
Neo4j 3.1 ハイライト #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
![]()
皆さま、今回は、Neo4j v3.1のハイライトを簡略に紹介します。遅いじゃないか、というお叱りには言い訳もありませんが、今回のリリースで最も注目を集めたのは、エンタープライズ向けのビッグなソリューションが混じっていたことかと思います。特に目玉ソリューションである高可用性の大規模分散クラスター(Causal Cluster)は開発者にとっては些か難解だったかもしれません。ここでは、なるべく平易な言葉を使って解説させて頂きます。
Neo4j v3.1のハイライト(2016年12月13日リリース)
- Causal Clustering Architecture
- Security Foundation
- Database Kernel and Operational Improvements
- Schema Viewer
- User-Defined Functions
- IBM POWER8 CAPI Flash
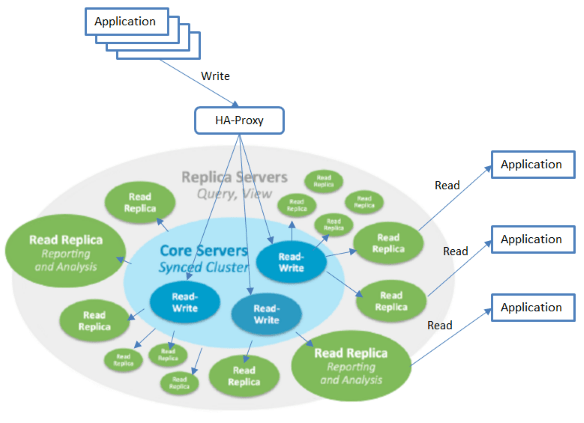
大規模分散クラスター(Causal Cluster)
今回、発表している大規模分散クラスター(Causal Cluster)は、Neo4jが「Causal Clustering Architecture」と呼んでいる仕組みです。この仕組みは、現実の分散データ処理において、高可用性の問題や性能拡張の問題に対して同時に解決策を具現化しています。イメージ的には、コアという部分で3台以上サーバ(奇数)の書き込み処理専用のクラスターを保ち、このコアと同期を取っている読み取り専用のレプリカーを用途に応じて増設できるようにしています。

図は、理解を助けるために、一部、追記しています。
「Causal Clustering Architecture」という言葉を見たときに、まず、Causalという言葉に困惑しましたが、色々調べている内に、コンピューターサイエンスから取ってきた言葉であることが分かりました。Causal system, Causal consistency, Causal clusteringとかという言葉も検索に引っ掛かります。分散処理に関わるある種の概念を表す言葉で、日本語にはどう訳したらいいのか分かりません。ここでは、これ以上深堀しないことにします。
コア(Core)
コアは、Raftという分散処理に関する論文をベースにしています。イメージ的には、従来のHAクラスターが更新系のクエリーのみを受けるようにしたような構成です。もちろん、高可用性ではありますが、あくまでも、Neo4jの大規模分散クラスター(Causal Cluster)の一部として機能します。
Raftは、コアの設計思想ですが、Neo4j社の発明という訳ではでありません。様々な分散処理システムで広く使われています。詳しいことは、下記を参照してください。
CONSENSUS: BRIDGING THEORY AND PRACTICE
では、コアとは、どのようなものなのでしょうか。そして、どのように振る舞うのででしょうか。
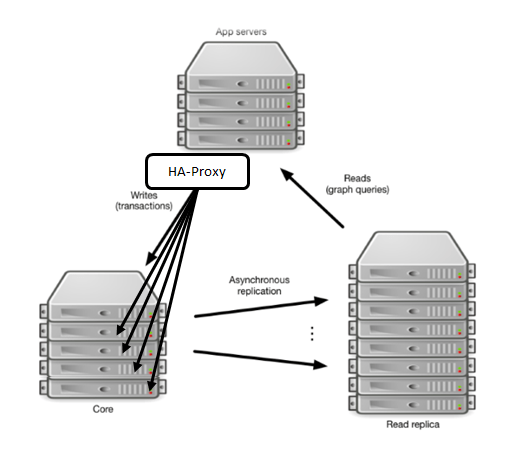
出典: causal-clustering/introduction
- コアは、最低でも3台以上の奇数のサーバで構成します。サーバを奇数にする理由は、リーダーを選ぶための取り決めによるものです。過半数以上の投票が集まるグループなかで「事前に決めているルール」を満たしているものがリーダーとして選ばれます。サーバやネットワークに障害が起きた場合、データの一貫性や安全を守るために、このルールはとても大事です。また、一般的にサーバ台数が多いと、可用性も高くなります。3台構成のクラスターでは、2台が同時に故障するか音信不通になると、リーダーを決めることができず、復旧までにサービスが中断される可能性があります。5台構成であれば、2台の同時障害にも耐えられます。
- クラスターは起動すると、その内1台をリーダーとして選出します。リーダーに問題が起きるか、クラスターがネットワーク的に分断された状態になると、お互いに投票を行って過半数の投票が集まるグループのなかで新しいリーダーを選出します。
- クラスターのなかでは、どのサーバもクエリを受けることができます。受けたクエリは、リーダーに転送します。この構造は、Neo4jならではの先進的な仕組みで、コアの前にHA-Proxyを構え、アプリケーションからのクエリをクラスター内のサーバに均等に割り振ることができます。アプリケーションは、クラスターが機能する限り、どのサーバがリーダーなのかを意識する必要がないとても便利な構成です。この仕組みは、HAクラスターを継承しています。
- リーダーのみが更新系のクエリをコミットする権限を持っており、コミットしたトランザクションは、即時にメンバーに伝えます。
- メンバーは、リーダーから通知を受けてトランザクションログをコピーして来て同期を取ります。
コアになるサーバの設定は、neo4j.confにて下記のように設定します。
dbms.mode=CORE
リードレプリカ
- レプリカは、コアにポーリングを繰り返すような形で最新のトランザクション処理を反映してデータの同期を取ります。
- レプリカは、アプリケーションからの読み込みリクエストに応答します。
- レプリカは、遠隔地のデータセンター間でも設定出来て、DR対策のためのバックアップ用途に使うこともできます。
- コアで障害が起きてもリーダの選出には参加しないし、フェイルオーバー先にはなりません。
レプリカになるサーバの設定は、neo4j.confにて下記のように設定します。
dbms.mode=READ_REPLICA
用途
大規模分散クラスター(Causal Cluster)は、HAクラスタ―では対応しきれないほどの大規模のグラフデータ処理の要求に対応するためのものであると言えます。もちろん、それなりの投資も必要になるでしょう。HAクラスターでも、スレーブノードを読み取りの用途で使ったりすることはできますが、それは、あくまでも資源の有効活用のレベルだと言っていいでしょう。HAクラスターでスレーブの存在意義は、あくまでも可用性を担保することが目的であり、性能拡張ではありません。
セキュリティ基盤(Security Foundation)
LDAPサポート
Neo4j v3.1では、LDAP認証が加わり、さらにネイティブのユーザ追加やロール設定(認可)が可能になりました。
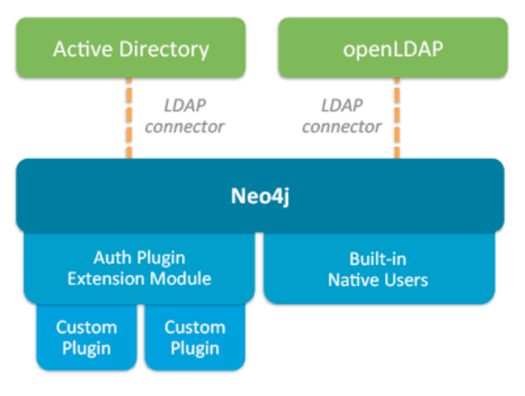
マルチユーザ及びロールベースのアクセス制限
複数のユーザを作成し、DBのなかで実行アクションの制限が可能になりました。
- reader:DBに対するread-only
- publisher:DBに対するread-write
- architect:DBに対するread-write及びインデクスに対するset/delete
- admin:DBに対するread-write及びインデクスに対するset/delete、クエリーのビュー、ターミネート
使い方も、とても簡単です。
下記の例は、Webインターフェースからユーザを作成し、publisherの権限を与えています。
次にmyuserでログインした場合、読み取りしかできないはずです。
$ CALL dbms.security.createUser('myuser', 'password')
$ CALL dbms.security.addRoleToUser('reader', 'myuser')
認証及び認可のためのプロシージャは、様々な種類が用意されています。
詳細は、マニュアルを参照してください。
Authentication and authorization
Neo4jブラウザーで実行中のクエリー管理
:queries APIを実行することでNeo4jブラウザー上で実行中のクエリー情報を一目瞭然にできるようになりました。
$ :queries

データベースカーネル及び運用性の向上(Database Kernel and Operational Improvements)
カーネルの改善
Neo4j 3.1では、効率的なスペース管理を含めた、DBカーネルの改善を行っています。ノード及び関係性IDは、クラスタ―がオンライン中に削除されたレコードから再割り当てされます。
遅延クエリー管理
admin権限者は、実行中のすべてのクエリリストとユーザ情報、開始時間、経過時間などが分かるようになりました。
$ CALL dbms.listQueries()

これによって、長時間終了しないクエリを削除可能です。
$ CALL dbms.killQueries(id)
新しいCLI
cypher-shellやneo4j-adminのような新しいCLIが追加されました。 cypher-shellは、Boltベースであり、アドホッククエリやスクリプト、Neo4jブラウザーの拡張などが可能です。
neo4j-adminは、初期パスワード作成、データベースのdump及びloadなど新しい機能を沢山実装しています。
スキーマビューア
Neo4j Webインターフェースから、グラフデータベースのスキーマ(データモデル)を見ることができるようになりました。
$ CALL db.sechema()
ユーザ定義のファンクション(User-Defined Functions)
ユーザ定義のファンクションが作成できるようになり、他にもいくつが改善が行わえています。
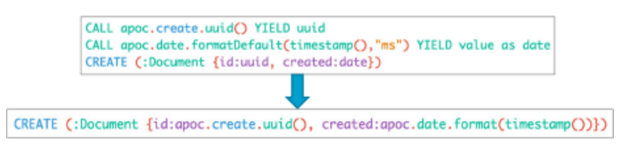
- Cypherでユーザが自分のファンクションを作成することがで可能
- 一般的な計算、ルール、変換、述語を表現するための有用性の向上
- Neo4j 3.0のストアドプロシージャのメカニズムが拡張
現在、細かいのファンクションの追加などまでは追っていまません。気になることがあれば、マニュアルを参照してください。
Neo4j IBM POWER8 CAPI Flash
IBM POWER8 CAPI Flashを公式サポートすることになりました。CAPI-Flashは、フラッシュメモリを使用し、RAM並みのパフォーマンスを達成できる技術のことです。IBM POWER8 CAPI Flashを通して桁外れの大規模グラフをインメモリ及びニアメモリでの展開することができます。但し、v3.1の段階では、CAPI Flash展開は、neo4j-adminコマンドやneo4j.confの一部の環境変数などでは完全には対応していません。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



