が必要であり、ドメインに対する理解を前提に設計を行う必要がある。今回のプロダクトは、各機能の部品は仕様を満たして品質も及第点、データ設計もセキュリティ担保されているが、使ってみると特徴がない。それは当然でデザインガイドのみをインプットにしており「だれのどんな課題を解決したい」プロダクトなのかのインプットは入れていない。加えると、ユーザーと管理者を想定しているが、管理者側の解像度がまだ荒いので、ドメイン分析もできていなく、もしかするとデータを分けて管理した方がいい可能性もあるが、その点に関してはインプットとして与えられていない。
6. まとめ
第2ラウンドの実験により、生成 AI を中心とした開発の特性がより明確になった。並列処理の条件、テスト生成の限界、UX 設計の難しさ、モデル固定時のコスト構造などが確認できた。品質基準の設定やバックログ粒度の統一、AI に最適化したドキュメント構造は一定の効果があり、生成プロセスの安定に寄与した。
一方で、UX やテストのように実行検証やドメイン理解が必要な領域では、人間による設計や確認が不可欠である。今後はモデル選択の最適化、ポストモーテムを含めたふりかえちの小規模化、UX 設計の補強などを行い、AI と人間の役割分担をより明確にしていく。



