
日本語文書からQ&Aを自動生成してみました #NLP
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
クリエションラインの朱です。主に機械学習を担当しています。今回は自然言語処理について書きます。
ユースケースは記事のタイトル通りですが、簡単な例を2つあげます。残りは皆さんの想像に任せるとして、手法の紹介をメインにしたいと思います。
- 社内の大量文書からQ&Aを自動生成したい
- 社内の一部文章に既にQ&Aが作られているが、新しい文章にもQ&Aを自動生成したい
今回は機械学習のつもりでしたが、機械学習を使いませんでした。「自動生成」に惹かれて機械学習を見に来た方に申し訳ありませんが、最後までお付き合いいただければと思います。
機械学習の自動生成といえば、VAE、GAN等流行りの手法がありますが、今回は機械学習の推論ベース手法を使わず、深層格解析という従来手法を試しました。理由は後ほど話します。
因みに機械学習を使う手法は[3]の論文で紹介されています。
なぜ機械学習の推論ベース手法を使わないのか
今回のお試しは機械学習の推論ベース手法と勝負するつもりはありません。むしろ生成される質問文の質(いわば精度)は推論ベース手法のほうが完勝だと思います。
但し、推論ベース手法では機械学習モデルを構築するために学習データを用意しない行けないケースがほとんどです。
例えば、A社に「社内の大量文書から大量なQ&Aを自動生成したい」ニーズがあるとして、「AIを使えば何とかできるでしょう」という考え方から、機械学習モデルを構築し始めました。モデルを学習させるために、人間が大量な文章を読んで、大量なQ&Aを考えなければ行けない作業が発生します。
無論「Yahoo!知恵袋」等いわゆる3rdPartyデータを使ってモデルを学習させることもできますが、過学習が起きてしまい、社内文書から質の高いQ&Aを生成できないです。
過学習を分かりやすく説明すると、「Yahoo!知恵袋を学習しましたが、社内文章を学習したことがないので、Q&Aの起こし方が分からない。」ということです。
上記の状況から今回は機械学習手法を使いませんが、前述のユースケース「社内に一部の文章に既にQ&Aが作られてありますが、新しい文章にもQ&Aを自動生成したい」を実現するために過去生成されたQ&Aをモデルに学習させて新しいQ&Aを生成する必要がありますので、今後推論ベース手法も試してみたいと思います。
Q&A生成器
今回検証した手法を具体例で説明します。手法は以下の3ステップがあります:
- 係り受け解析を行う
- 係り受け解析した文節に意味ラベルを付与
- 意味ラベルからQ&Aを生成
解析したい文は以下とします。
私がうどんを食べたいです
まずは上記文に対して係り受け解析を行います。係り受け関係は形態素の依存関係を示すものです。以下はCaboChaという日本語解析ライブラリを使って係り受け解析した結果です。
私
が
うどん
を
食べ
たい
です
。
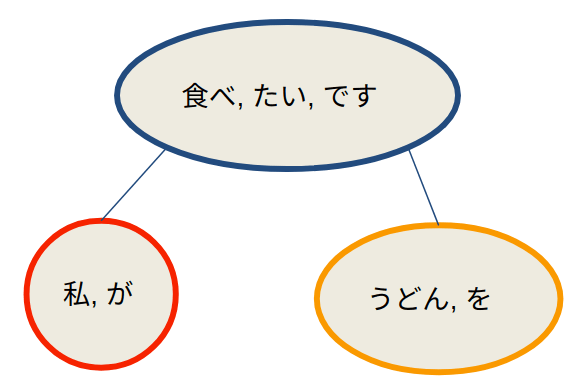
上記tokタグが形態素に対応しており、chunkタグが文節に対応しています。chunkタグにlinkプロパティがありますが、この文節はlink先の文節との依存関係を示しています。グラフ構造で描くと以下になります。

上記グラフを見ると、既にお分りだと思いますが、黒枠の「食べたいです」に対して、
- 「誰が食べたいですか」→「私が」
- 「何を食べたいですか」→「うどんを」
の2つのQ&Aを作成することができますね。
では、上記Q&Aをプログラムで自動生成するためには、どうすれば良いでしょう。日本語が複雑なので、「が」があるから「誰が」で質問を作る訳には行かないです。一つの方法はグラフのエッジに意味を付与し、文節間の意味的関係を解明するのです。意味的関係からQ&Aを生成します。エッジの意味を自動的に推定する作業はこれから意味ラベル付与と呼びますが、実現するために深層格解析を使います。
深層格は句の意味的な関係を示すラベルであり、すべての言語に共通した意味を表現する意味的関係である。深層格については、チャールズ・フィルモアによって提案された以下の深層格が有名のようです。
- 動作主格(agent)
- 対象格(object)
- 経験者格(experiencer)
- 道具格(instrument)
- 源泉格(source)
- 目標格(goal)
- 場所格(Location)
- 時間格(Time)
Q&Aを作れない文もありますので、今回の検証では用言のみからQ&Aを作ります。[4]の方法を参考し、以下パターンの用言を抽出します。
用言の条件:
- 動詞
- 形容詞
- 名詞+助動詞
「食べたいです」は動詞に該当するので、用言となります。
次に、「食べたいです」の子ノード「私が」を見て行きます。「私が」の主辞が「私」であり、名詞です。「語形」がガ格です。よって、格フレームが「名詞+ガ格+動詞」の構文になりますので、「私が」と「食べたいです」の意味的関係は動作主格とすることができます。
こういう風に深層格を解析することで、意味ラベルを生成することができます。
グラフのエッジに意味ラベル付与すると以下となります。
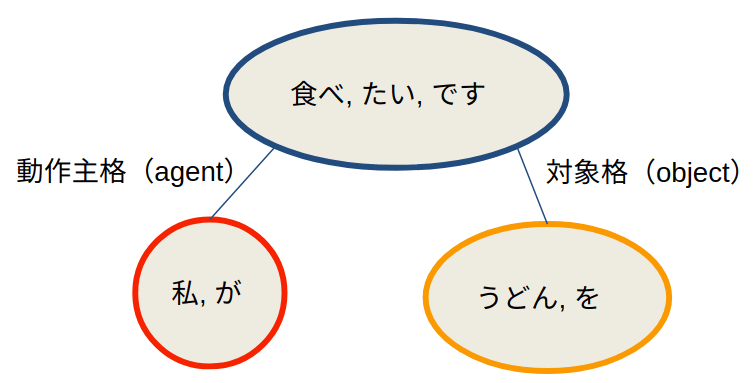
最後に意味ラベルに従ってQ&Aを生成します。
深層格解析により文節間の意味的関係を解析できましたので、例えば上記「動作主格」から「誰か」を質問することができます。
「対象格」から「何を」を質問できます。このようにプログラムで以下Q&Aを自動生成できます。
- 「誰が食べたいですか」→「私が」
- 「何を食べたいですか」→ 「うどんを」
意味ラベルの自動生成の検討
前述のように深層格解析を使って意味ラベルを生成できましたが、意味ラベルは多くないとはいえ、プログラム上で全ての意味ラベルに対応することが難しいので、教師あり学習であるマルチクラス分類モデルを構築することで対応することが考えられます。但し、学習データの準備は避けられませんし、手作業でデータを準備するのが厳しいので、上記深層格解析を使ってデータ・セットを用意するのが良いかもしれません。
また、学習データの準備を必要としない教師なし学習手法は[4]で紹介されています。
非常に興味深いテーマなので、これから検討して行きたいと思います。
実験
では、コンセプトの紹介が終わり、プログラムを作成して実際に実行してみました。
解析したい文は以下とします。
外の眺めが綺麗ですね。彼が学校に行きました。今日は大学で勉強します。
Q&Aの生成結果は以下の通りです。
Q : 何が、綺麗ですか?
A : 外の眺めが
Q : 誰が、学校に行きましたか?
A : 彼が
Q : 今日は何処で勉強しますか?
A : 大学で
なんとなくQ&Aのペアが生成できましたね。
まとめ
機械学習で自然言語処理のつもりでしたが、使わずに日本語文書からQ&Aの自動生成を試してみました。
前述の通り、機械学習を使わないメリットもあるので、案件のニーズをしっかり分析し、最適な技術を選べば良いと思います。場合によって古い技術は捨てるものではありませんし、使って見れば割と今回みたいにAIっぼいことができると思います。
日本語の構文の難しさを改めて実感しました。但し、解析することによって意味を付与できるのが中々興味深く、色んなユースケースで使えそうです。
また、今の日本では人手不足が問題なので、作業の自動化により社会問題を解決できるので非常にやりがいを感じています。
今回検証用のソースコードに興味ある方はこちらをご参照ください。自然言語処理関連の記事はこれからも書く予定なので、また見に来てください。
参考
[1]http://www.nltk.org/book-jp/ch12.html#id75
[2]https://qiita.com/yukihon_lab/items/5f494d1a39849071f077
[3]https://www.anlp.jp/proceedings/annual_meeting/2018/pdf_dir/P8-2.pdf
[4]格フレーム辞書の漸次的自動構築 自然言語処理, Vol.12, No.2, pp.109-131, 2005.



