
elasticsearchでノード障害が起きたときの動作 #elastic

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
![]()
こんにちは。木内です。elasticsearchは分散アーキテクチャで可用性を確保するデータベースです。今回はelasticsearchクラスタでノード障害が起きたときに、どのような挙動を取るかについて解説します。
elasticsearchのプライマリシャードとレプリカシャード
elasticsearchのデータを考える際に、キーとなる要素は「プライマリシャード」と「レプリカシャード」です。それぞれ以下のような役割を果たします。
- プライマリシャード : ドキュメント(つまりインデックスに保存されるデータのうちの1つ)がelasticsearchに記録されるときに、あらかじめ定義された関数に従い、できるだけ分散されるようにプライマリシャードに配置されます。(elasticsearchクラスタの中に、インデックスごとに作成される)プライマリシャード数のデフォルト値は 5 です。
- レプリカシャード : それぞれのプライマリシャードはあらかじめ指定された数のレプリカシャードを保有しようとします。あるプライマリシャードのレプリカシャードは必ず別のノードに配置されます。レプリカシャード数のデフォルト値は 1 です。
4台のノードで構成されたelasticsearchクラスタにデータを書き込んだ場合のプライマリシャード、レプリカシャードの配置を模式的に示す図は以下のようになります。

この状態でelasticsearchを構成するノードのうち1台が故障し、アクセスできなかった場合はどうなるでしょうか。elasticsearchはアクセスできないプライマリシャードについて、自動的にレプリカシャードがプライマリシャードに昇格します。そののちに、昇格したプライマリシャードからデータが提供されます。以下の図を見ると、ノードの故障でアクセスできないプライマリシャード "a1" のレプリカシャードが自動的にプライマリシャードに昇格し、クライアントは正常なデータを受け取ることができることがわかります。
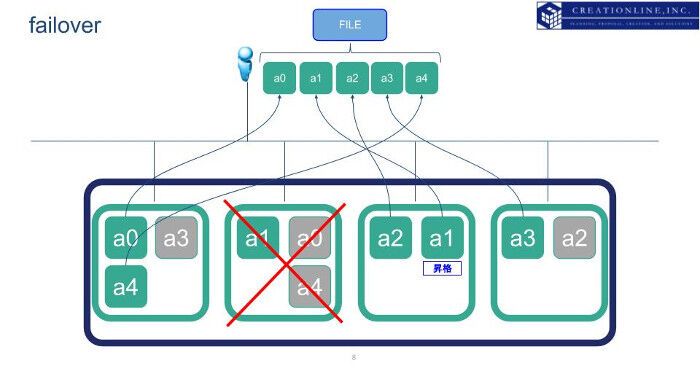
その後、昇格したプライマリシャード "a1" 、および "a0", "a4" はレプリカ数を維持するために新たなレプリカを生成します。
上記に述べた通り、レプリカシャードは必ず別のノードに作成されます。逆に言えば、2ノード以上elasticsearchクラスタにノードが存在しなければ、レプリカシャードを作成することはできず、ノードに障害が発生した場合には最悪データロストが発生する可能性があります。
elasticsearchクラスタにおけるマスターノード
では2ノードあればelasticsearchクラスタは冗長性を兼ね備えた状態になるでしょうか。残念ながら2ノードでは不十分です。少し回り道になりますが、順を追って説明いたします。
elasticsearchクラスタでは、参加するノードの一部を マスターノード として定義します。マスターノードはマスターになる候補のノードです。マスターノードのうち1台がマスターとして選出され、現在elasticsearchクラスタのメンバーにどのノードが参加しているかどうかを管理します。一方、通常データを読み書きするノードを データノード と呼びます。小さな elasticsearchクラスタではデータノードがマスターノードを兼任することが多いのですが、大規模な elasticsearch クラスタでは様々な理由から データノードとマスターノードを別のノードで行う構成が一般的です。
以下の図はデータノードとマスターノードを別のノードで構成したelasticsearchクラスタの例です。
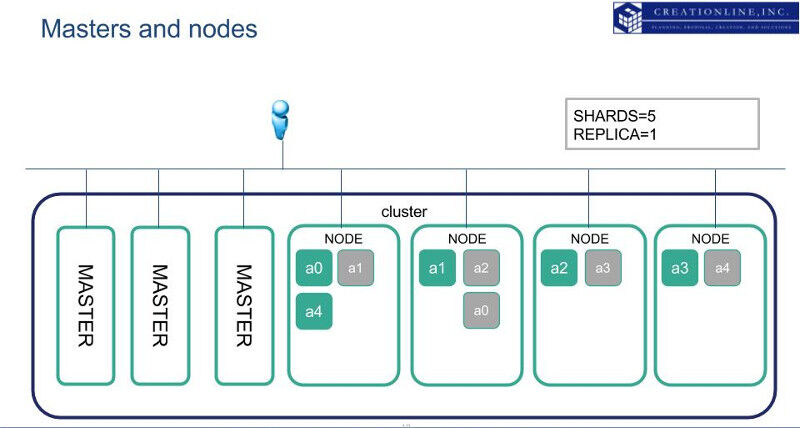
elasticsearchクラスタの中で最小限何ノードがマスターノードになるべきかは指標が存在します。この数は「クォーラム数」と呼んだりもします。以下の計算で求めることができます。
( マスター候補になるマスターノード数 ÷ 2 ) + 1
障害時に維持する最小マスターノード数
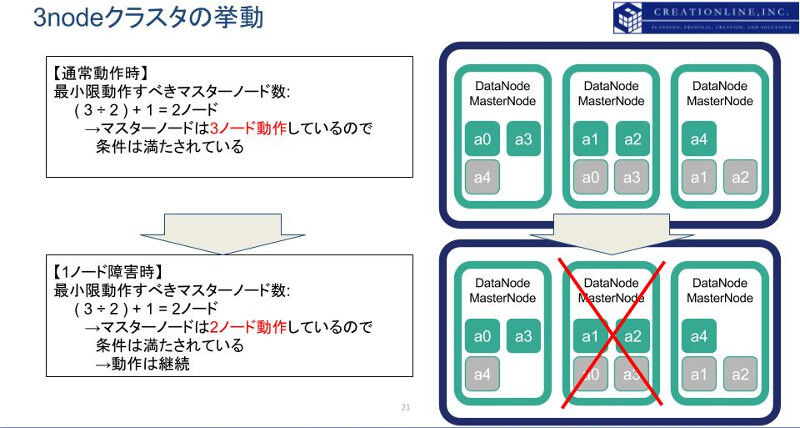
小さなクラスタで、データノードがマスターノードを兼任するような場合、3ノードで構成されるelasticsearchクラスタで最小限マスターノードとしてふるまうべきノード数は、 " ( 3 ÷ 2 ) + 1 = 2 "となります。実際の構成では3ノードともにマスターノードとして指定し、1ノードが障害でアクセスできない場合でも、マスターノードとして最小限必要な数である、2を満たすことができます。
より小さな構成である、2ノードではどうでしょうか。上記の式を用いて計算すると、 " ( 2 ÷ 2) + 1 = 2 " となり、elasticsearchクラスタ内の2ノードが動作している限りは計算通りの最小マスターノード数を満たすことができます。しかし2ノードのうち1ノードに障害が発生すると、マスターノードは1となり、最小マスターノード数である 2 を満たすことができません。結果として、elasticsearchクラスタは動作を停止してしまいます。
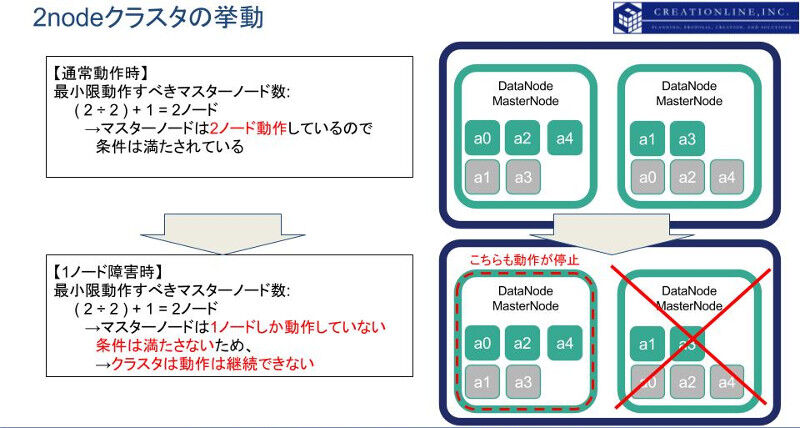
上図の通り、2ノードで構成されたelasticsearchクラスタは1ノードに障害が起きた際に、クラスタとして動作を継続することができません。これが、「2ノードのelasticsearchクラスタは十分な冗長性を有しない」理由です。ノード障害に耐性のあるelasticsearchクラスタを構成する場合は、最低3ノード以上で構成するようにしてください。
特殊な例: スプリットブレイン、アムネジアと、elasticsearchにおける対応
さて、ここから少し余談に入ります。elasticsearchと同様、複数のノードが連携して機能を提供するクラスタアプリケーションの運用にあたっては、各ノードの障害や、ノード間の接続が切断されることによって思いもよらぬ影響が出ることがあります。代表的なものとして、「スプリットブレイン(Split Brain)」、「アムネジア(Amnesia)」と呼ばれる現象があります。こちらについて簡単に触れるとともに、elasticsearchがどのようにこれらの現象を防いでいるかについてご紹介します。
今までは、最小限必要なマスターノードの数という要素のみでクラスタの状態について解説してきました。現実の世界はもう少し複雑です。例えば以下の図のようなクラスタを想像してみてください。ネットワークスイッチの末端に、elasticsearchクラスタの各ノードが動作しています。(ここではマスターノードの動作について説明するため、データノードの動作、データの保全性については割愛します。)
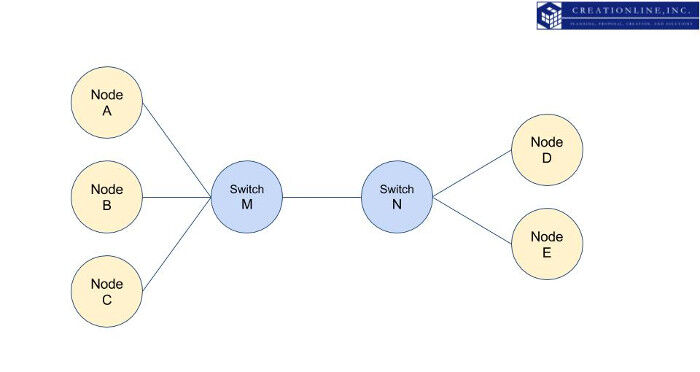
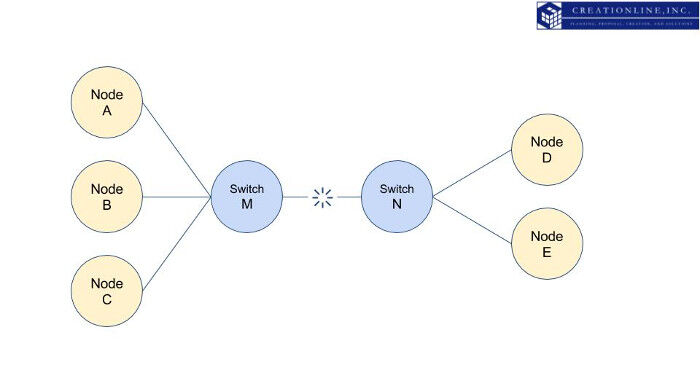
上図の状態から、スイッチNとスイッチMの間の通信に障害が起きた場合を想像してみましょう。ノードA,B,Cはお互いに疎通を確認することができますが、ノードD,Eとは通信することができません。同様に、ノードD,Eもお互いに疎通することができますが、ノードA,B,Cとは通信することができません。
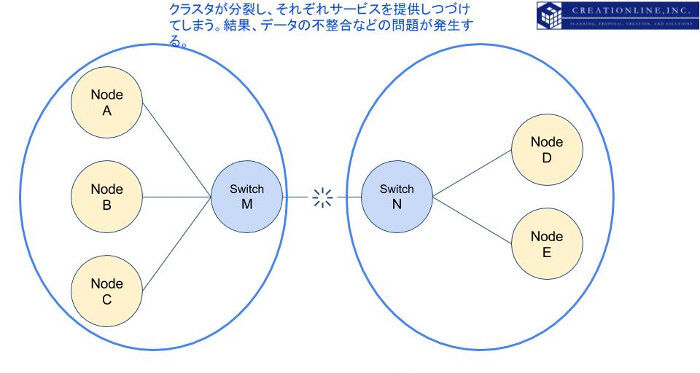
最悪のケースは、分断されたノードA,B,CおよびノードD,Eがそれぞれ独立したクラスタとしてサービスを提供し続けることです。少々表現がグロいですが、もともと1つだった脳みそが、2つに分かれてサービスを提供し続けることを意味し、このような現象を「スプリットブレイン(Split Brain)」と呼びます。
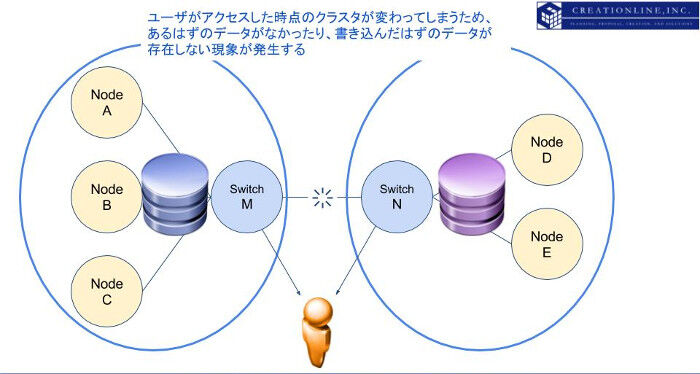
上記の分裂したサービスが、間欠的に、入れ違いにユーザに提供されていた場合はどうなるでしょう。ユーザがアクセスした時点によって、あるはずのデータがなかったり、書き込んだはずのデータが書き込まれていないように見えてしまいます。この現象を、「アムネジア(Amnesia, 健忘症の意)」と呼びます。
つまりクラスタを安定的に運用していくためには、諸々の理由によってクラスタが分断されたり、提供されるクラスタが頻繁に変更されるようなことが起きてはいけません。世の中には様々なクラスタ型ソフトウェアがありますが、様々な手法で安定的にクラスタサービスを継続提供する方法が考案されています。コンピュータ科学における主要な研究テーマの一つともなっています。
さてelasticsearchの場合はどうでしょうか。elasticsearchでは堅牢、かつシンプルな手法で生存するクラスタを選定しています。まず上に述べた「最小限何ノードがマスターノードになるべき」数を算出します。上図の例では5ノードですので、 " ( 5 ÷ 2 ) + 1 = 3 "となり、3ノードのマスターノードが動作すれば、クラスタは生存し、サービスが提供されることになります。
上記の例でelasticsearchの場合はどのような挙動を取るでしょうか。まずはノードAがマスター、ほかのノードがマスター候補となるマスターノードであるとします。図にすると以下のようになります。
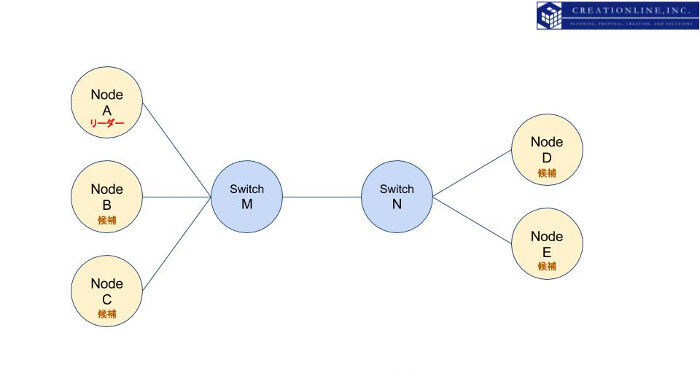
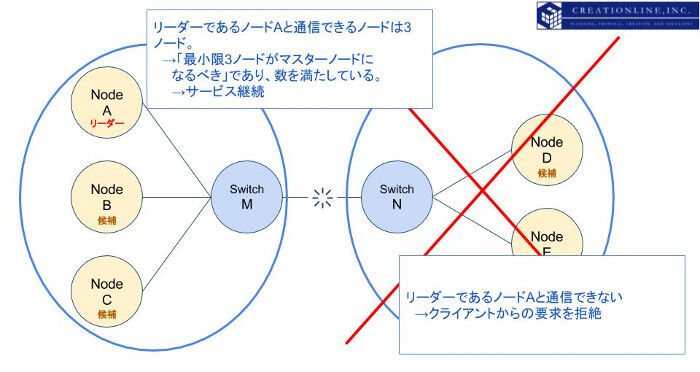
先の例と同様に、スイッチMとスイッチN間の接続が切断されたとします。まずマスターとなっているノードAはノードD,Eとの疎通ができなくなることを検知し、ノードD,Eを切断します。この時点でマスターになりうるマスターノードはノードA,B,Cです。3ノードあるため「最小限何ノードがマスターノードになるべき」数を満たしており、残存する3ノードでサービスを継続します。
一方、ノードD,EにおいてはマスターであるノードAおよびノードB,Cとの疎通が確認できない時点で「最小限何ノードがマスターノードになるべき」数である3ノードを満たすことができません。結果、ノードD,Eが新たなマスターになることはなく、クライアントからのリクエストに応答しなくなります。従って、残存してサービスを継続するのはノードA,B,Cのセットになります。
この状態でノードD,EはノードAとの疎通が不達となった直前までのデータを保持しています。ノードAとの疎通が回復次第、クラスタに再度参加し、データの回復措置が取られます。以下の図は上記の説明を模式化したものです。
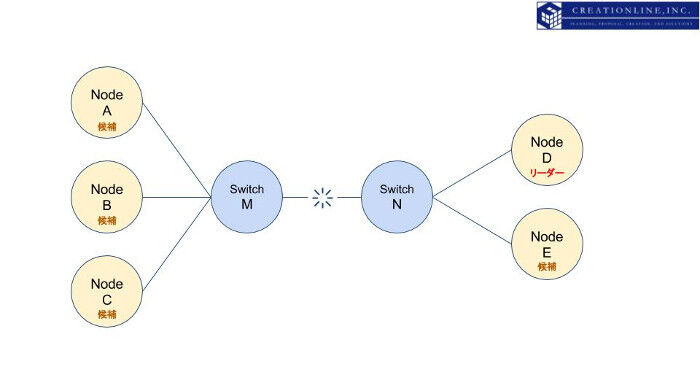
では逆のケースを考えてみましょう。マスターがノードDである場合にスイッチM-N間の通信が途絶した場合はどうなるでしょうか。
ノードA,B,C側ではマスターであるノードDとの疎通が取れなくなった時点で、クライアントからのリクエストに応答しなくなります。一定時間ののちに、残存するノードA,B,Cは「最小限何ノードがマスターノードになるべき」数である3ノードを満たしているため、Zenプロトコルによるリーダーエレクションを行い、新たなマスターが選出され、サービスを再開します。
一方、ノードD,E側では「最小限何ノードがマスターノードになるべき」数である3ノードを満たさなくなり、クライアントからの要求に応答しなくなります。上記と同様に、直前までのデータはノードD,E内に保持され、ノードA,B,Cとの疎通が回復次第、クラスタに再度参加し、データの回復措置が取られます。
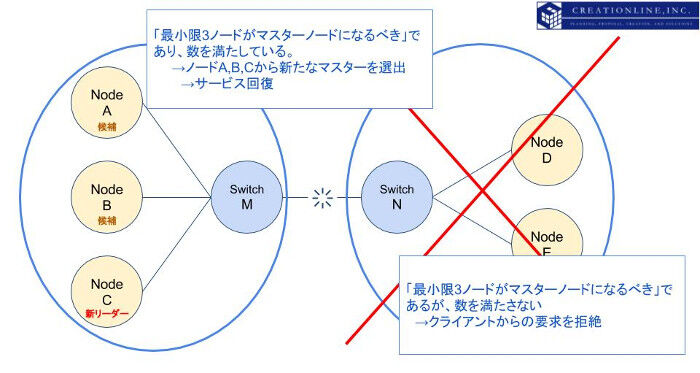
注意頂きたいのは、上記の説明はあくまでelasticsearchクラスタのサービス継続性についてのみ記述しており、実際にどの程度のデータノードがクラスタ内に生存するかによって、データロストの可能性が決まります。
最後に
elasticsearchを含めた分散アプリケーションは適切に設計すれば、極めて可用性の高いサービス提供を行うことができますが、設計によって意図しないサービス断を招く可能性もあります。特に1ノード、2ノードの場合はデータの損失、サービスの停止に十分ご注意ください。
Elastic blogでより詳細な記事が公開されています。こちらもぜひご参照ください。( Elastic blog - Leader Election, Why Should I Care? https://www.elastic.co/blog/found-leader-election-in-general )
では!



