
Claude Certified Architect – Foundations (CCA-F)に挑戦したけどダメだった記録
はじめに
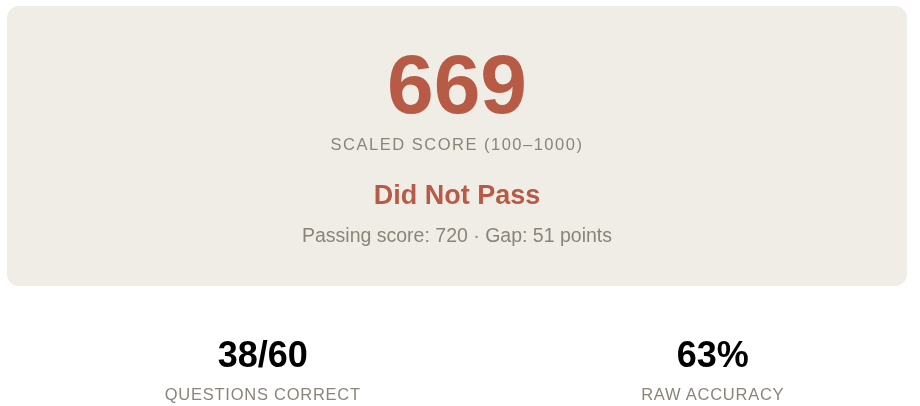
2026年6月9日、Anthropicの公式資格試験である「Claude Certified Architect - Foundations (CCA-F)」を受験したのですが、合格ライン720/1000のところ 669/1000 というスコアで不合格でした。合格したという記事はよく見かけますが不合格だったという記事はあまり見ないので、今後の方のためにどうダメだったのかという点について記録しようと思います。
なお、状況は大変流動的であり、すぐに役に立たない情報になっているかもしれないことをご了承ください。
筆者のバックグラウンド
CCA-Fに挑戦しようと思ったときの筆者のバックグラウンドです。
- Claude Code は毎日使用
- Slackチャットボットの作成など
- MCPサーバ・クライアントの作成経験あり
.claude以下はあんまり触っていない- skills 作成経験はあるがあんまり触っていない
- Batch API → 知らない
- Planモードもよく使う
- コンテキストの使い方ははっきり言って無頓着
- 「分からないことはClaude Codeにやらせたらいいじゃん」の精神
- 英語
- ある程度なら読めるし書ける
- 話したり聞いたりは全然できない
- 「分からない英文はClaude Codeに読み書きさせたらいいじゃん」の精神
- 英語のオンライン試験の経験
Anthropic Academy
まずAnthropic Academyの次の4コースを実施しました。
- Building with the Claude API
- Claude Code in Action
- Introduction to agent skills
- Introduction to Model Context Protocol
意外と簡単だな、おおむね知っていることの復習みたいなものだな、という具合でサクサク進みました。
udemyの非公式模擬試験
すべて英語の模擬試験がudemyにあったので受験してみました: Anthropic Claude Certified Architect - 3 Full Practice Exams
まず、英語の問題文がドカンと一塊、改行や装飾などまったくなしで出てくるので、かなり面喰らいました。
- Test 1: 合格! 81% 正解 (49/60)
- Claude Code Configuration & Workflows (12問) 100%
- Agentic Architecture & Orchestration (16問) 63%
- Prompt Engineering & Structured Output (12問) 83%
- Tool Design & MCP Integration (11問) 91%
- Context Management & Reliability (9問) 78%
- Test 2: 合格! 76% 正解 (46/60)
- Prompt Engineering & Structured Output (12問) 58%
- Claude Code Configuration & Workflows (12問) 92%
- Tool Design & MCP Integration (11問) 64%
- Context Management & Reliability (9問) 89%
- Agentic Architecture & Orchestration (16問) 81%
- Test 3: 合格! 85% 正解 (51/60)
- Claude Code Configuration & Workflows (12問) 100%
- Tool Design & MCP Integration (11問) 91%
- Agentic Architecture & Orchestration (16問) 88%
- Prompt Engineering & Structured Output (12問) 83%
- Context Management & Reliability (9問) 56%
英語の読解が大変だったけど、意外といけるな、という感じでした。
なお、公式模擬試験はここまで大きな塊では出てこないので、長文英語への耐性を上げるという点ではやってよかったかなと思います。
また、udemyではAIアシスタントが正解や不正解について解説する機能があったので、それに基いて復習を行っていました。
Anthropic Academyの公式模擬試験
受験資格のある人に対しては公式のPractice Examが提供されるので、それをやってみたところ 688/1000 (41/60) という散々な結果になってしまいました。udemyにあった非公式模擬試験より英文は読みやすいのですが、選択肢が格段に難しく、ことごとく罠選択肢に引っかかっていました。
| SCENARIO | SCORE | RESULT |
|---|---|---|
| Multi-Agent Research System | 9/15 (60%) | ⚠️ |
| Customer Support Resolution Agent | 14/15 (93%) | ✓ |
| Claude Code for Continuous Integration | 10/15 (67%) | ⚠️ |
| Code Generation with Claude Code | 8/15 (53%) | ⚠️ |
ここに至って、自信が全部崩れてしまいました。
Claude Codeを家庭教師に: 弱点分析
まず公式模擬試験の結果をClaude Codeに読ませて、自分の弱点は何なのかを分析させました。少し長くなるので適宜省略しています。
模擬試験 誤答傾向・弱点分析
総括
19問を落として 688点。合格ライン720点まで あと32点(およそ4〜5問分)。失点はほぼ3シナリオに集中しており、概念単位で見ると弱点はかなり明確。
弱点① Claude Code の設定機構の「使い分け」が未定着(最大の弱点)
Code Generation の7問はほぼすべてここに帰着する。「どの仕組みを、いつ使うか」の判断基準が曖昧で、機構の境界を取り違えている。
特に危険な2つの兆候
1. rules と skills の判断軸が逆転している。
2. 存在しない機能を発明してしまう。弱点② 設計原則(根本原因・最小権限・関心の分離)の適用が弱い
Multi-Agent と CI の失点は、「正しいレベルで根本原因に対処する」という原則を選べていない点で共通する。しかも誤りの方向が正反対の2タイプに分かれる。
タイプA: 信頼性が要る場面で「ソフトな指示」を選ぶ(弱すぎる)
「プロンプトで言えば守る」と考えがちだが、LLM の動作は確率的。信頼性・強制力が要る箇所はツール/コードレベルのハード制約が正解。
タイプB: 効率・品質問題で「コンポーネントを足す」(重すぎる)
問題を見るとレイヤーやエージェントを増やして解こうとする傾向。正解は「症状ではなく発生源(root cause)を最小の手段で叩く」「解決できる最も低いレベルで処理する」。
関心の分離の取り違え
- Q20: ドキュメント分析エージェントに信頼性判断までさせる(役割超過)→ 正解は両データを保持してコーディネーターに判断を委ねる
弱点③ 「具体例 > 抽象的指示」の原則が文脈で揺れる
出力の一貫性問題に「指示をもっと丁寧に書く」を選びがちだが、原則は抽象的指示より具体例(worked examples)が信頼性が高い。Customer Support では正解できていたので、知識はあるが CI/分類の文脈になると適用を外す = 条件反射になっていない。
弱点④ Message Batches API の特性理解が不正確
バッチが反復ツール呼び出しを壊すのはレイテンシではなくアーキテクチャ(fire-and-forget)が理由。「いつバッチが使えるか/なぜ使えないか」を正確に区別する。
優先学習ロードマップ
合格まであと32点 ≒ 4〜5問。費用対効果の高い順に:
1.【最優先】Claude Code 設定機構の早見表を作る
2. 設計原則の判断パターンを固定する
3. Batch API
4. 知らない選択肢は「実在する機能か」を一度疑う
最初に書いたバックグラウンドがそのまま効いてきました。
.claude以下はあんまり触っていない- Batch API → 知らない
- 「分からないことはClaude Codeにやらせたらいいじゃん」の精神
- 「分からない英文はClaude Codeに読み書きさせたらいいじゃん」の精神
「Claude Codeに全部お任せで雰囲気で使っている」ことがバレてしまいました。
Claude Codeを家庭教師に: 弱点対策問題集
弱点分析結果と公式 Exam Guide PDF (Version 0.1)、さらに非公式のpaullarionov/claude-certified-architectを読ませて、Markdownの問題集を作りました。
解答欄では4択すべてについて「なぜ選んだか、なぜ選ばなかったか」を書き、「回答に自信があるか、あてずっぽうか」も記録するようにしました。
このMarkdownファイルをエディタで解き、Claude Codeに読み込ませ、さらに弱点を分析させました。
選択の理由を書くことで判断の根拠がつくようになっていき、「自信があって正解はよいが、自信があって間違いはまずい」などの指摘もなされて、何らかの思い込みがあることも明らかになっていきました。
またこの中で何度やっても「few-shotとexplicit criteria」の使い分けがよくわからなかったので、専用の集中問題集や集中解説もClaude Codeにやらせました。解説を抜粋しますと次のようになります。
1. 3つの型(これだけ覚える)
- few-shot①(形を見せる) … 出力の形が安定しない(format / structure / tone)。言葉で説明しても形にならない。
- few-shot②(考え方を見せる) … 明確なケースは正しいのに、曖昧なケースで外す。判断の“さじ加減”を教えたい。
- criteria(基準を書く) … 何が該当かが未定義で、全体的にブレる/誤検知+見逃しが出る。
few-shot①=「こう出力して(手本)」/few-shot②=「こう考えて(推論の手本)」/criteria=「こういう時だけ該当(ルール)」。
2. 一番効く見分け方:「明確なケースはもうできているか?」
- 明確なケースも含めて全体的にブレる → 基準が無い → criteria
- 明確なケースはOK・曖昧なケースだけ外す → 基準はある → few-shot②
理由: 基準が足りないなら、明確なケースでも外すはず。曖昧なケース“だけ”外すのは、基準は足りていて、足りないのは1文に書けない判断だという証拠。
ところが「few-shotとexplicit criteria」の使い分けは最後まで納得がいかず、よくわからないままでした。
とはいえClaude Code相手なら、何度も何度も「わからない」「もう一度解説し直して」と言っても、怒ったり呆れたりせずに付き合ってくれます。
Anthropic Academyの公式模擬試験(再試験)
弱点を潰した後で、再度Anthropic Academyの公式模擬試験をやりました。すると 934/1000 (56/60) と、「これで900点取ることが最低ライン」というところまでいきました。
| SCENARIO | SCORE | RESULT |
|---|---|---|
| Multi-Agent Research System | 15/15 (100%) | ✓ |
| Code Generation with Claude Code | 14/15 (93%) | ✓ |
| Customer Support Resolution Agent | 13/15 (87%) | ✓ |
| Claude Code for Continuous Integration | 14/15 (93%) | ✓ |
なお、問題の出題順や選択肢の順番は前回受けたときと変わっていましたが、内容そのものは同じでした。
Claude Codeを家庭教師に: 公式模擬試験外のシナリオ
ところでExam Guide PDF (Version 0.1)に載っている試験のシナリオは次の通りです。
- Customer Support Resolution Agent
- Code Generation with Claude Code
- Multi-Agent Research System
- Developer Productivity with Claude
- Claude Code for Continuous Integration
- Structured Data Extraction
本試験ではこの6つのシナリオのうちの4つがランダムに出題される、とのことなのですが、公式模擬試験には「Developer Productivity with Claude」と「Structured Data Extraction」が入っていませんでした。
そこでClaude CodeにExam Guide PDF (Version 0.1)と非公式のpaullarionov/claude-certified-architectを読ませて、「Developer Productivity with Claude」と「Structured Data Extraction」シナリオにおける問題集を作らせ、弱点対策と同じように対策しました。
本試験がなぜダメだったのか
ここまでやったら大丈夫だろう…と思っていたのですが冒頭に書いた通り、合格ライン720/1000のところ669/1000というスコアでダメでした。60問中38問正解、正解率68%でした。内訳は次の通りです。
| ドメイン | 正解率 | 結果 |
|---|---|---|
| Agentic Architecture & Orchestration | 73% | ✓ |
| Tool Design & MCP Integration | 64% | ⚠️ |
| Claude Code Configuration & Workflows | 43% | ⚠️ |
| Prompt Engineering & Structured Output | 64% | ⚠️ |
| Context Management & Reliability | 77% | ✓ |
問題や答案の見直しはできないので、自力の答え合わせはできません。
出題範囲
- Structured Data Extraction
- Code Generation with Claude Code
- Customer Support Resolution Agent
- Developer Productivity with Claude
出題されたシナリオは、たしかこの4つでした。半分が公式模擬試験で出題されないシナリオ「Developer Productivity with Claude」「Structured Data Extraction」でした。
ただし、これはあくまで「シナリオ」つまり問題の背景はどういうものなのかということであり、例えば模擬試験の「Multi-Agent Research System」シナリオで扱っていた問題がまったく出ないわけではないはずです。例えば「Structured Data Extraction」シナリオで形を変えて出てきていた、という気がしました。
つまりシナリオで考えるのではなく、ドメインとそのタスクステートメントで考えるべきでした。
なお前述の通り、udemyの非公式模擬試験ではこのドメイン別の出題という形になっていました。
出題内容
公式模擬試験と同じ問題・同じ選択肢は 一切 出ませんでした。
つまり、問題と答えを暗記しても まったく 意味がありません。
筆者は公式模擬試験を何度もやりましたが、そのうち答えを覚えてしまったため、実際は最初に取った600点台が実力なのに、幻の900点台になっていた可能性が高いと思います。
本番の問題を解くには、問題と答えを覚えるのではなく、意味を理解しなければいけません。
そのために同じ問題を漫然と繰り返すのではなく、自力で(あるいはClaude Codeに頼んで)問題集を作るべきだと思いますが、後述の落とし穴がありました。
自作問題集の落とし穴
Claude Codeに資料を与えて「問題集を作ってください」と頼めばそれらしいものはいくらでも作ってくれます。
しかし単に「作って」だけだと、選択肢の質があまりよくなかったと思います。
正答の1つ以外、3つともあからさまに「これはないだろ」とわかってしまう答えのこともあり、自習しながら「これはあんまり質がよくないなぁ…」と感じていました。
そう気づいた段階で、何らかの方法で問題集の質を上げる努力もすべきでした。
udemyの非公式模擬試験もExam Guideから生成したそうですが、同じような落とし穴にハマっていたのでは、と今なら思います。
本番の選択肢はそんなに甘くありません。
逆に「これはないだろ」という答えが1つあるいはまったくないこともザラです。
あのときは有効な方法だけど、このときは無効な方法である、のような厳しい選択肢もあったと思います。
まとめ
本稿では、CCA-Fに挑戦するまでと、不合格に終わったのは何故なのか、という分析を書きました。
「毎日使っていても本気で使っていなかった」というのはもちろんのこと、「間違った勉強をしていたので、だんだん試験を甘く見るようになっていった」というところの結果だったと思います。
しかし、それなりに時間をかけて取り組んだことは決して無駄ではなかったと思います。
試験で学んだことを現在進行中のプロジェクトに盛り込み、再受験可能となる6か月後まで、しっかりと身につけていこうと思います。
Author
はやりの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



