
Neo4j Sandbox紹介: Neo4jを活用したリアルタイムリコメンド #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
![]()
こんにちは!木内です。
一般的にパーソナルリコメンド(Amazonの「この商品を購入した人はこのような商品にも興味を持っています」のようなもの)の実装には大規模なデータセットを元に、機械学習のテクニックを駆使して実装する必要がありました。Neo4jを活用することで同じようなことを、より小規模なリソースで実装することができます。加えて今までのバッチ処理では難しかった、リアルタイムのリコメンドも可能にします。
この記事は Neo4j Sandbox で体験できる "Personalized Product Recommendations with Neo4j" を元に作成しています。記述の順番やクエリの内容についてはわかりやすく編集および作成したため、必ずしも Sandbox の解説内容と同じではありません。この記事を読んで興味がある方は、ぜひ Neo4j Sandbox のデモンストレーション( https://neo4j.com/sandbox-v2/ )で実際に体験してみてください。
リコメンドがもたらすもの
(リテール、eコマースなどの業界では)パーソナライズされた商品リコメンドによって、コンバージョンレートの増加、売上の増大、顧客満足度の向上を期待することができます。Neo4jによって実現できるパーソナルリコメンドは、従来のバッチ処理によるような処理ではなくリアルタイムのリコメンド結果を期待することができます。
以降の記述では、デモ用の映画データセットを使用してパーソナルリコメンドを実装していきますが、同じ考え方を異なる製品(例えば商品の小売など)に適用することも可能です。
グラフデータを活用することによるパーソナルリコメンドのメリット
パーソナルリコメンドの実装はグラフデータベースの用途として一般的です。グラフデータベースを使用してパーソナルリコメンドを実装することには以下のようなメリットがあります。
- 性能: Neo4jではグラフデータそのものはオンメモリで探索することが可能です。このグラフ構造を探索することによって、従来のリレーショナルデータベースでは大量のデータをスキャンしなければいけなかった分析とは異なる手法で、リアルタイムのリコメンドを生成することができるようになります。これによりパーソナルリコメンドの用途がさらに広がることが期待できます。・・・例えばお店に入ったお客様が買い物かごを手に取るまでに、スマートフォンにリコメンドがプッシュ配信されたらとてもクールだと思いませんか?
- データモデル: プロパティグラフモデルは、複数のデータセットからのデータ結合を容易に実現することができます。これにより従来データセットのサイズやスキーマの問題からリコメンドの学習データに用いられなかったようなデータを使用することができるようになります
以下の記述では Neo4j Sandboxにて MovieLens データベースの抜粋から構成されたグラフデータベースを元に、映画のリコメンドを実装してみます。クエリは Sandbox のデータに対するクエリになっていますので、Neo4j Sandbox を開きながら記事を読んでいただけると、より実感がわくと思います。
手法1 - アイテムベースフィルタリング
リコメンドに用いられる手法は大きく2種類に分類されます。ひとつがアイテムベースのフィルタリング(=リコメンド)、もうひとつが "協調フィルタリング" と呼ばれる手法です。まずはアイテムベースのフィルタリングを実装してみます。
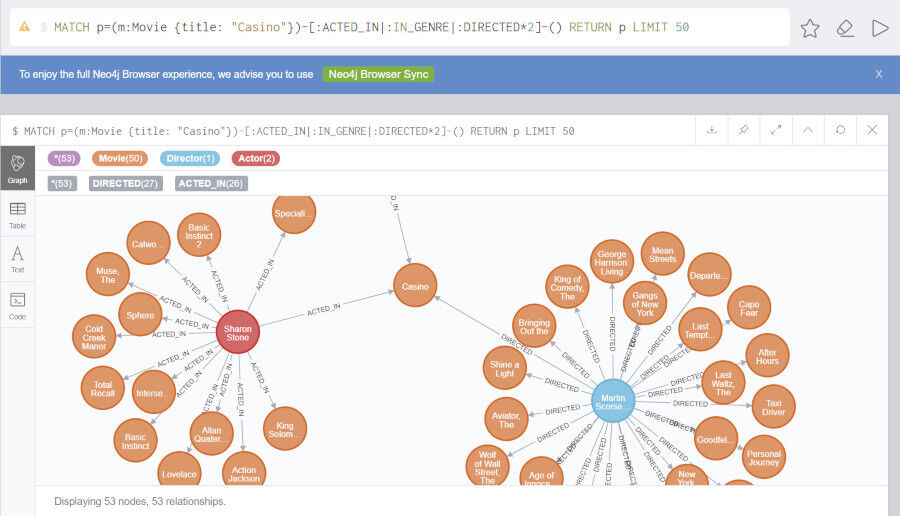
一般的にリコメンドされるアイテム(今回の例では映画)は、ユーザが以前に見ていたり、高く評価していたり、購入しているアイテムと似ていることが多いです。例えば以下のクエリは、映画 Casino (邦題: カジノ) とジャンル、監督、出演者が同じの映画を抽出します。これがアイテムベースフィルタリングの原型になります。Neo4jにおいてこのクエリは非常に高速に処理されます。
MATCH p=(m:Movie {title: "Casino"})-[:ACTED_IN|:IN_GENRE|:DIRECTED*2]-() RETURN p LIMIT 50
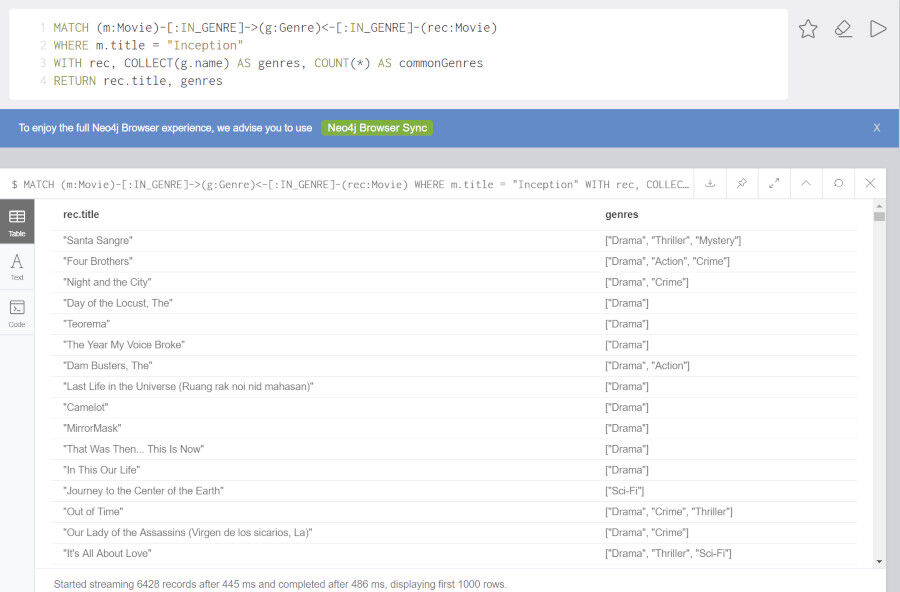
見た映画と同じジャンルの映画を抽出してみます。以下の例は、映画 Inception(邦題: インセプション)と同じジャンルの映画の一覧を抽出します。
MATCH (m:Movie)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) WHERE m.title = "Inception" WITH rec, COLLECT(g.name) AS genres, COUNT(*) AS commonGenres RETURN rec.title, genres
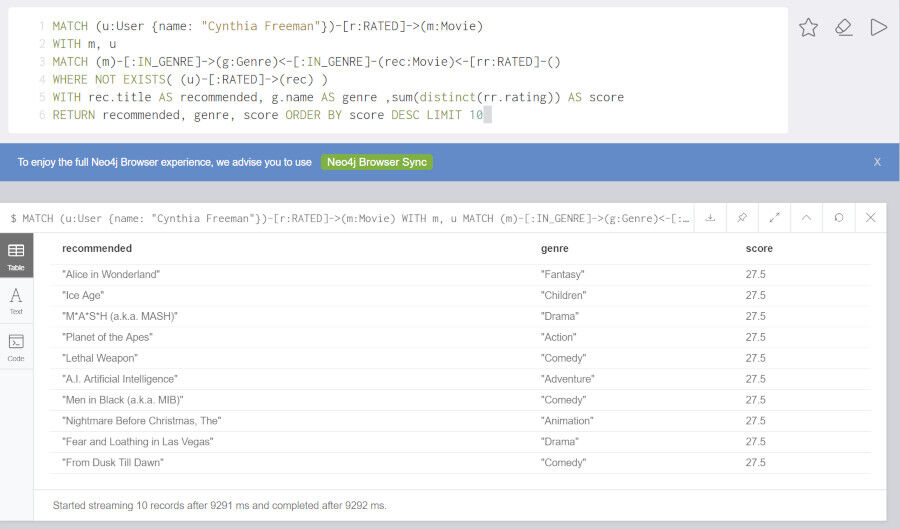
データの中に、"映画を見た(=評価した)"という情報が含まれているのであれば、「自分が見た映画と同じジャンルのまだ見ていない映画のうち、評価の高い順に10件表示する」ことも可能になります。以下のクエリがその処理例になります。"Cynthia Freeman"が見て評価した映画と同じジャンルの映画のうち、"Cynthia Freeman"がまだ評価していない映画につけられた評価合計の高い順から10個の映画を返します。
MATCH (u:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH m, u
MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)<-[rr:RATED]-()
WHERE NOT EXISTS( (u)-[:RATED]->(rec) )
WITH rec.title AS recommended, g.name AS genre ,sum(distinct(rr.rating)) AS score
RETURN recommended, genre, score ORDER BY score DESC LIMIT 10
見た映画のジャンルの偏り(好み)を考慮する場合、以下のようなクエリになります。
MATCH (u:User {name: "Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH m, u
MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie)<-[rr:RATED]-()
WHERE NOT EXISTS( (u)-[:RATED]->(rec) )
WITH rec.title AS recommended, g.name AS genre ,sum(rr.rating) AS score
RETURN recommended, genre, score ORDER BY score DESC LIMIT 10
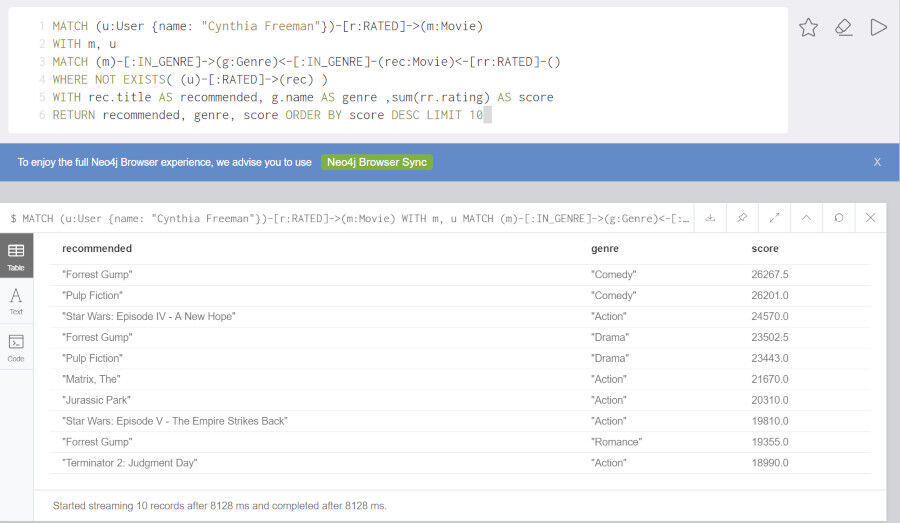
上記の2つのクエリの結果は興味深く示唆をもたらします。下側のクエリはより結果が安定しています。つまり開発においては検証しやすく、テストしやすいという特性を持ちます。しかしユーザの側に立ってみれば、毎回結果が変わらないリコメンドは魅力的に見えないかもしれません。変わり映えしないリコメンド内容に飽きが来て、結果的にリコメンドが利用されないという結果を招くかもしれません。
一方上側のクエリは視聴ジャンル傾向を考慮していないためランダム性があり、毎回リコメンドの結果が異なります。リコメンドの基準が曖昧になっているため、合っているような合っていないような、少し不思議な感覚にとらわれます。しかしユーザにとって見れば、毎回リコメンドを見るたびに新たな出会いがあり、リコメンドの内容に興味をひかれるかもしれません。
このようにリコメンドの利用シーンにおいては精度が高ければよりよいリコメンドとは限りません。あえてユーザに探索の余地を残しておくのもエンジニアの腕の見せどころかもしれません。また上記のクエリ文を見てわかるとおり、機械学習の類は全く使用していないにもかかわらず、あたかも AI っぽく振る舞うような面白さがあります。このような「リコメンドっぽい」アルゴリズムを簡便に作成し、高速に結果が得られることも Neo4j の魅力の一つです。
Jaccard係数
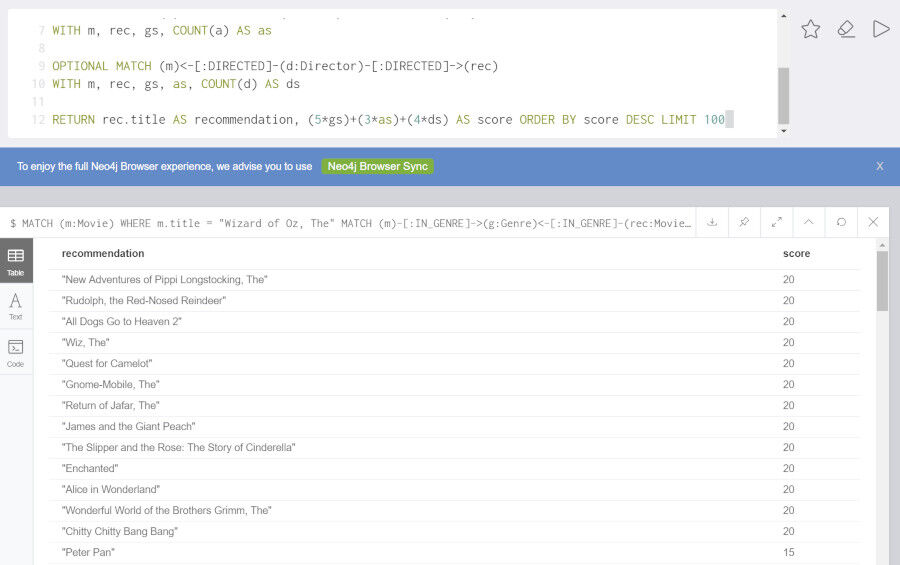
リコメンドを算出する複数の要素に係数をかけ、重み付けをしてもいいかもしれません。以下の例ではジャンル、俳優、監督それぞれが同じである別の映画に対して、ジャンル、俳優、監督それぞれに異なる係数をかけたスコアを算出しています。
MATCH (m:Movie) WHERE m.title = "Wizard of Oz, The" MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) WITH m, rec, COUNT(*) AS gs OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec) WITH m, rec, gs, COUNT(a) AS as OPTIONAL MATCH (m)<-[:DIRECTED]-(d:Director)-[:DIRECTED]->(rec) WITH m, rec, gs, as, COUNT(d) AS ds RETURN rec.title AS recommendation, (5*gs)+(3*as)+(4*ds) AS score ORDER BY score DESC LIMIT 100
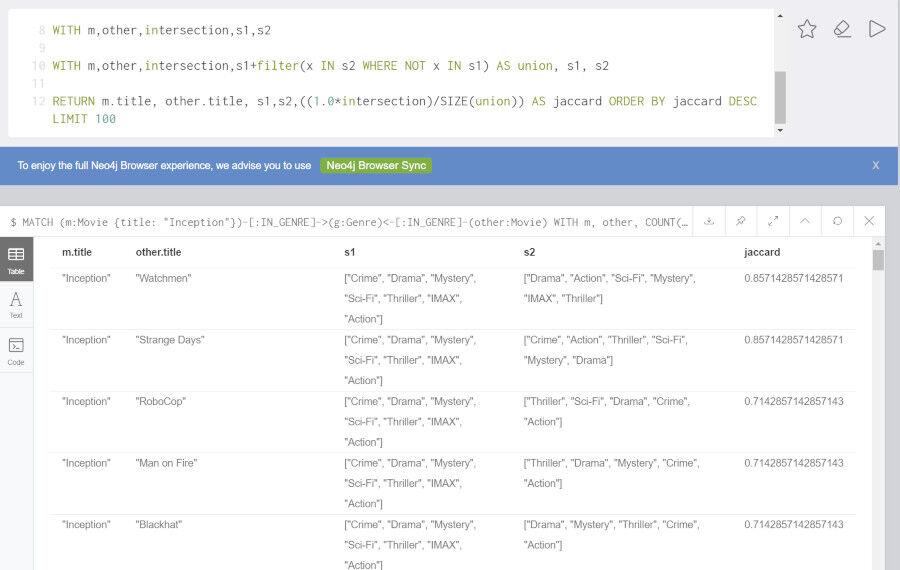
集合間の類似性を恣意的な係数ではなく、より一般的な指標で示すことも可能です。以下の例は、映画 Inception(邦題: インセプション)と同じジャンルにある映画それぞれに対してジャンル類似性を示すJaccard係数を計算し、類似性の高い順に表示するクエリです。
MATCH (m:Movie {title: "Inception"})-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(other:Movie)
WITH m, other, COUNT(g) AS intersection, COLLECT(g.name) AS i
MATCH (m)-[:IN_GENRE]->(mg:Genre)
WITH m,other, intersection,i, COLLECT(mg.name) AS s1
MATCH (other)-[:IN_GENRE]->(og:Genre)
WITH m,other,intersection,i, s1, COLLECT(og.name) AS s2
WITH m,other,intersection,s1,s2
WITH m,other,intersection,s1+filter(x IN s2 WHERE NOT x IN s1) AS union, s1, s2
RETURN m.title, other.title, s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100
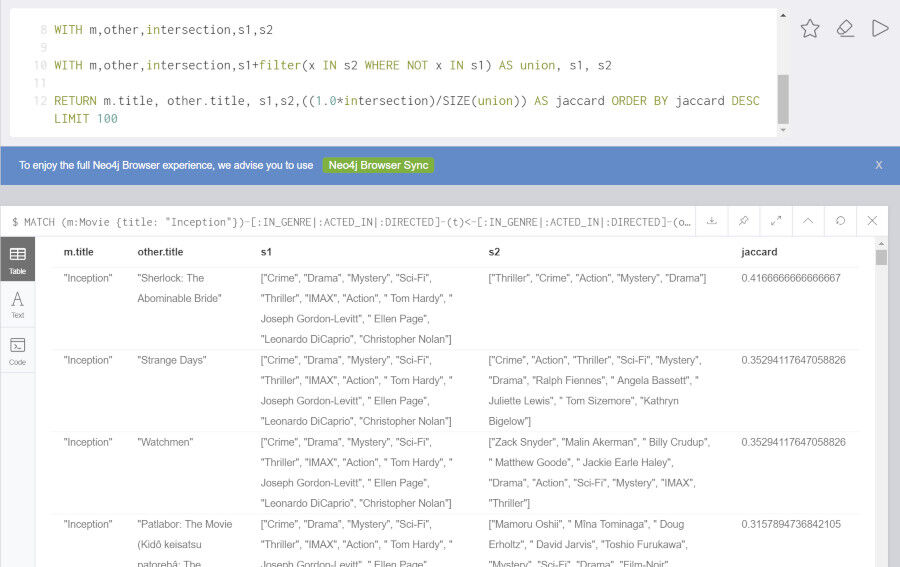
ジャンルではなく他の要素(出演俳優、監督など)に対してもJaccard係数は算出することができます。
MATCH (m:Movie {title: "Inception"})-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(t)<-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(other:Movie)
WITH m, other, COUNT(t) AS intersection, COLLECT(t.name) AS i
MATCH (m)-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(mt)
WITH m,other, intersection,i, COLLECT(mt.name) AS s1
MATCH (other)-[:IN_GENRE|:ACTED_IN|:DIRECTED]-(ot)
WITH m,other,intersection,i, s1, COLLECT(ot.name) AS s2
WITH m,other,intersection,s1,s2
WITH m,other,intersection,s1+filter(x IN s2 WHERE NOT x IN s1) AS union, s1, s2
RETURN m.title, other.title, s1,s2,((1.0*intersection)/SIZE(union)) AS jaccard ORDER BY jaccard DESC LIMIT 100
手法2 - 協調フィルタリング
次はリコメンドの定番とも言える協調フィルタリングをやってみましょう。
協調フィルタリングはAmazon.comの「おすすめ商品」の例があまりに有名です。多くのユーザの嗜好情報を蓄積し、あるユーザと嗜好の類似した他のユーザの情報を用いて自動的に推論を行います。
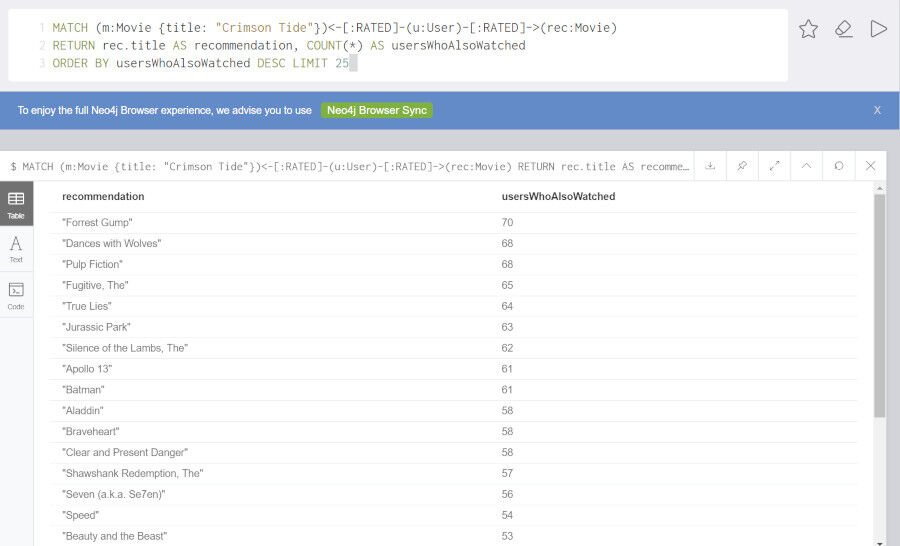
次の例はもっとも原始的な協調フィルタリングの例です。自分と似たユーザが買っているアイテムは、自分に合うかもしれないため、リコメンドの対象になります。例えば以下のクエリは、(自分と同様に)映画 Crimson Tide(邦題: クリムゾン・タイド)に評価を与えたユーザが評価した映画を抽出します。
MATCH (m:Movie {title: "Crimson Tide"})<-[:RATED]-(u:User)-[:RATED]->(rec:Movie)
RETURN rec.title AS recommendation, COUNT(*) AS usersWhoAlsoWatched
ORDER BY usersWhoAlsoWatched DESC LIMIT 25
つまり協調フィルタリングでは2人のユーザ、2つのアイテムがどの程度類似しているかを定量化します。2つの人・モノの間の類似性は以下のように示すことができます。
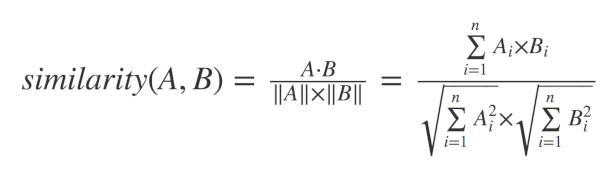
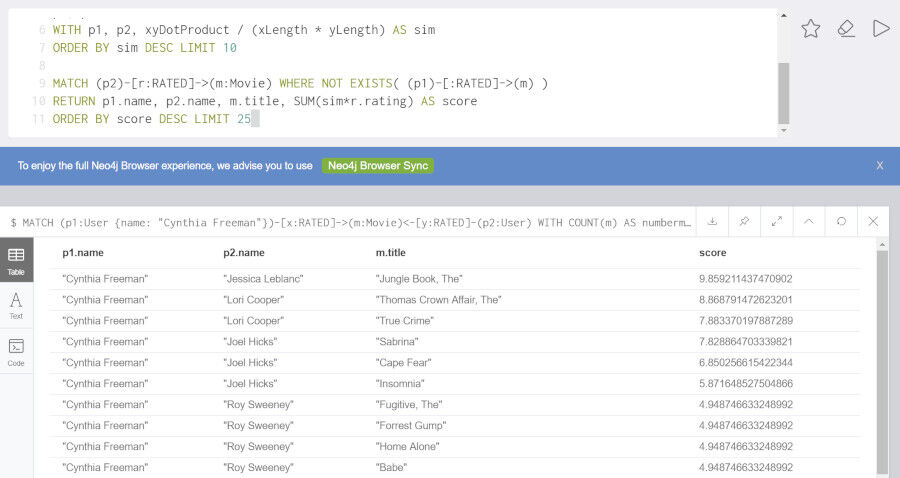
コサイン類似度の計算に基づき、"Cynthia Freeman"に最も近い好みを持つユーザを抽出し、類似性と評価に基づき映画をスコアリングしてユーザに提示します。
MATCH (p1:User {name: "Cynthia Freeman"})-[x:RATED]->(m:Movie)<-[y:RATED]-(p2:User)
WITH COUNT(m) AS numbermovies, SUM(x.rating * y.rating) AS xyDotProduct,
SQRT(REDUCE(xDot = 0.0, a IN COLLECT(x.rating) | xDot + a^2)) AS xLength,
SQRT(REDUCE(yDot = 0.0, b IN COLLECT(y.rating) | yDot + b^2)) AS yLength,
p1, p2 WHERE numbermovies > 10
WITH p1, p2, xyDotProduct / (xLength * yLength) AS sim
ORDER BY sim DESC LIMIT 10
MATCH (p2)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (p1)-[:RATED]->(m) )
RETURN p1.name, p2.name, m.title, SUM(sim*r.rating) AS score
ORDER BY score DESC LIMIT 25
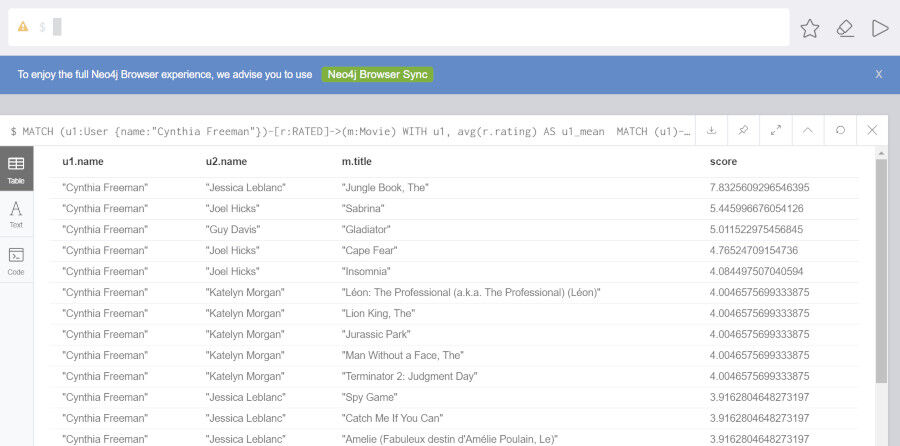
k近傍法(k-nearest Neighbor, kNN)を使うのもいいアイデアかもしれません。
MATCH (u1:User {name:"Cynthia Freeman"})-[r:RATED]->(m:Movie)
WITH u1, avg(r.rating) AS u1_mean
MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2)
WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (u2)-[r:RATED]->(m:Movie)
WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom,
sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom,
u1, u2 WHERE denom <> 0
WITH u1, u2, nom/denom AS pearson
ORDER BY pearson DESC LIMIT 10
MATCH (u2)-[r:RATED]->(m:Movie) WHERE NOT EXISTS( (u1)-[:RATED]->(m) )
RETURN u1.name, u2.name, m.title, SUM( pearson * r.rating) AS score
ORDER BY score DESC LIMIT 25
さいごに
Neo4jを活用して作成したグラフデータをもとに、いろいろなリコメンドができることを示しました。リコメンド自体は今ではある程度確立されたジャンルであり「この方法でなければできない」というようなものではなく、様々なユースケースに応じた工夫ができるということも魅力ではないかと思います。上記に述べた例だけではなく、他の機械学習アルゴリズムと組み合わせて、その人・サービスならではの味付けをすることもできます。
今回使用したSandboxのデータ量はノード数: 30,000(うちユーザ数: 671)、リレーションシップ数: 170,000と小規模なものですが、Neo4j自体はノード数、リレーションシップ数が数千万、といった大規模なグラフデータでも高速に動作します。様々なユースケースに応用が効くと言えるでしょう。
今後も Neo4j Sandbox の紹介記事を書いていきますのでご期待ください。では!



