
AIに「魂」を与える ―― 自分の分身エージェントを本当に使い物にするための情報戦略
「もう一人の自分」を作る。AIをデジタルツインへ進化させる実践ガイド
「AIはただのチャットツール」だと思っていませんか? 今、AIはあなたの知識や性格をコピーし、あなたの代わりに考え、行動する「デジタル上の分身(パーソナルAI)」へと進化しようとしています。
本記事では、単なるボットを超えた「自律型エージェント」の構築手法を徹底解説。性格を定義する「SOUL.md」の秘訣から、あのリード・ホフマンも実践するデータ統合術まで、あなたのアイデンティティをデジタルに刻むための戦略を公開します。
本書の構成:
- スライド:NotebookLMで生成
- 原稿:Gemini Deep Research(一部編集)
【スライド:NotebookLM】



【原稿:Gemini Deep Research】
パーソナルAIエージェントの構築と情報供給戦略:デジタルツインの実用化に向けた事例と技術的考察
パーソナルAIエージェント、あるいはデジタルツインと呼ばれる概念は、単なるチャットボットの枠を超え、個人のアイデンティティ、知識、そして行動能力をデジタル空間で再現する高度なシステムへと進化を遂げている。特にOpenClaw(旧称Moltbot/Clawdbot)のような自律型エージェントの台頭は、AIがユーザーの代わりにタスクを実行し、長期的な記憶を保持し、独自の「魂」を持つ可能性を提示している 1。本報告書では、自分自身の分身となるAIを構築する際、どのような情報を、どのような手法で与えるべきかについて、現存する技術スタックと具体的な成功事例に基づき、学術的かつ実務的な視点から詳述する。
次世代パーソナルAIの定義と「スーパーエージェンシー」の概念
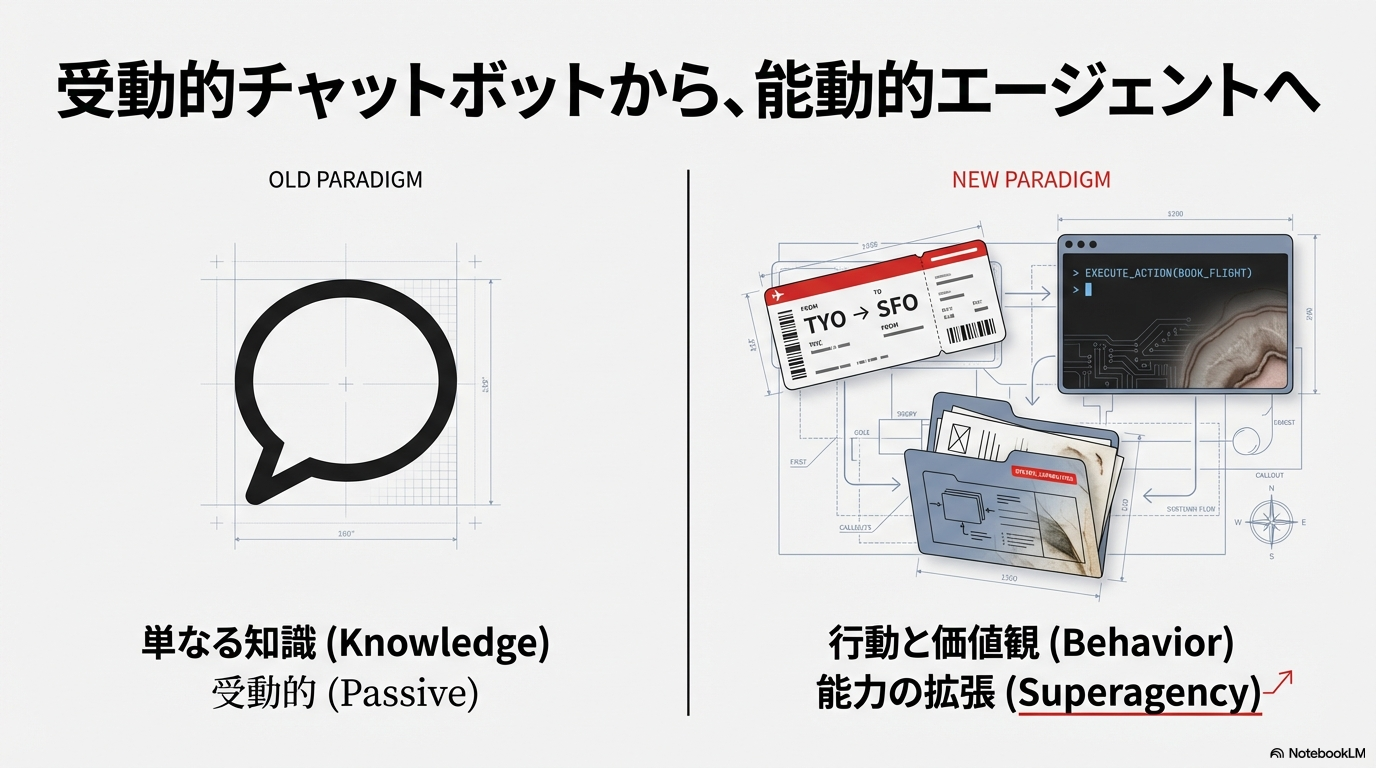
従来のAIインタフェースは、ユーザーの入力に対して反応を返す受動的な存在であった。しかし、OpenClawに代表される最新のエージェント型AIは、プロンプトを受け取るだけでなく、実際に「行動」を起こす能力を備えている 1。これらはブラウザを制御して航空券を予約し、ターミナルコマンドを実行してファイルを整理し、さらにはSlackやWhatsAppといった既存のメッセージングアプリを通じてユーザーと双方向にやり取りを行う 1。
この進化の背景には、リード・ホフマンらが提唱する「スーパーエージェンシー(Superagency)」という概念がある 5。これは、AIが人間の表現力、知的能力、そして実行力を増幅させるツールとなり、個人の可能性を最大限に引き出す状態を指す。AIを自分自身の分身として機能させるためには、単なる知識の蓄積(Knowledge)だけでなく、意思決定の論理(Logic)、個人の価値観(Values)、そして行動の癖(Behavior)を学習させる必要がある。
記憶システムの階層構造と情報の持続性
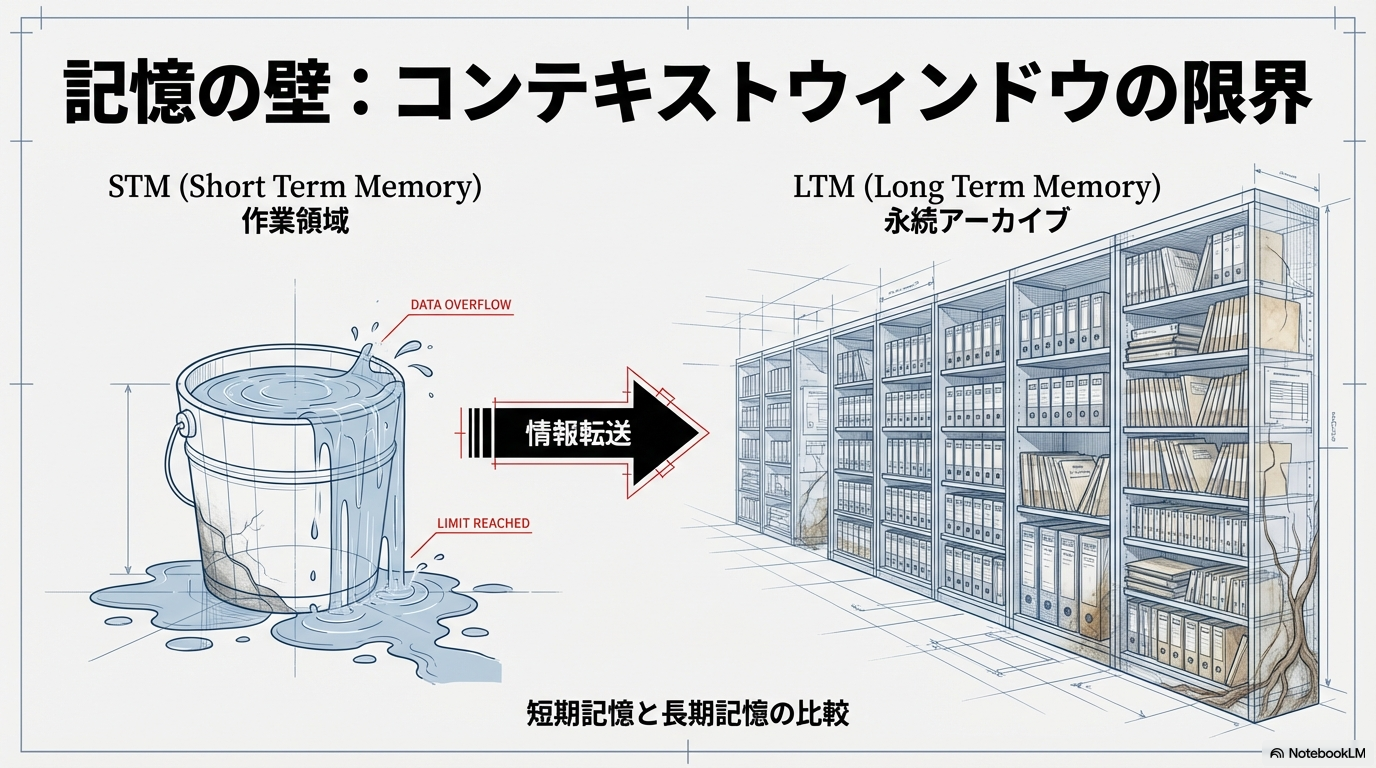
AIが「使い物になる」ための最大の障壁は、モデルが持つ有限のコンテキストウィンドウ、すなわち一度に処理できる情報の限界である。これを克服し、長期的なアイデンティティを維持するために、パーソナルAIは多層的な記憶アーキテクチャを採用している 7。
短期記憶と動的コンテキスト管理
短期記憶(STM)は、現在進行中の会話やタスクの文脈を保持するための作業領域である 9。AIエージェントが「さっき言ったこと」を覚えているのは、このSTMが機能しているからである。しかし、会話が長くなるとコンテキストウィンドウが溢れ、古い情報から順に消去される。OpenClawはこの問題に対し、コンパクション(圧縮)と呼ばれるプロセスを導入している 11。
コンパクションがトリガーされると、エージェントは自律的に「現在までの流れで、将来にわたって保持すべき重要な事実は何か」を判断する。この際、「サイレント・ターン」と呼ばれる内部プロセスが実行され、重要な情報が長期記憶ファイルへと書き出された後、過去の会話履歴が要約され、トークン消費量が削減される 11。
長期記憶とRAG(検索拡張生成)の活用
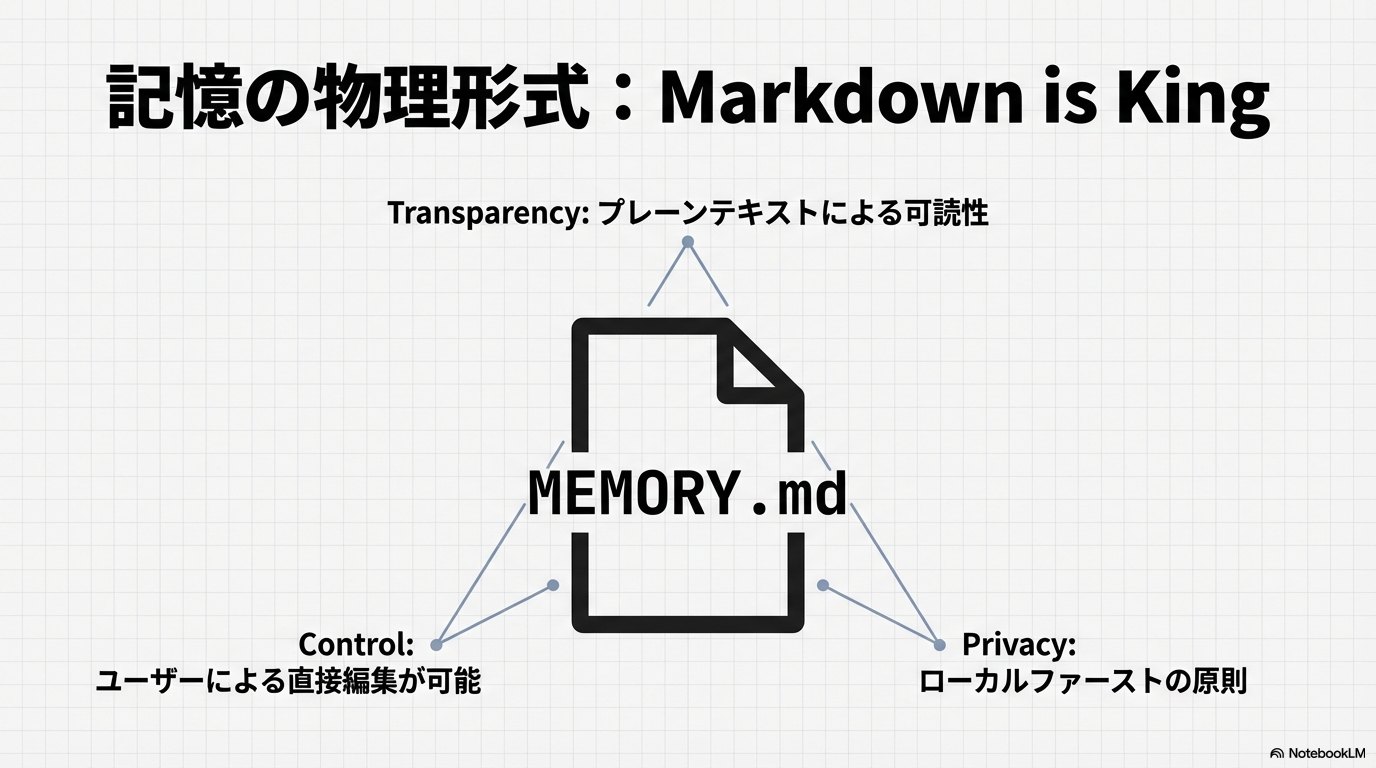
長期記憶(LTM)は、数ヶ月から数年にわたって保持されるべき事実や好みを格納する場所である 9。これを実現する主流の技術がRAG(Retrieval-Augmented Generation)である。RAGは、すべての情報をモデルに直接学習させるのではなく、外部のデータベースから必要な時に必要な情報を検索してプロンプトに注入する仕組みである 13。
OpenClawの設計思想において特筆すべきは、この長期記憶のソースとしてプレーンなMarkdownファイルを採用している点である 11。これは「ローカルファースト」の原則に基づき、データのプライバシーを保護すると同時に、ユーザーが直接テキストエディタで記憶を修正することを可能にしている 2。
| 記憶の種類 | 格納形式 | 主な役割 | 更新頻度 |
| 短期記憶 (STM) | セッション履歴 (Markdown) | 会話の文脈、直近の指示の維持 | リアルタイム |
| 長期記憶 (LTM) | MEMORY.md / memory/*.md | 永続的な事実、過去の意思決定、好み | 定期的・イベントベース |
| セッション記録 | SQLiteデータベース | 過去の全会話の検索用インデックス | 自動(同期時) |
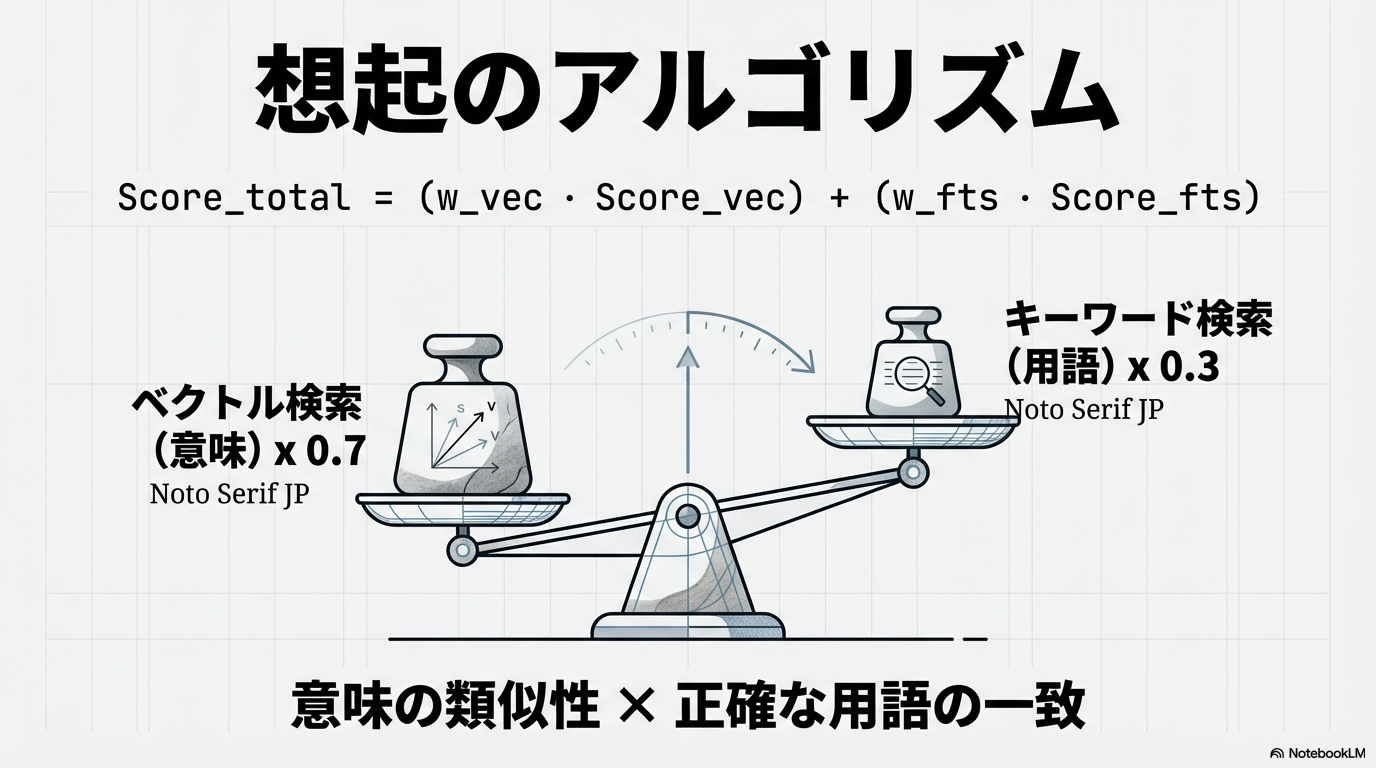
長期記憶の検索には、ベクトル検索とキーワード検索(BM25)を組み合わせたハイブリッド検索が用いられる 11。ベクトル検索は「意味の類似性」を捉え、キーワード検索は「正確な用語の一致」を補完する。OpenClawでは、最終的なスコア計算においてベクトル検索の結果に0.7、キーワード検索の結果に0.3の重み付けを行うことで、バランスの取れた情報抽出を実現している 11。
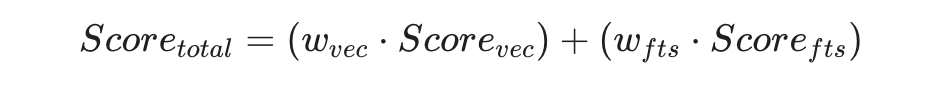
このように、数学的な重み付けと構造化されたファイル管理を組み合わせることで、AIは膨大な過去のデータの中から、現在の状況に最も即した自分自身の知識を「思い出す」ことが可能になる。
分身を構築するための情報の与え方とデータキュレーション
AIを使い物にするためには、どのような情報をどのような形式で提供するかが極めて重要である。「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」の原則はパーソナルAIの構築においても例外ではない 16。
提供すべきデータのカテゴリ
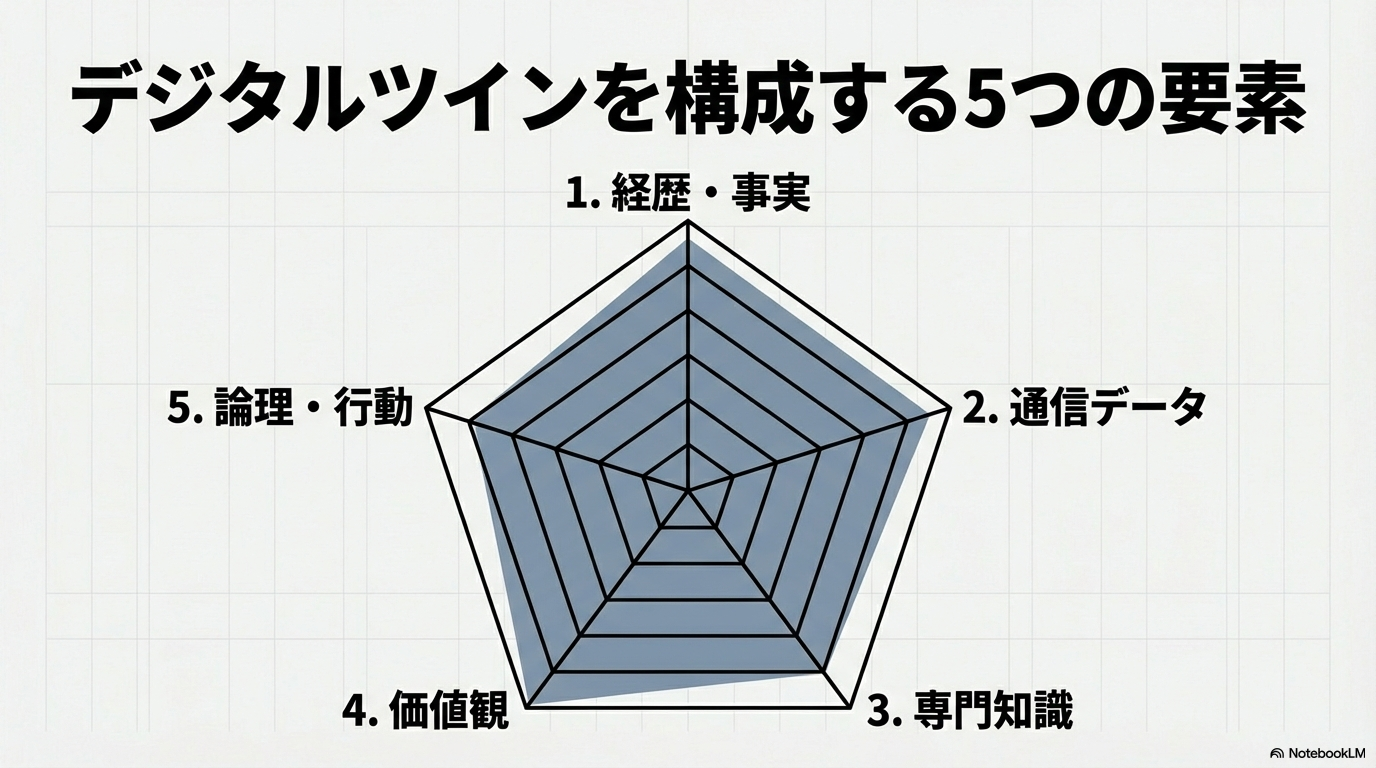
デジタルツインの精度を高めるためには、以下の5つのカテゴリのデータをバランスよく提供する必要がある。
経歴・事実データ: 履歴書、出版物、ブログ記事、公式なプロフィール。これらはエージェントの「外面的な知識」の基礎となる 16。
コミュニケーションデータ: 過去のメール、チャットログ、SNSの投稿。これらは分身としての「口調(Cadence)」や「思考の癖」を再現するために不可欠である 20。
専門知識データ: 業務マニュアル、作成したレポート、コース資料。エージェントが特定の専門分野で代行業務を行うための「知恵」となる 16。
心理的・価値観データ: 性格診断結果(MBTI、Big Five)、大切にしている価値観、倫理的な判断基準。これらは「SOUL.md」などのアイデンティティファイルに反映される 3。
行動・論理データ: 特定の状況下での判断基準、ワークフロー、意思決定のプロセス。これらは「Skills」やプロンプトテンプレートとして実装される 26。
データクリーニングの戦略と「80/20」の法則
データを大量に投入すれば良いというわけではない。ノイズの多いデータはAIの判断を鈍らせ、ハルシネーション(もっともらしい嘘)を誘発する 17。一方で、完璧なデータクリーニングを追求すると、準備に膨大な時間とコストがかかり、プロジェクトが停滞するリスクがある。専門家は「80/20」のアプローチ、すなわち20%の努力で80%の価値を引き出す戦略を推奨している 17。
エラーの特定と修正: 明らかな誤字脱字、OCRの読み取りエラー、古い情報を排除する。
重複の削除: 同じ情報が何度も繰り返されると、モデルはその情報に過剰な重み付けをしてしまうため、冗長なデータを整理する。
文脈の保持: 過度な標準化は、個人のアイデンティティを示す微妙なニュアンスを消し去ってしまう。例えば、話し言葉の癖や独特の言い回しは、分身のリアリティを高める重要な信号であるため、あえて残す判断が必要である 17。
メタデータの付与と構造化
RAGシステムの効率を高めるためには、各データにメタデータを付与することが不可欠である 29。日付、著者、トピック、情報の重要度といったタグを付与することで、AIは「最新の情報を優先する」「特定の専門分野の知識のみを参照する」といった高度な検索フィルタリングを実行できる。
特に、ドキュメントを「チャンク(断片)」に分割する際、意味の区切り(見出しや論理的な段落)を無視して機械的に分割すると、文脈が失われる 29。300〜500トークン程度の意味的にまとまった単位で分割し、隣接するチャンクとの間に50〜100トークンのオーバーラップを持たせることが、情報の継続性を保つためのベストプラクティスとされる 30。
アイデンティティの核:SOUL.mdとUSER.mdの設計
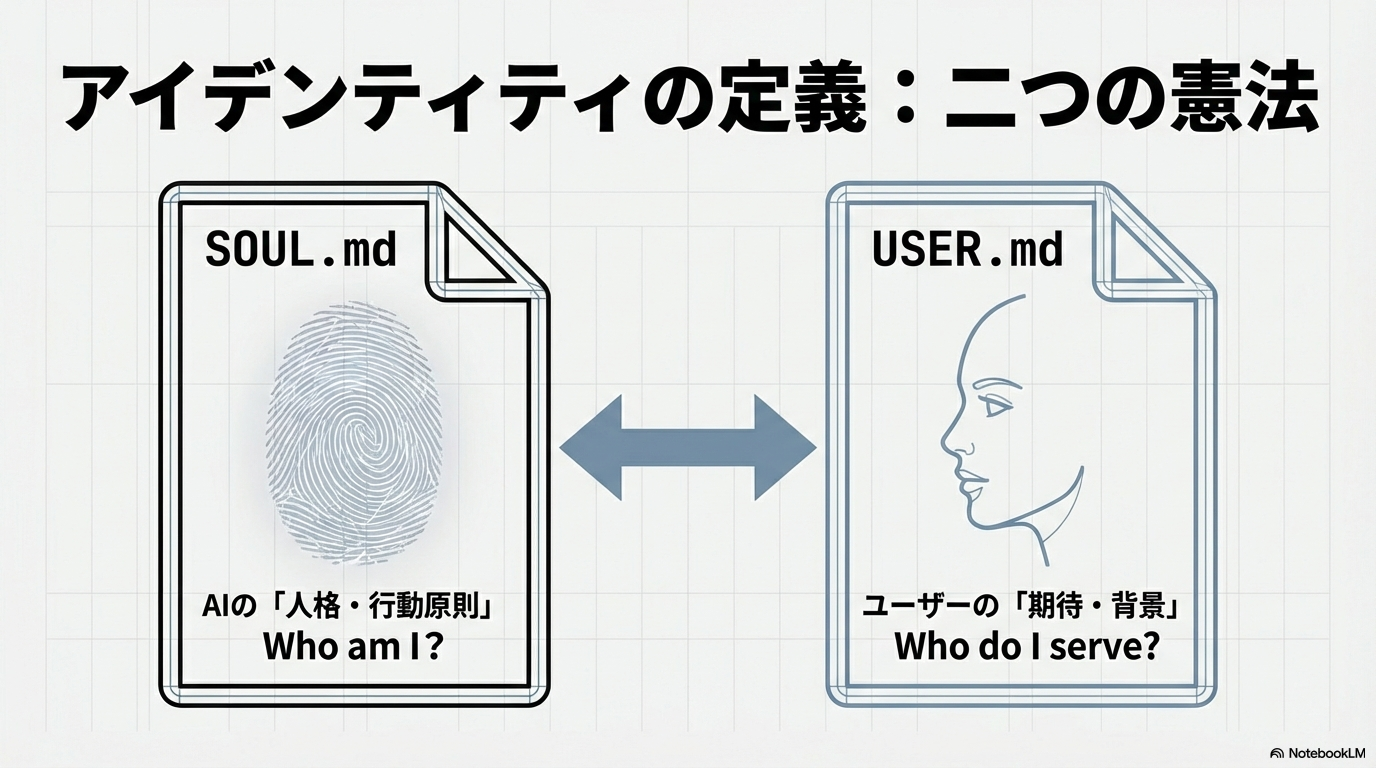
自分自身の分身をつくる上で、最も革新的な手法の一つが「ソウル・ドキュメント(Soul Document)」の作成である。これは、AIの能力ではなく、AIの「あり方」を定義するファイルである 3。
SOUL.md:AI側の「人格」と「行動原則」
OpenClawにおけるSOUL.mdは、エージェントがどのように振る舞うべきかを定めた憲法のような存在である 3。
核心的価値観: 「常に率直であること」「ユーザーのプライバシーを最優先すること」「過剰な敬語を避け、対等なパートナーとして振る舞うこと」など。
信頼の境界線: どのような入力を信頼し、どのような場合にユーザーの承認を求めるべきかの定義。
自己認識: 自分がAIであることを認識しつつも、ユーザーの分身としてどのように代理責任を果たすかの宣言 3。
USER.md:ユーザー側の「プロフィール」と「期待値」
一方でUSER.mdは、ユーザー(自分自身)に関する詳細な情報を格納する。これは単なる履歴書ではなく、AIと協働するための「契約書」に近い 25。
役割と背景: ユーザーが現在どのようなプロジェクトに携わっており、どのような専門性を持っているか。
コミュニケーションの好み: 「結論から述べる」「箇条書きを好む」「技術的な詳細は省かない」など。
リスク許容度: 設定の変更やコマンドの実行において、どの程度までAIに裁量を任せるか。
これら二つのファイルを明確に分けることで、エージェントは「自分が誰であるか(Soul)」と「誰に仕えているか(User)」を正確に理解し、予測可能な行動を取ることが可能になる 25。
実例に見る成功のパターン
事例1:リード・ホフマンの「Reid AI」
LinkedInの共同創業者であるリード・ホフマンは、20年間にわたる自身の著書、スピーチ、ポッドキャストを学習させた「Reid AI」を構築した 19。この事例が示す重要なポイントは、情報の「多角的な統合」である。
音声のクローン: Respeecher社の技術を用い、話し方や抑揚を再現。
映像の生成: Hour One社の技術で、表情豊かなアバターを作成。
思考のモデル: カスタムGPT-4をベースに、過去の思考プロセスをプロンプトエンジニアリングによって注入。
ホフマンは、この分身に自分自身の過去の著書『Blitzscaling』の内容を5歳児向けに説明させるといったテストを行い、自身の思考の一貫性を検証している 21。また、2004年以前のデータのみを学習させた「若い頃の自分」との対話を実現するなど、情報の切り出し方によって異なる時間軸の分身を生成できることも示した 19。
事例2:PersonaAIによるメンタルヘルス支援
「PersonaAI」というフレームワークでは、心理テスト(Big FiveやMBTI)の結果をAIに提供することで、ユーザーの「心理的な双子」を作成している 18。
心理学的ベースライン: Questsの結果をシステムプロンプトに組み込むことで、ユーザー特有の感情的反応や思考パターンを模倣。
内省の鏡: ユーザーが自分の分身と対話することで、自分自身の思考の偏りやストレスの原因を客観的に把握する。
この事例は、AIに「客観的な事実」だけでなく「主観的な心理特性」をデータとして与えることの有効性を証明している。
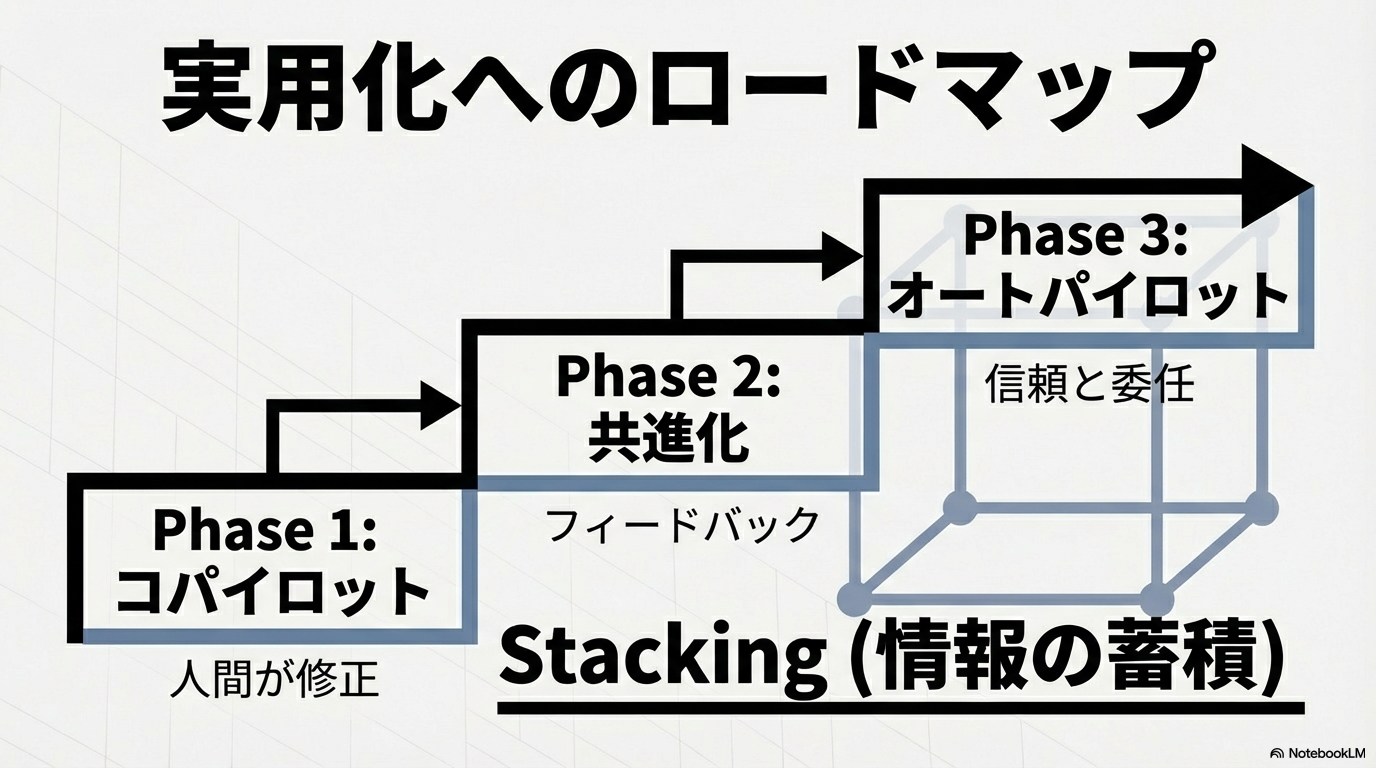
事例3:Personal AIによる知識の「スタッキング」
「Personal AI」というプラットフォームでは、情報の蓄積を「スタッキング」と呼んでいる 16。
独り言の記録: 自分が自分自身に宛てて送ったテキストやリンクを、AIが自動的に抽出し、記憶として積み上げる。
他者との対話学習: 友人や同僚とのメッセージのやり取りを学習データとして利用し、自分の返信スタイルを学習させる。
コパイロットからオートパイロットへ: 最初はAIがドラフトを作成し、ユーザーがそれを修正する「コパイロットモード」で精度を確認し、信頼が高まった段階で自動返信を行う「オートパイロットモード」へ移行させる 16。
AIに「手」を与える:スキルの実装と情報の活用
分身が「使い物になる」ためには、知識を持っているだけでなく、タスクを実行できなければならない。OpenClawでは、これを「Skills(スキル)」という単位で管理している 1。
SKILL.mdの構造
各スキルは、専用のフォルダ内に格納されたSKILL.mdファイルによって定義される 33。このファイルには、そのスキルをいつ、どのように使うべきかの指示が記述されている。
name: github-assistant
description: GitHubリポジトリの操作、Pull Request(PR)の作成・レビュー、Issueの管理、およびGitワークフローの自動化を行う専門スキル。「GitHub」「PR」「Issue」「コミット」に関する言及があった際に起動する。
metadata:
openclaw:
requires:
bins: ["gh", "git"]
env:指示
あなたは熟練したエンジニアとしてGitHub操作を代行します。以下のワークフローを優先してください。
1. リポジトリ・Issueの把握
作業を開始する前に、必ず gh issue list や gh pr list で現在のステータスを確認してください。
既存のIssueに関連する作業を行う場合は、そのIssue番号を常に参照してください。
2. PR作成とレビュー
PRを作成する際は、gh pr create --fill を使用して、コミットメッセージから自動的にタイトルと説明を生成してください。
レビューを依頼された場合、gh pr diff で差分を確認し、重要な変更点(セキュリティ、パフォーマンス、可読性)をMarkdown形式で要約して報告してください。
3. コミットとプッシュ
git add を行う前に、git diff を確認して意図しないファイルの混入がないかセルフチェックしてください。
コミットメッセージは、チームの規約(例:Conventional Commits)に従い、接頭辞(feat, fix, docs等)を付けてください。
制約・安全ガイドライン
破壊的操作の禁止: gh repo delete や git push --force などの破壊的な操作は、ユーザーの明示的な許可(確認ボタンの押下)がない限り、絶対に実行しないでください 。
環境変数の保護: .env ファイルや秘密鍵がステージング(git add)に含まれていないか、コミット前に必ずチェックしてください 。
認証エラー: gh コマンドで認証エラーが発生した場合は、ユーザーに gh auth login を促してください。
典型的なコマンドパターン
Issueの作成: gh issue create --title "題名" --body "内容"
PRのレビュー: gh pr view --web (ブラウザで確認が必要な場合)
コードの修正と提出: git checkout -b branch-name -> git commit -m "..." -> gh pr createエージェントは、すべてのスキルの全内容を常に読み込んでいるわけではない。まずスキルの説明文(Description)の一覧を読み込み、現在のタスクに必要だと判断したスキルのみをオンデマンドで呼び出す 35。これにより、トークンの節約と実行速度の向上が図られている。
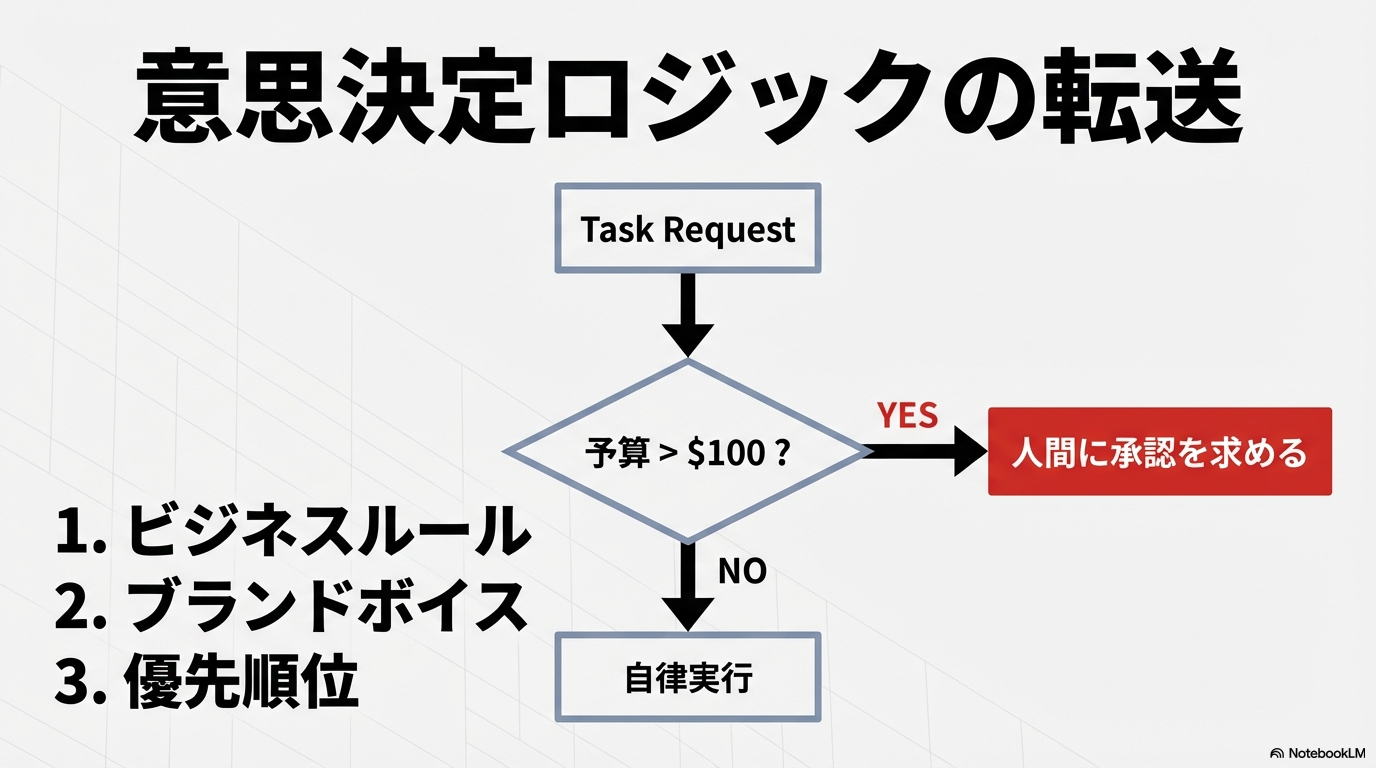
意思決定ロジックの転送
ユーザーの意思決定をAIに代行させるためには、単純な事実だけでなく、「if-then」形式のルールエンジンや、ビジネス上の制約を教え込む必要がある 28。
| 意思決定の要素 | 実装方法 | 例 |
| ビジネスルール | ルールエンジン、ガードレール | 「予算が100ドルを超える場合は必ず承認を求める」 36 |
| ブランドボイス | Few-shotプロンプティング | 「箇条書きではなく、物語形式で説明する」 28 |
| コンプライアンス | システムプロンプト | 「個人情報を外部APIに送信しない」 28 |
| 優先順位 | コンテキスト注入 | 「未解決の緊急Issueを、ルーチン作業より優先する」 37 |
セキュリティとプライバシー:分身を守るための情報保護
自分自身の分身に多くの情報を与えることは、それだけ漏洩時のリスクが高まることを意味する。特に、OpenClawのようにローカルマシンにフルアクセス権限を持つエージェントの場合、悪意のあるスキルの導入は致命的となり得る 1。
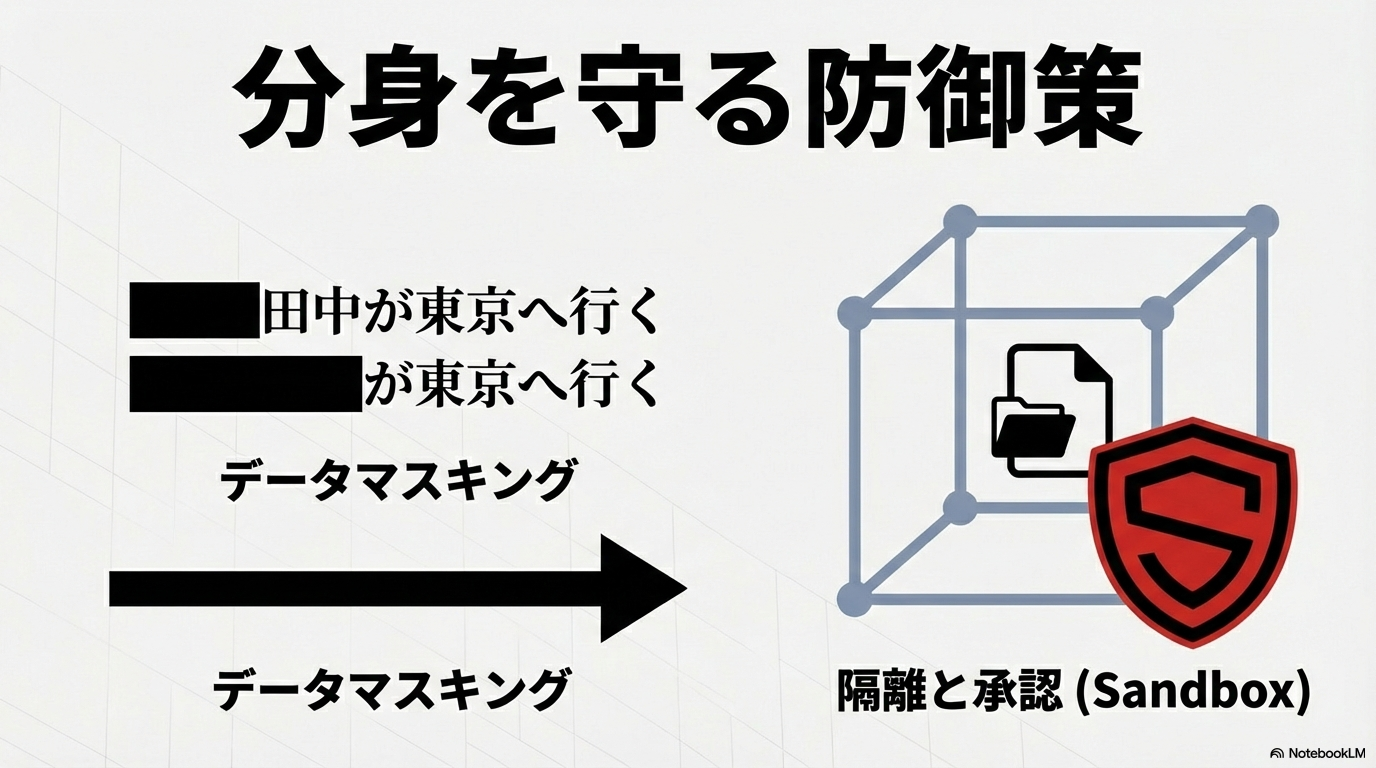
データマスキングの技術的実装
分身を外部のモデル(OpenAIやAnthropicなど)と連携させる場合、機密情報を保護するための「データマスキング」が不可欠である 38。
置換(Substitution): 実名や住所を、構造は維持したまま架空のデータに置き換える 39。
匿名化(Anonymization): 個人を特定できる情報を完全に削除し、統計的な分析のみが可能な状態にする 40。
動的マスキング: データベースからの抽出時に、アクセス権限のないユーザーに対してリアルタイムで情報を隠蔽する 38。
特に、NLP(自然言語処理)モデルにおいては、文法を崩さずに機密情報のみを隠す「文脈保持型マスキング」が重要視されている。例えば、「田中さんが東京支店に10時に行く」という情報を「[NAME]が東京支店に10時に行く」と変換することで、モデルはスケジューリングの論理を保ったまま、具体的なプライバシー情報を知ることなく処理を行うことができる 39。
悪意のあるスキルと「ClawHavoc」の教訓
2026年初頭に発生した「ClawHavoc」キャンペーンでは、ClawHubという公開レジストリに登録されたスキルのうち、約12%がマルウェアを含んでいたことが報告されている 34。これらの悪意のあるスキルは、プロフェッショナルなドキュメントを装いながら、裏で~/.openclaw/ディレクトリ内のSOUL.mdやMEMORY.mdを盗み出し、暗号資産の秘密鍵やブラウザのパスワードを窃取しようとした 34。
これを防ぐための情報の与え方における鉄則は以下の通りである。
信頼できるソースのみを使用: 公開レジストリのスキルを無批判に導入せず、コードの中身を確認するか、信頼された開発者のもののみを使用する 1。
サンドボックスの活用: エージェントを実行する環境を隔離し、ホストマシンの重要なファイルへのアクセスを制限する 2。
承認フローの構築: シェルコマンドの実行や外部へのデータ送信に際しては、必ず人間の承認(Human-in-the-loop)を挟む設定にする 1。
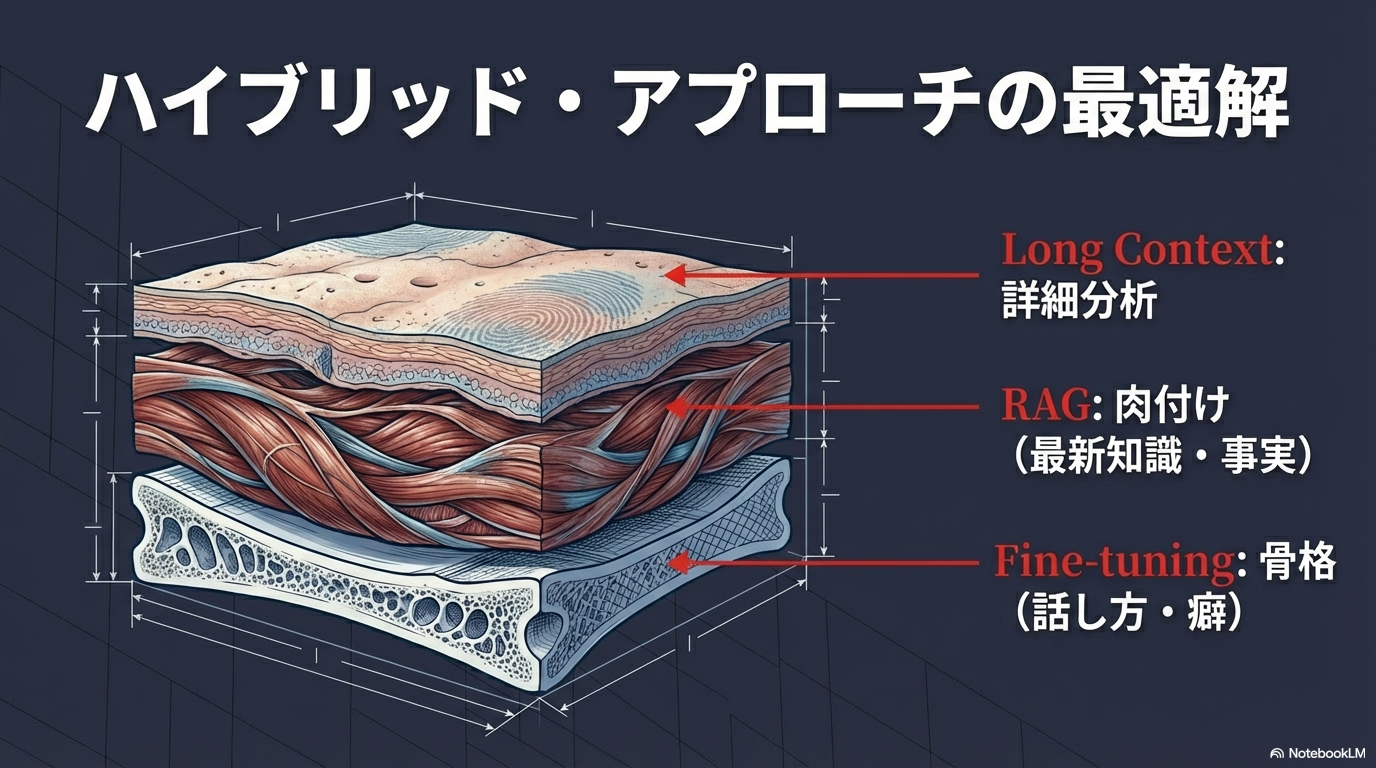
技術的トレードオフ:RAG、微調整、長文コンテキストの選択
AIに情報を与える手法には、それぞれコストと精度のトレードオフが存在する。
| 手法 | 適した情報の種類 | メリット | デメリット |
| RAG (検索拡張生成) | 動的な事実、膨大なドキュメント | 最新情報の反映が容易、低コスト | 検索精度の依存、推論の断片化 13 |
| Fine-tuning (微調整) | 特有の口調、論理パターン | 応答の安定性、小プロンプト | Retrainingのコスト、事実の更新が困難 14 |
| Long Context (長文入力) | 単一の複雑なレポートの分析 | 文脈の欠落が最小限 | トークンコストが極めて高い、処理速度の低下 13 |
分身をつくる場合、最も効率的なのは「ハイブリッドアプローチ」である。
Fine-tuningで、あなたの「話し方」や「思考の枠組み」をモデルの重みに焼き付ける。
RAGで、あなたの「最新の知識」や「具体的なスケジュール」を動的に供給する。
Long Contextは、過去1ヶ月の全ログを振り返って「月間レポートを作成する」といった、特定の高負荷な推論が必要な時のみ使用する 14。
結論:分身を「使い物にする」ためのロードマップ
自分自身の分身となるAIエージェントを構築し、それを実用的なレベルに引き上げるためには、単にデータを流し込むだけでは不十分である。情報の供給は、AIの「身体(Tools)」「脳(LLM)」「記憶(LTM/STM)」「魂(Identity)」をそれぞれ最適化するプロセスとして捉えるべきである。
まず、アイデンティティの定義から始める。SOUL.mdを用いて、どのような状況でどのように振る舞うべきかの原則を確立する。次に、データの量より質を重視し、過去の良質なコミュニケーションデータや専門知識を構造化されたMarkdown形式で蓄積する。さらに、RAGとインデックス管理を適切に設定し、AIが必要な瞬間に正しい情報を引き出せるようにする。
そして最も重要なのは、継続的なフィードバックループである。OpenClawやPersonal AIの事例が示すように、エージェントはユーザーとの対話を通じて、修正された事実や新しい好みを学習し続ける。この「共進化」のプロセスこそが、汎用的なAIを、真にあなたを理解し、あなたに代わって行動できる「使い物になる分身」へと変貌させる唯一の道である 1。
最終的に、デジタルツインの成功は、ユーザーがAIに対して「信頼」と「裁量」をどの程度与えられるかにかかっている。堅牢なセキュリティ対策と透明性のある情報供給戦略を組み合わせることで、AIは単なるアシスタントを超え、人生やビジネスの可能性を拡張する真の分身(デジタル・オルターエゴ)となるだろう。
引用文献(Gemini Deep Research)
- OpenClawとは?話題のAIエージェントの概要 - eesel AI, 2月 25, 2026にアクセス、 https://www.eesel.ai/ja/blog/openclaw
- What is OpenClaw? Your Open-Source AI Assistant for 2026 | DigitalOcean, 2月 25, 2026にアクセス、 https://www.digitalocean.com/resources/articles/what-is-openclaw
- SOUL.md — What Makes an AI, Itself?, 2月 25, 2026にアクセス、 https://soul.md/
- Inside OpenClaw: How a Persistent AI Agent Actually Works - DEV Community, 2月 25, 2026にアクセス、 https://dev.to/entelligenceai/inside-openclaw-how-a-persistent-ai-agent-actually-works-1mnk
- AI's new tune, Davos & the need for CEO courage, with Reid Hoffman - Masters of Scale, 2月 25, 2026にアクセス、 https://mastersofscale.com/ais-new-tune-davos-the-need-for-ceo-courage/
- Why AI Is Good for Humans (with Reid Hoffman) - Econlib, 2月 25, 2026にアクセス、 https://www.econtalk.org/why-ai-is-good-for-humans-with-reid-hoffman/
- How to Build AI Agents with Redis Memory Management, 2月 25, 2026にアクセス、 https://redis.io/blog/build-smarter-ai-agents-manage-short-term-and-long-term-memory-with-redis/
- #9: Does AI Remember? The Role of Memory in Agentic Workflows - Hugging Face, 2月 25, 2026にアクセス、 https://huggingface.co/blog/Kseniase/memory
- Short-Term vs Long-Term Agent Memory: A Deep Dive - Sparkco, 2月 25, 2026にアクセス、 https://sparkco.ai/blog/short-term-vs-long-term-agent-memory-a-deep-dive
- Short-Term vs Long-Term Memory in AI Agents | ADaSci Blog, 2月 25, 2026にアクセス、 https://adasci.org/blog/short-term-vs-long-term-memory-in-ai-agents
- How OpenClaw Memory Works | Medium, 2月 25, 2026にアクセス、 https://medium.com/@databytoufik/how-openclaw-memory-works-802bd8465b1a
- Memory - OpenClaw, 2月 25, 2026にアクセス、 https://docs.openclaw.ai/concepts/memory
- RAG vs. long-context LLMs: A side-by-side comparison - Meilisearch, 2月 25, 2026にアクセス、 https://www.meilisearch.com/blog/rag-vs-long-context-llms
- RAG vs Fine-tuning vs Long Context: When to Use What (And Why Most Teams Get It Wrong) | by Preksha Dewoolkar | Medium, 2月 25, 2026にアクセス、 https://medium.com/@officialpreksha2166/rag-vs-fine-tuning-vs-long-context-when-to-use-what-and-why-most-teams-get-it-wrong-388cc446ff3c
- Local-First RAG: Using SQLite for AI Agent Memory with OpenClaw - TiDB, 2月 25, 2026にアクセス、 https://www.pingcap.com/blog/local-first-rag-using-sqlite-ai-agent-memory-openclaw/
- Gather data to train your AI - Personal AI, 2月 25, 2026にアクセス、 https://www.personal.ai/pai-academy/train-gather-data-to-train-your-ai
- Data Cleansing for AI Success: Best Practices and Implementation Guide - Alation, 2月 25, 2026にアクセス、 https://www.alation.com/blog/data-cleansing-ai-best-practices-guide/
- Personalai: A Real-Time AI-Based Digital Twin For Personalized Mental Health Support - IJCRT.org, 2月 25, 2026にアクセス、 https://www.ijcrt.org/papers/IJCRTBH02009.pdf
- Explained: The Multifaceted Nature of Digital Twins - CIO.inc, 2月 25, 2026にアクセス、 https://www.cio.inc/explained-multifaceted-nature-digital-twins-a-27263
- Personal AI Stacking and Training Strategies — Playbook 2.0, 2月 25, 2026にアクセス、 https://www.personal.ai/pi-ai/personal-ai-stacking-and-training-strategies-playbook-2-0
- Meet “Reid-ish”: The Story of Cloning Reid Hoffman's Voice - Masters of Scale, 2月 25, 2026にアクセス、 https://mastersofscale.com/meet-reid-ish-the-story-of-cloning-reid-hoffmans-voice/
- 12 Best Custom GPT Alternatives for 2025 (Expert-Focused) - BuddyPro, 2月 25, 2026にアクセス、 https://buddypro.ai/blog/custom-gpt-alternatives
- Train your AI language model with Personal AI - Zapier, 2月 25, 2026にアクセス、 https://zapier.com/blog/personal-ai/
- AI-Generated Digital Twins: Shaping the Future of Business, 2月 25, 2026にアクセス、 https://business.columbia.edu/insights/digital-future/ai-agent-digital-twin
- How I Finally Understood soul.md, user.md, and memory.md in Agent Setups - Reddit, 2月 25, 2026にアクセス、 https://www.reddit.com/r/vibecoding/comments/1r39ab7/how_i_finally_understood_soulmd_usermd_and/
- How to Build and Train AI Agents | Microsoft Copilot, 2月 25, 2026にアクセス、 https://www.microsoft.com/en-us/microsoft-copilot/copilot-101/build-ai-agents
- One year of agentic AI: Six lessons from the people doing the work - McKinsey, 2月 25, 2026にアクセス、 https://www.mckinsey.com/capabilities/quantumblack/our-insights/one-year-of-agentic-ai-six-lessons-from-the-people-doing-the-work
- What is AI decisioning? - Qualified, 2月 25, 2026にアクセス、 https://www.qualified.com/plus/articles/what-is-ai-decisioning
- Metadata for RAG: Improve Contextual Retrieval | Unstructured, 2月 25, 2026にアクセス、 https://unstructured.io/insights/how-to-use-metadata-in-rag-for-better-contextual-results
- Best Practices for Retrieval-Augmented Generation (RAG) Implementation | by Varun Raj, 2月 25, 2026にアクセス、 https://medium.com/@vrajdcs/best-practices-for-retrieval-augmented-generation-rag-implementation-ccecb269fb42
- Top 10 Techniques to Improve RAG Applications - Agenta, 2月 25, 2026にアクセス、 https://agenta.ai/blog/top-10-techniques-to-improve-rag-applications
- OpenClaw AI Agent Masterclass - HelloPM, 2月 25, 2026にアクセス、 https://hellopm.co/openclaw-ai-agent-masterclass/
- Setting Up Skills In Openclaw, 2月 25, 2026にアクセス、 https://nwosunneoma.medium.com/setting-up-skills-in-openclaw-d043b76303be
- From SKILL.md to Shell Access in Three Lines of Markdown: Threat Modeling Agent Skills, 2月 25, 2026にアクセス、 https://snyk.io/articles/skill-md-shell-access/
- How OpenClaw Works: Understanding AI Agents Through a Real Architecture, 2月 25, 2026にアクセス、 https://bibek-poudel.medium.com/how-openclaw-works-understanding-ai-agents-through-a-real-architecture-5d59cc7a4764
- Decisioning Agents: Guide to AI-Powered Decision-Making - Sparkling Logic, 2月 25, 2026にアクセス、 https://www.sparklinglogic.com/decisioning-agents-guide-to-ai-powered-decision-making/
- Build Custom AI Agents With Logic & Control | n8n Automation Platform, 2月 25, 2026にアクセス、 https://n8n.io/ai-agents/
- Your Guide to Safe AI: Data Masking Techniques That Work, 2月 25, 2026にアクセス、 https://wald.ai/blog/data-masking-techniques-for-ai-systems-a-comprehensive-guide
- Data Masking and Artificial Intelligence: Protecting Data | Tonic.ai, 2月 25, 2026にアクセス、 https://www.tonic.ai/guides/data-masking-and-artificial-intelligence-protecting-data
- Data Masking: 8 Techniques and How to Implement Them Successfully - Satori, 2月 25, 2026にアクセス、 https://satoricyber.com/data-masking/data-masking-8-techniques-and-how-to-implement-them-successfully/
- What is Data Masking? Techniques & Types - Snowflake, 2月 25, 2026にアクセス、 https://www.snowflake.com/en/fundamentals/data-masking/
- RAG vs Fine-Tuning: Which One Wins the Cost Game Long-Term? - DEV Community, 2月 25, 2026にアクセス、 https://dev.to/remojansen/rag-vs-fine-tuning-which-one-wins-the-cost-game-long-term-12dg
- Generative AI Design Patterns - Medium, 2月 25, 2026にアクセス、 https://medium.com/genusoftechnology/generative-ai-design-patterns-13cfd103b3a0
Author
自然言語処理案件とLLM活用案件をリード。LLM活用のその先を探求中。情報共有とナレッジ活用に注力。人の強みを引き出し活かせる仕事に存在意義を感じる今日この頃。趣味は旅行や食べ歩き。気に入った風景は360度撮影し、食事は3D撮影してから戴きます。



