
Kaggle challenge: Santanders product recommendations #dataanalytics #kaggle #machinelearning
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。

本記事は翻訳です。原文は英語のものをご参照ください
こんにちは!データサイエンティストのナゼイルです
Natheer Alabsiです。東京大学大学院のフロンティアサイエンス研究科の環境科学専攻の修士号と博士号をそれぞれ2011年と2015年に取得し、統合リモートセンシング、GPS、GISを使った沿岸漁業資源のモニタリング技術を開発しました。現在私はCreationline INCのデータ科学者およびデータ分析専門家として働いています。私の仕事は、Python、R、Apache Sparkでのデータの調査、分析、機械学習です。
Kaggleをご存知ですか?
Kaggleは、データサイエンスに携わる技術者の中で最も有名なウェブサイトであり、まさに the Home of Data Science と言えます。企業や組織が抱えるさまざまな課題を機械学習のコンペティションという形で共有し、データセットを提供しています。優秀な解決を生み出したデータサイエンティストには賞金が与えられることもあります!世界中のデータサイエンティストが切磋琢磨し、最高のソリューションを日々生み出しています。
例えば現在では以下のようなコンペティションが開催されています。
-
Data Science Bowl 2017: 肺のDICOM医療画像から肺がんの発生を予測するコンペティションです。上位10人のデータサイエンティストに総額100万ドルの賞金が提供されます!
-
Dstl Satellite Imagery Feature Detection: 衛星画像からの地表状況判断を自動化するコンペティションです。上位3人のデータサイエンティストに賞金10万ドルが提供されます
-
The Nature Conservancy Fisheries Monitoring: 漁船から撮影された画像を元に魚とその種類を判別するコンペティションです。上位5人のデータサイエンティストに賞金15万ドルが提供されます
Santanders product recommendationsについて
サンタンデール銀行(Santander Bank)は、2016年10月26日から12月21日の期間、製品リコメンドに関するコンペティションをKaggle上で開催しました。残念ながらその期間私は実際の案件対応のため最終的なリコメンドロジックを応募することができませんでした。
このコンペティションでは、過去18ヶ月間に顧客に提供された商品と顧客の購買データをもとに、追加された新製品に対する顧客の反応を予測することが目的になっています。
顧客が次に何を購入するのか?顧客の今のニーズを満たす製品を適切にリコメンドできるように、顧客の行動を理解しようとする企業が増えています。リコメンドが適切に行えるのであれば、競合他社よりの優位に立ち、顧客ニーズを理解しロイヤルティを高めることが可能になります。
課題解決のための戦略
コンペティションの直接的な目標は、翌月に提供される新製品に対して、顧客が購入するか、しないかを予測することです。プログラムの中では、顧客を add または not_add (以下 add=1, not_add=0 で示す) に分類するという手法に落としこむことができます。
ただし異なる製品は異なるパラメータの影響を受けます。収入や年齢によって影響を受けるものもあれば、顧客セグメンテーションや性別などによって影響を受けるものもあります。従って私はモデルを作成する前に、各製品の最も重要な機能を選択するためのプロセスを組み込むことにしました。それぞれのモデルは、製品によって異なる挙動をとります。従って製品ごとに最も良いモデルを選択することが重要です。私は一般的な分類モデルのうち10個をテストし、最終的に製品ごとに最も良い精度を出すモデルを選択するようにしました。
最後にアンサンブル(複数モデル)を使用します。アンサンブルを使用することによって精度は明確に向上することが、多くのコンペティションの結果わかっています。通常コンペティションの上位入賞者はアンサンブルを組み込んでいることが一般的です。従って私もアンサンブルを使用することで精度を向上させるようにします。ここでのアンサンブルとは、複数のモデルを使用し、それぞれのモデルから導かれた予測を結合して、最終出力の精度を向上させることを意味しています。
ツールの準備
今回はAnacondaを使用します。Anacondaはデータサイエンティストに最適化されたPythonツールセットで、100以上の有名なデータサイエンス用パッケージを含む、720以上のソフトウェアパッケージが提供されています。Anaconda自体はPython, R, Scalaを使用することができるのですが、今回はPythonを使用することにします。
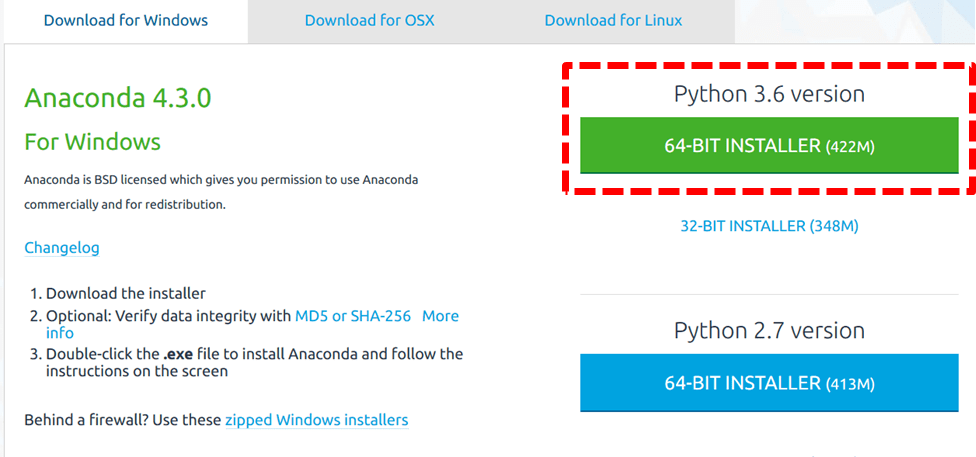
まずはAnacondaをダウンロードします。Pythonのバージョンは3.6にします。

ダウンロードした .exe ファイルをダブルクリックし、画面の支持に従ってインストールします。インストールが完了するとデスクトップにAnacondaのアイコンが配置されますので、ダブルクリックしてAnaconda Navigatorを起動してください。
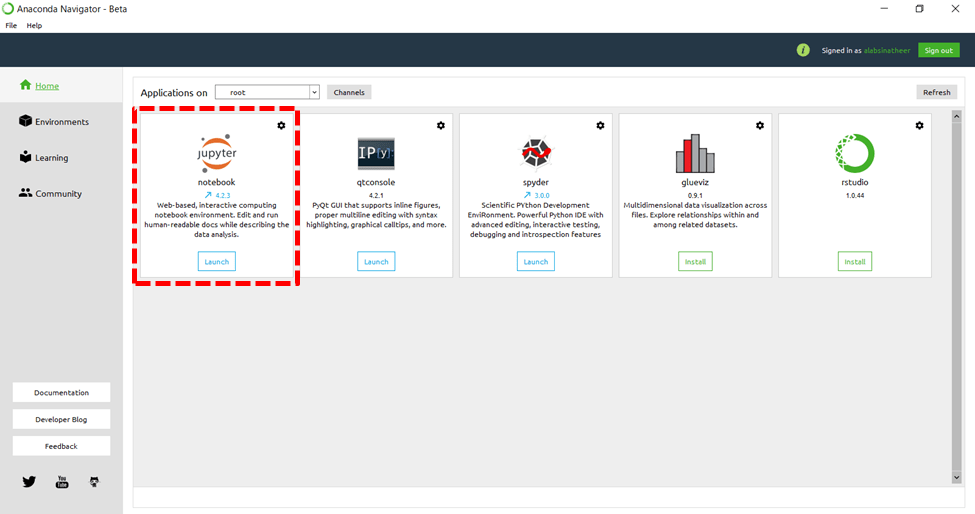
起動すると以下のような画面が表示されます。このAnaconda NavigatorからiPython Notebookを使用するためのノートブックサーバを起動することができます。ノートブックサーバを起動するには、下図のとおりJupyter notebook アイコンを選択します。
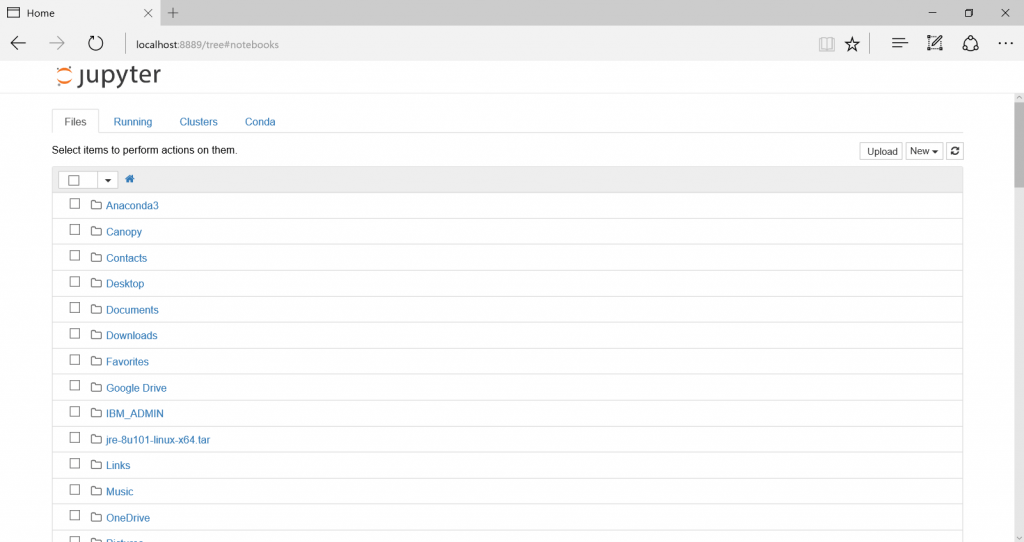
iPython Notebookの画面がブラウザ上に開いたら、ローカルホスト上のファイルにアクセスすることができるようになります。これでデータファイルや、過去に作成したノートブックを開くことができるようになります。
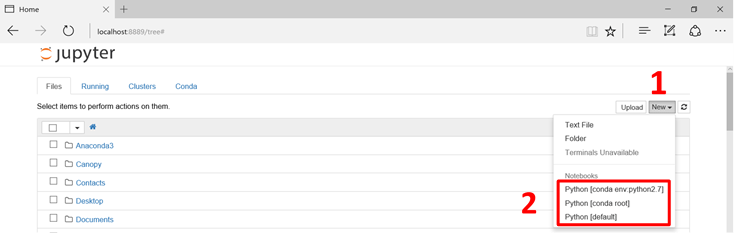
画面の右側にある New をクリックして、新規ノートブックを作成します。 "Notebooks" リストには既にインストールされているカーネルが一覧表示されており、自分の使用したい環境を選択することができます。
新規ノートブック作成直後の画面は以下のようになっています。
Anaconda には Pythonが組み込まれており、既に多くのパッケージがインストールされています。後々エラーなどで悩まないように、まずは全てのパッケージを更新することをおすすめします。全てのパッケージは以下の手順で更新します。
- Anaconda Navigator の左メニューから Environments を選択
- Open Terminalを選択
- プロンプトから以下のコマンドを実行
conda upgrade conda
conda upgrade --all
新しいパッケージをインストールする場合は、 conda install package_name コマンドを実行します。例えば Pandas パッケージをインストールする場合は、 conda install pandas とコマンドを実行します。
既存のパッケージを更新する場合は、 conda update package_name コマンドを実行します。全てのパッケージを更新する場合(実際これをよくやるのですが)は、 conda update --all というコマンドを実行します。
パッケージを導入する
それでは Jupyter Notebook 上で作業を進めていきましょう。この記事の中で使用するパッケージは以下のものです。
import numpy as np
import pandas as pd
from pickle import dump
import sklearn.utils
from sklearn.metrics import confusion_matrix, accuracy_score, recall_score
from sklearn import preprocessing, ensemble
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neural_network import MLPClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.feature_selection import RFE
データの準備
データの読み込み
提供されているデータファイルを読み込みます。
df = pd.read_csv("C:/Users/m-alabsi/train_ver2.csv/train_ver2.csv",
dtype={"sexo":str, "ind_nuevo":str, "ult_fec_cli_1t":str, "indext":str})
# sort the data by user_id and date
df.sort_values(by=["ncodpers", "fecha_dato"], ascending=[True, False], inplace=True)
df["fecha_dato"] = pd.to_datetime(df["fecha_dato"],format="%Y-%m-%d") # change the date format
product カラムにおける全ての欠損データを 0(zero) で置き換えます
df.loc



