
Neo4j GraphRAGリトリーバーをMCPとして実装

本稿は Implementing Neo4j GraphRAG Retrievers as MCP Server の和訳記事です。
VectorCypher検索やその他のGraphRAGリトリーバーでMCPツールボックスを拡張する
Model Context Protocol (MCP) は、アプリケーションがLLMにコンテキストを提供する方法を定義するオープンスタンダードであり、LLMが標準化されたツールを通じて外部データや機能にアクセスできるようにします。
そのようなMCPサーバーの一つに、エージェントがNeo4jデータベースにクエリを実行できるようにするMCP Neo4j Cypherサーバーがあります。このMCPサーバーにより、LLMによって生成された(Text2Cypherによる)読み取りおよび書き込みのCypherクエリを、Cypher構文を直接学習する必要なく、データベーススキーマ情報の取得と実行が可能になります。このように、Text2Cypherアプローチは、自然言語と従来のグラフクエリとの間に、透過的で効果的な橋渡しを提供します。
しかし、ベクトル検索は異なる課題をもたらします。Text2Cypherとは異なり、ベクトル検索は単に自然言語をCypherクエリに翻訳するだけではありません。代わりに、データとクエリの埋め込み(エンベディング)を生成し、それらをベクトルインデックス内で比較する必要があります。このため、プロセスはそれほど透過的ではありません。結果を意味のある形で解釈するためには、どのテキスト埋め込みモデルが埋め込みの作成に使用されたか、そしてクエリがどのようにそれらと照合されるかを知ることが重要です。効果的なベクトル検索を設計するには、Cypher生成だけでなく、埋め込み管理と注意深いクエリの定式化も必要です。
これに対処するため、Neo4jはベクトル検索とCypherを組み合わせたGraphRAG VectorCypherRetrieverを提供しています。このブログ投稿では、このリトリーバーをMCPサーバーとして公開し、エージェントのための追加のツールとして利用可能にする方法を解説します。
MCPコードはGitHubで公開されています。
GraphRAGリトリーバーのMCPサーバーとしての公開
前述のとおり、テキスト埋め込みも生成する必要があるため、カスタムリトリーバーが必要です。なぜ単にLLMに埋め込みモデルをツールとして提供し、それをText2Cypherと組み合わせさせないのか、疑問に思うかもしれません。その理由は、現在、あるツールの出力を別のツールに渡す唯一の方法が、LLMコンテキスト自体を経由することだからです。しかし、埋め込みは高次元ベクトルであり、それらをLLMを経由してルーティングすることは、トークンと遅延(レイテンシ)の観点から非効率的でコストがかかります。
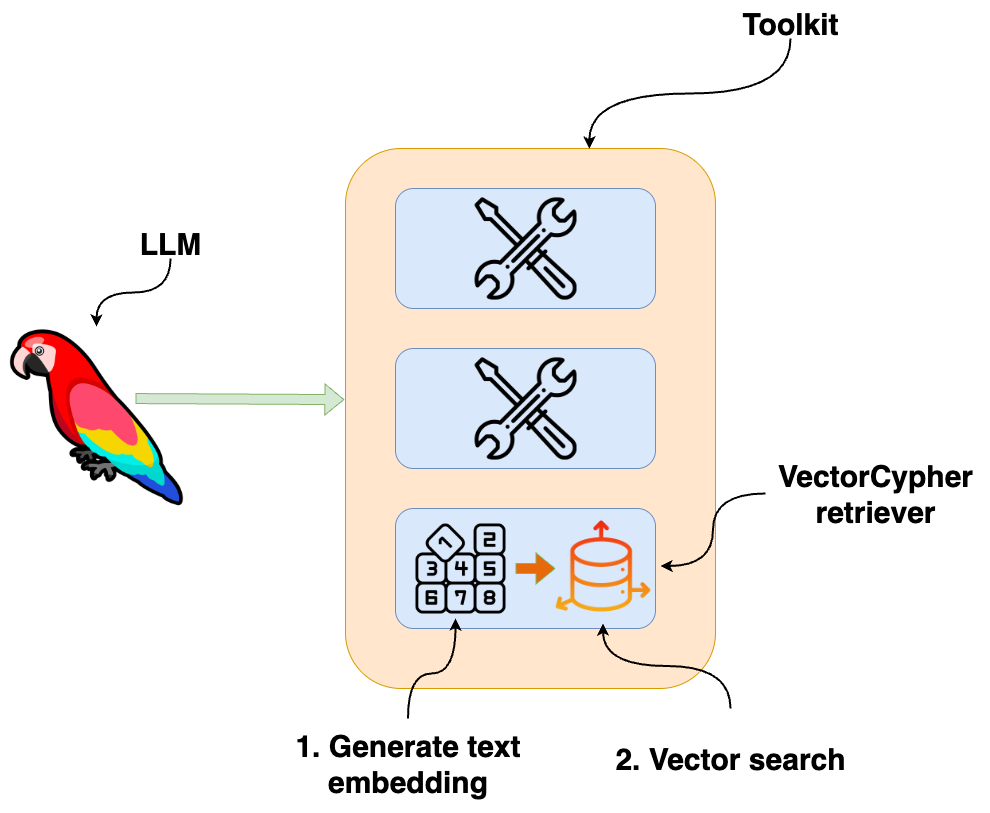
上記の図に示すように、より良いアプローチは、リトリーバーにワークフロー全体(埋め込みの生成とベクトル検索の実行)を処理させることです。これにより、埋め込みがLLMを通過することはなく、すべてが単一のツールインターフェースの背後にきれいに抽象化されます。
GraphRAG VectorCypher MCP
いよいよリトリーバーの実装です。私はMCPフレームワークの専門家ではないため、MCP Neo4j Cypherサーバーの構造(FastMCPで構築されています)をコピーし、それを適合させることから始めました。
埋め込みモデルを実装するための柔軟な方法が必要です。VectorCypherRetrieverをコードの変更なしに任意のモデルとMCP互換性を持たせるために、LangChainのinit_embeddings関数を活用します。この関数は、シンプルなprovider:model文字列を使用するため、異なる埋め込みモデルへの切り替えが信じられないほど簡単になります。
# Example
embedding_model = init_embeddings("openai:text-embedding-3-small")リトリーバーを機能させるために、以下のコンポーネントを定義する必要があります。
- Neo4jデータベース接続
- ベクトルインデックス名
- 検索用のCypherクエリ
これらの設定を構成した後、リトリーバーオブジェクトをサーバーを構築する関数に渡します。
embedding_model = init_embeddings(embedding_model)
driver = GraphDatabase.driver(db_url, auth=(username, password))
retriever = VectorCypherRetriever(
driver,
index_name=index_name,
embedder=embedding_model,
retrieval_query=retrieval_query,
neo4j_database=database
)
mcp = create_mcp_server(retriever, namespace)MCPサーバーは、LLMと、ツールとして公開される外部機能との間の橋渡し役を果たします。これらのツールを定義することで、サーバーはLLMがユーザーのクエリに答えるのを助けるために、それらの実行を要求することを可能にします。
このケースでは、単一のツールを公開します。それは、ベクトル検索を実行する関数です。
@mcp.tool(
name=namespace_prefix + "neo4j_vector",
annotations=ToolAnnotations(
title="Neo4j vector",
readOnlyHint=True,
destructiveHint=False,
idempotentHint=True,
openWorldHint=True,
),
)
async def vector_search(
query: str = Field(..., description="Natural language question to search for.")
) -> list[ToolResult]:
"""Find relevant documents based on natural language input"""
try:
result = vector_retriever.search(query_text=query, top_k=5)
text = "\n".join(item.content for item in result.items)
return ToolResult(content=[TextContent(type="text", text=text)])
except Neo4jError as e:
logger.error(f"Neo4j Error executing read query: {e}\n{query}")
raise ToolError(f"Neo4j Error: {e}\n{query}")
except Exception as e:
logger.error(f"Error executing read query: {e}\n{query}")
raise ToolError(f"Error: {e}\n{query}")要するに、この関数はNeo4jデータベースのためのセマンティック検索ツールとして機能します。LLMがこのツールの使用を決定すると、自然言語クエリをそれに渡します。その後、関数はベクトルリトリーバーを使用してデータベース内の関連性の高い上位5つのドキュメントを見つけ出し、その結合されたテキストコンテンツをLLMに返します。
この@mcp.toolデコレーターが、vector_search関数を利用可能なツールとして正式に登録するものです。ツールの説明は、LLMに明確な指示を提供するために、そのDocstringから自動的に生成されます。ツールについては以下の通りです。
- ツールの目的(「何をするか」): 関数のメインのDocstringがツールの全体的な説明になります。この高レベルな要約は、LLMにツールが何をするかを伝え、いつ使用すべきかを判断するのに役立ちます。
- ツールの入力(「どのようにするか」): 関数が必要とする各パラメータも記述する必要があります。これらの具体的な説明は、LLMに各入力に対してどのような情報を提供すべきかを正確に伝え、正しくツールを呼び出せるようにします。
さらに、ツールのアノテーションを定義できます。
name: ツールに一意の名前を与えます。readOnlyHint=True: このツールがデータの読み取りのみを行い、データベースへの変更を行わないことを約束します。destructiveHint=False: ツールが非破壊的であることを明示的に述べます。idempotentHint=True: 同じクエリでツールを複数回呼び出しても、同じ結果が得られ、追加の副作用がないことを意味します。「猫」を2回検索しても同じ結果が生成され、何も変更されません。openWorldHint=True: ツールが持つ知識源(Neo4jデータベース)が独立して更新される可能性があることをLLMに通知します。新しいデータが追加された場合、今日得られた回答は明日得られる回答とは異なる可能性があります。
Claude Desktopでのテスト
これで、Claudeデスクトップアプリケーションで以下の設定を使用してサーバーをテストできます。
このセットアップは、公開されている読み取り専用のNeo4j映画レコメンデーションデータベースに接続するように事前に構成されています。テキスト埋め込みモデルのためにOPENAI_API_KEYを入力するだけで済みます。
{
"mcpServers": {
"neo4j-dev": {
"command": "uv",
"args": ["--directory", "/path/to/servers/mcp-neo4j-vector-graphrag", "run", "mcp-neo4j-vector-graphrag", "--transport", "stdio", "--namespace", "dev"],
"env": {
"NEO4J_URI": "neo4j+s://demo.neo4jlabs.com:7687",
"NEO4J_USERNAME": "recommendations",
"NEO4J_PASSWORD": "recommendations",
"NEO4J_DATABASE": "recommendations",
"OPENAI_API_KEY": "sk-proj-",
"INDEX_NAME": "moviePlotsEmbedding",
"EMBEDDING_MODEL": "openai:text-embedding-ada-002",
"RETRIEVAL_QUERY": "RETURN 'Title: ' + coalesce(node.title,'') + 'Plot: ' + coalesce(node.plot, '') AS text, {imdbRating: node.imdbRating} AS metadata, score"
}
}
}
}moviePlotsEmbeddingインデックスは、埋め込まれた映画プロットデータに対する自然言語検索を可能にします。これをテストしてみましょう。
まとめ
昨年の検索システムが廃れるわけではありません。ただ、新しい形をとっただけです。エージェントの時代において、リトリーバーはモジュール式で、効率的で、標準化されたツールとしてラップされています。埋め込み生成とベクトル検索の複雑さをクリーンなMCPインターフェースの背後に抽象化することで、データ検索の低レベルな仕組みではなく、推論とオーケストレーションに集中するようにLLMを強化します。
エージェントはtext-embedding-3-smallの複雑さやベクトルインデックスの構造を知る必要はありません。呼び出すことができる強力なセマンティック検索ツールを持っていることを知っていればいいのです。同じ原則を適用して、他のGraphRAGリトリーバーや、任意のカスタムデータアクセスロジックを公開し、エージェントのための多用途で強力なツールボックスを作成することができます。
MCPコードはGitHubで公開されています。



