
Cypherクエリの基礎 2020 #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
Cypher(サイファー)とは、グラフ構造のデータ処理を行うために開発されたクエリ言語です。
簡略な構文でとても複雑な論理構成が可能であることが特徴です。
ここでは、Cypherを利用したデータの登録、更新、検索、削除など、基本的なデータ操作方法を紹介します。
- シンプルな構文で複雑な論理構成が可能です
A-LIKES->B,A-LIKES->C,B-LIKES->Cのような論理を
A-LIKES->B-LIKES->C<-LIKES->Aのように表現します。
- データモデルがグラフ構造であるためSQLのように紐解く必要がなく、高速処理が可能です。
- 自然言語的な流れのシンタックスであるために直観的かつ分かりやすいです。
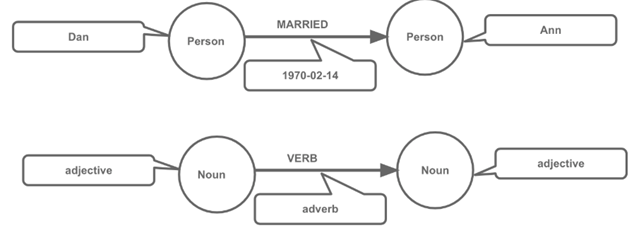
CREATE (:Person { name: ’Dan’ })-[:MARRIED { day:’1970-02-14 } ]->(:Person { name : ’ Ann’)
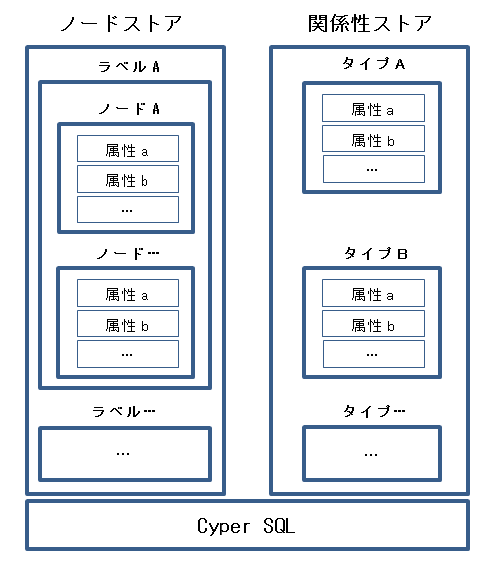
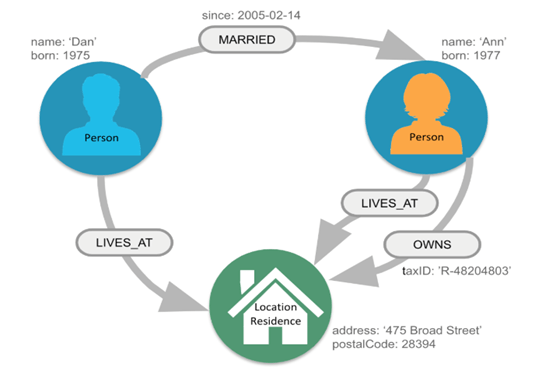
グラフモデル
グラフモデルは頂点と辺にプロパティを持たせる、とてもシンプルな構造でデータを表現します。
ノード(頂点)
- ラベルを付けてグループ化します(Person)
- プロパティを持ちます(name:’Dan’)
- ラベルでノードをクループ化し、クエリを最適化します
リレーションシップ(辺)
- タイプ(名称)を付けます(MARRIED)
- プロパティを持ちます(since:2005-02-14)
プロパティ
ノードとリレーションシップはどちらもキーバリュータイプのプロパティを持つことができます。
(:Person {{key1:value1, key2:value2, …} }
()-[:MARRIED {key1:value1, key2:value2, …}->()
このようなグラフをプロパティグラフと呼びます。
このようなデータモデルの特徴のために、とても複雑な繋がりをもつ事象でも簡単にデータベース設計が可能です。
次は、「パナマ文書」のデータモデルです。
黒くぬり潰されている箇所はリレーションシップが密集しています。
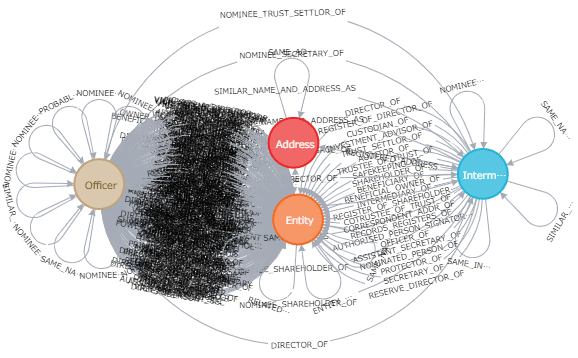
Displaying 4 nodes, 322 relationships
出所: https://neo4j.com/sandbox/
Cypherの実行環境
Neo4jのインストールは、次の記事を参照してください。
この記事では、Neo4jが提供しているムービーグラフを利用しています。
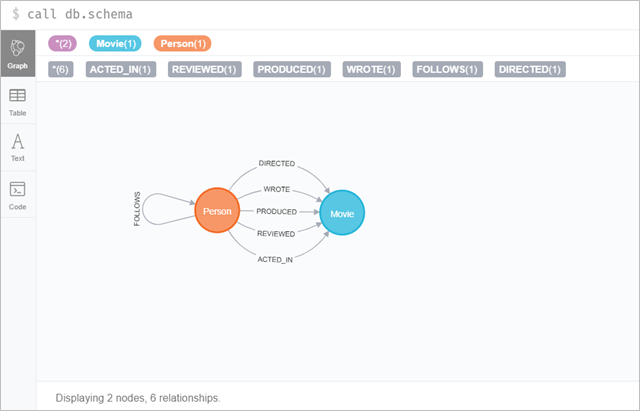
ノードのフィルター
ノードのアスキーアート表現
()
(p)
(:Person) //匿名の識別子はクエリから参照できません
(p:Person) //識別子(p)はクエリから参照できます
(p:Person:Actor) //ラベルは階層化できます
特定のプロパティをフィルター
born: 1970をフィルターしてみます。
MATCH (p:Person {born: 1970})
RETURN p
リレーションシップのアスキーアート表現
()--()
()-->()
()<--()
()-[ * ]-()
()-[ *0..10]-()
()-[ *0..]-()
()-[r]-()
()-[r:MARRIED]-()
()-[r:MARRIED]->() //識別子はクエリで参照できます
()<-[:MARRIED]-() //匿名の識別子はCypherのなかで参照できません
()-[r:MARRIED|LIVES_AT]-() //タイプは複数設定できます(OR)
特定のリレーションシップをフィルター
ACTED_INをフィルターしてみます。
MATCH (p:Person)-[rel:ACTED_IN]->(m:Movie {title: 'The Matrix'})
RETURN p, rel, m
MATCH (p)-[rel:ACTED_IN]->(m:Movie {title: 'The Matrix'})
RETURN p, rel, m
リレーションシップのタイプを取得
type()はリレーションシップのタイプを出力します。
MATCH (p:Person)-[rel]->(m:Movie {title:'The Matrix'})
RETURN p.name, type(rel) , m.title
p.name type(rel) m.title
"Joel Silver" "PRODUCED" "The Matrix"
"Emil Eifrem" "ACTED_IN" "The Matrix"
"Laurence Fishburne" "ACTED_IN" "The Matrix"
"Lana Wachowski" "DIRECTED" "The Matrix"
"Hugo Weaving" "ACTED_IN" "The Matrix"
"Lilly Wachowski" "DIRECTED" "The Matrix"
"Carrie-Anne Moss" "ACTED_IN" "The Matrix"
"Keanu Reeves" "ACTED_IN" "The Matrix"
リレーションシップのプロパティを取得
「識別子.キー」のように出力します。
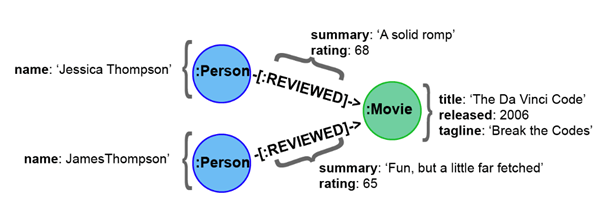
MATCH (p:Person)-[r:REVIEWED {rating: 65}]->(m:Movie {title: 'The Da Vinci Code'})
RETURN p.name, r.rating, m.title
p.name r.rating m.tit
"James Thompson" 65 "The Da Vinci Code"
推奨のCypherスタイル
- ノードのラベル名は、キャメルケース(CamelCase)で表現し、英字の大文字で始めることを推奨 (例: Person, NetworkAddress)。大文字と小文字を区別
- プロパティキー、変数、パラメーター、エイリアス、ファンクションは、キャメルケース(CamelCase)であり、英字の小文字で始めることを推奨(例:businessAddress)。大文字と小文字を区別
- リレーションシップのタイプは、英字の大文字で表現し、アンダースコアを使用することを推奨(例:ACTED_IN, FOLLOWS)
- Cypherのキーワードは、大文字で書くことを推奨(例: MATCH, RETURN)。大文字と小文字を区別しない
- 文字列は、シングルクォート又はダブルクォートを使用(例:’The Matrix’, “Somethins’s Gotta Give”, ’Somethins\’s Gotta Give’)
- コメントは、2のタイプがあります
// hogehoge
/* hogehoge */
WHEREによるフィルター
これはCypherネイティブの構文です。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie {released: 2008})
RETURN p, m
次はWHERE句による構文です。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE m.released = 2008 RETURN p, m
WHEREに範囲のフィルター
次の2つの構文は同じ意味です。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE m.released >= 2003 AND m.released <= 2004 RETURN p.name, m.title, m.released p.name m.title m.released "Hugo Weaving" "The Matrix Reloaded" 2003 "Laurence Fishburne" "The Matrix Reloaded" 2003 "Carrie-Anne Moss" "The Matrix Reloaded" 2003 "Keanu Reeves" "The Matrix Reloaded" 2003 "Hugo Weaving" "The Matrix Revolutions" 2003 "Laurence Fishburne" "The Matrix Revolutions" 2003 "Carrie-Anne Moss" "The Matrix Revolutions" 2003 "Keanu Reeves" "The Matrix Revolutions" 2003 "Keanu Reeves" "Something's Gotta Give" 2003
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE 2003 <= m.released <= 2004 RETURN p.name, m.title, m.released p.name m.title m.released "Hugo Weaving" "The Matrix Reloaded" 2003 "Laurence Fishburne" "The Matrix Reloaded" 2003 "Carrie-Anne Moss" "The Matrix Reloaded" 2003 "Keanu Reeves" "The Matrix Reloaded" 2003 "Hugo Weaving" "The Matrix Revolutions" 2003 "Laurence Fishburne" "The Matrix Revolutions" 2003 "Carrie-Anne Moss" "The Matrix Revolutions" 2003 "Keanu Reeves" "The Matrix Revolutions" 2003 "Keanu Reeves" "Something's Gotta Give" 2003
exists()
m.taglineが存在するパターンを探索します。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name='Jack Nicholson' AND exists(m.tagline) RETURN m.title, m.tagline LIMIT 5 m.title m.tagline "A Few Good Men" "In the heart of the nation's capital, in a courthouse of the U.S. government, one man will stop at nothing to keep his honor, and one will stop at nothing to find the truth." "As Good as It Gets" "A comedy from the heart that goes for the throat." "Hoffa" "He didn't want law. He wanted justice." "One Flew Over the Cuckoo's Nest"
正規表現
正規表現を使ってフィルターすることもできます(=~)。
MATCH (p:Person) WHERE p.name =~'Tom.*' RETURN p.name p.name "Tom Cruise" "Tom Skerritt" "Tom Hanks" "Tom Tykwer"
IN
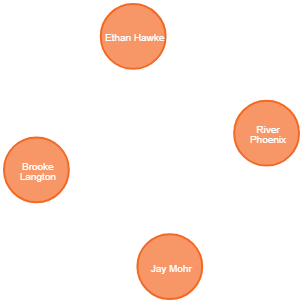
複数のデータをリストタイプに並べてフィルターができます。
MATCH (p:Person) WHERE p.born IN [1965, 1970] RETURN p.name as name, p.born as yearBorn LIMIT 5 name yearBorn "Lana Wachowski" 1965 "Jay Mohr" 1970 "River Phoenix" 1970 "Ethan Hawke" 1970 "Brooke Langton" 1970
変数として設定することもできます。
MATCH (p:Person)-[r:ACTED_IN]->(m:Movie) WHERE 'Neo' IN r.roles AND m.title='The Matrix' RETURN p.name p.name "Keanu Reeves"
ALL
ALLはリストのすべての要素が条件を満たせばtrueとなります。次の例ではlist1がlist2に含まれる時にtrueとなります。
WITH ["A","B","C","D","E"] AS list1, ["A","B","C","D","E","F"] AS list2 WHERE ALL( x IN list1 WHERE x IN list2) RETURN list1 list1 [A, B, C, D, E]
NONE
NONEはリストのすべての要素が条件を満たさない時にtrueとなります。次の例ではlist1とlist2に共通の要素がない時にtrueとなります。
WITH ["A","B","C","D","E"] AS list1, ["F","G"] AS list2 WHERE NONE( x IN list1 WHERE x IN list2) RETURN list1 list1 ["A", "B", "C", "D", "E"]
ANY
ANYはリストの中で1つでも条件を満たす要素があればtrueを返します。list1とlist2は1つ以上の共通要素があればtrueとなります。
WITH ["A","B","C","D","E"] AS list1, ["A","F"] AS list2 WHERE ANY( x IN list1 WHERE x IN list2) RETURN list1 list1 ["A", "B", "C", "D", "E"]
WITH ["A","B","C","D","E"] AS list1, ["C","D","K","O"] AS list2 WHERE ANY( x IN list1 WHERE x IN list2) RETURN list1 list1 ["A", "B", "C", "D", "E"]
SINGLE
SINGLEは条件を満たす要素が1つのみのときにtrueとなります。list1とlist2の共通要素がひとつだけのときにtrueとなります。
WITH ["A","B","C","D","E"] AS list1, ["A","F","K"] AS list2 WHERE SINGLE( x IN list1 WHERE x IN list2) RETURN list1 ["A", "B", "C", "D", "E"]
WITH ["A","B","C","D","E"] AS list1, ["A","E"] AS list2 WHERE SINGLE( x IN list1 WHERE x IN list2) RETURN list1 (no changes, no records)
結果値の制御
重複を排除(DISTINCT)
次の構文では映画リストに重複が発生します。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.released, collect(m.title) AS movies //RETURN m.released, collect(DISTINCT m.title) AS movies m.released movies 1992 ["A League of Their Own"] 2012 ["Cloud Atlas"] 2006 ["The Da Vinci Code"] 1993 ["Sleepless in Seattle"] 2004 ["The Polar Express"] 1999 ["The Green Mile"] 2000 ["Cast Away"] 2007 ["Charlie Wilson's War"] 1996 ["That Thing You Do", "That Thing You Do"]
DISTINCTを使って映画リストの中身をユニークにします。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' //RETURN m.released, collect(m.title) AS movies RETURN m.released, collect(DISTINCT m.title) AS movies m.released movies 1992 ["A League of Their Own"] 2012 ["Cloud Atlas"] 2006 ["The Da Vinci Code"] 1993 ["Sleepless in Seattle"] 2004 ["The Polar Express"] 1999 ["The Green Mile"] 2000 ["Cast Away"] 2007 ["Charlie Wilson's War"] 1996 ["That Thing You Do"]
次の構文は同じ結果になります。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' //WITH m WITH DISTINCT m RETURN m.released, m.title m.released movies 1992 ["A League of Their Own"] 2012 ["Cloud Atlas"] 2006 ["The Da Vinci Code"] 1993 ["Sleepless in Seattle"] 2004 ["The Polar Express"] 1999 ["The Green Mile"] 2000 ["Cast Away"] 2007 ["Charlie Wilson's War"] 1996 ["That Thing You Do"]
ソート(ORDER BY)
映画のリリース年度で降順ソートします。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.released, collect(DISTINCT m.title) AS movies ORDER BY m.released DESC m.released movies 2012 ["Cloud Atlas"] 2007 ["Charlie Wilson's War"] 2006 ["The Da Vinci Code"] 2004 ["The Polar Express"] 2000 ["Cast Away"] 1999 ["The Green Mile"] 1998 ["You've Got Mail"] 1996 ["That Thing You Do"] 1995 ["Apollo 13"]
映画のリリース年度で昇順ソートします。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.released, collect(DISTINCT m.title) AS movies ORDER BY m.released ASC m.released movies 1990 ["Joe Versus the Volcano"] 1992 ["A League of Their Own"] 1993 ["Sleepless in Seattle"] 1995 ["Apollo 13"] 1996 ["That Thing You Do"] 1998 ["You've Got Mail"] 1999 ["The Green Mile"] 2000 ["Cast Away"] 2004 ["The Polar Express"]
数を制限(LIMIT)
結果値を表示する数を制限します。
MATCH (p:Person)-[:DIRECTED | ACTED_IN]->(m:Movie) WHERE p.name = 'Tom Hanks' RETURN m.released, collect(DISTINCT m.title) AS movies ORDER BY m.released DESC LIMIT 5 m.released movies 2012 ["Cloud Atlas"] 2007 ["Charlie Wilson's War"] 2006 ["The Da Vinci Code"] 2004 ["The Polar Express"] 2000 ["Cast Away"]
リスト化(collect)
結果値をリストに集合します。
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WITH m, count(m) AS numCast, collect(a.name) as cast RETURN m.title, cast, numCast ORDER BY size(cast) m.title cast numCast "The Polar Express" ["Tom Hanks"] 1 "Cast Away" ["Tom Hanks", "Helen Hunt"] 2 "One Flew Over the Cuckoo's Nest" ["Jack Nicholson", "Danny DeVito"] 2 "Bicentennial Man" ["Oliver Platt", "Robin Williams"] 2 "The Devil's Advocate" ["Charlize Theron", "Keanu Reeves", "Al Pacino"] 3 "Joe Versus the Volcano" ["Tom Hanks", "Nathan Lane", "Meg Ryan"] 3 "That Thing You Do" ["Tom Hanks", "Liv Tyler", "Charlize Theron"] 3
リストを縦に出力(UNWIND)
UNWINDはリストの要素を取り出します。
WITH [1, 2, 3] AS list UNWIND list AS row RETURN list, row list row [1, 2, 3] 1 [1, 2, 3] 2 [1, 2, 3] 3
UNWINDの変換値はクエリから変数として参照できます。
MATCH (:Person {name:'Tom Hanks'})-->(movie)
WITH collect(movie.title) AS list UNWIND list AS titles
//RETURN titles
MATCH (m:Movie {title : titles})
RETURN m.title, m.released
m.title m.released
"A League of Their Own" 1992
"Cloud Atlas" 2012
"The Da Vinci Code" 2006
"Sleepless in Seattle" 1993
"The Polar Express" 2004
"The Green Mile" 1999
"Cast Away" 2000
"Charlie Wilson's War" 2007
"That Thing You Do" 1996
日付処理(date,datetime)
現在の年度と俳優の出生年度で年齢を計算します。
MATCH (actor:Person)-[:ACTED_IN]->(:Movie) WHERE exists(actor.born) WITH DISTINCT actor, date().year - actor.born as age RETURN actor.name, age as <code>age today</code> ORDER BY actor.born DESC actor.name age today "Jonathan Lipnicki" 24 "Emile Hirsch" 35 "Rain" 38 "Natalie Portman" 39 "Christina Ricci" 40 "Emil Eifrem" 42 "Liv Tyler" 43 "Audrey Tautou" 44 "Charlize Theron" 45 "Jerry O'Connell" 46
date()処理です。
RETURN date(), date().year, date().month, date().day date() date().year date().month date().day "2020-03-20" 2020 3 20
datetime()処理です。
RETURN datetime(), datetime().hour, datetime().minute, datetime().second datetime() datetime().hour datetime().minute datetime().second "2020-03-20T13:31:31.741000000Z" 13 31 31
アウタージョンのような句(OPTIONAL MATCH)
繋がりを持たないパターンを漏れなく探索するときに使います。
MATCH (p:Person) WHERE p.name STARTS WITH 'James' OPTIONAL MATCH (p)-[r:REVIEWED]->(m:Movie) RETURN labels(p),p.name, type(r), m.title labels(p) p.name type(r) labels(m) m.title ["Person"] "James Marshall" null null null ["Person"] "James L. Brooks" null null null ["Person"] "James Cromwell" null null null ["Person"] "James Thompson" "REVIEWED" ["Movie"] "The Replacements" ["Person"] "James Thompson" "REVIEWED" ["Movie"] "The Da Vinci Code"
集合(collect)
Tom Cruiseは3本の映画に出演しています。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name ='Tom Cruise' RETURN p.name,m.title p.name m.title "Tom Cruise" "Jerry Maguire" "Tom Cruise" "Top Gun" "Tom Cruise" "A Few Good Men"
COLLECTは結果値をリストに与えます。
集合関数の前の列は暗黙的にグループ化されます(GROUP BY句は存在しません)。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name ='Tom Cruise' RETURN p.name,collect(m.title) p.name collect(m.title) "Tom Cruise" ["Jerry Maguire", "Top Gun", "A Few Good Men"]
集計(aggregation)
Tom Cruiseさんが出演している映画の本数を計算してみます。
集計関数の前の列は暗黙的にグループ化されます(GROUP BY句は存在しません)。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name ='Tom Cruise' RETURN p.name,count(m.title) p.name count(m.title) "Tom Cruise" 3
Cypherは集計しながら、その要素をリストにすることができます。
MATCH (p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name ='Tom Cruise' RETURN p.name,count(m.title), collect(m.title) p.name count(m.title) collect(m.title) "Tom Cruise" 3 ["Jerry Maguire", "Top Gun", "A Few Good Men"]
集計関数はcount()の他にも多数あります。
- count()
- sum()
- max()
- min()
- avg()
WITH
WITH句は実践的なCypherでとても重要な役割を果たします。
- WITHの宣言はとても簡単でRETURNをWITHに置き換えるだけです
- WITHはクエリブロックの実行結果をテンプレート化し、次のクエリブロックへ受け渡しを行います
- WITHは次のクエリブロックの前でソートや一意化、フィルターなどが実行できます
MATCH (a:Person)-[:ACTED_IN]->(m:Movie) WITH a, count(a) AS numMovies, collect(m.title) as movies WHERE numMovies > 1 AND numMovies < 4 RETURN a.name, numMovies, movies a.name numMovies movies "Laurence Fishburne" 3 ["The Matrix", "The Matrix Reloaded", "The Matrix Revolutions"] "Carrie-Anne Moss" 3 ["The Matrix", "The Matrix Reloaded", "The Matrix Revolutions"] "Charlize Theron" 2 ["The Devil's Advocate", "That Thing You Do"] "Tom Cruise" 3 ["A Few Good Men", "Top Gun", "Jerry Maguire"] "Kevin Bacon" 3 ["A Few Good Men", "Frost/Nixon", "Apollo 13"] "Kiefer Sutherland" 2 ["A Few Good Men", "Stand By Me"] "J.T. Walsh" 2 ["A Few Good Men", "Hoffa"] "Bonnie Hunt" 2 ["Jerry Maguire", "The Green Mile"] "Jerry O'Connell" 2 ["Jerry Maguire", "Stand By Me"]
UNION
UNION ALLは複数のクエリの結果値を無操作で結合します。
WITH [1,2,3,4,5] AS list UNWIND list AS n RETURN n UNION ALL WITH [1,2,3,4,5] AS list UNWIND list AS n RETURN n n 1 2 3 4 5 1 2 3 4 5
UNIONは複数のクエリの結果値の重複を排除します。
WITH [1,2,3,4,5] AS list UNWIND list AS n RETURN n UNION WITH [1,2,3,4,5] AS list UNWIND list AS n RETURN n n 1 2 3 4 5
サブクエリ
CALL { Cypher構文 }のようにネストしたクエリを実行し、そのリターン値を上位のクエリブロックから利用できます。
CALL {
CALL {
MATCH (p:Person) WHERE p.name = 'Tom Hanks' RETURN p
}
RETURN p
}
RETURN p.name
p.name
"Tom Hanks"
ノードとリレーションシップの登録・更新
シングルノードの登録(CREATE)
ムービーグラフにノードを追加してみます。
CREATE (m:Movie {title: ‘Batman Begins’})
RETURN m

マルチノードの登録
コンマ区切りで複数のノードを登録してみます。
CREATE
(:Person {name: 'Michael Caine', born: 1933}),
(:Person {name: 'Liam Neeson', born: 1952}),
(:Person {name: 'Katie Holmes', born: 1978}),
(:Person {name: 'Benjamin Melniker', born: 1913})
結果を確認してみます。
MATCH (p:Person) WHERE p.name IN ['Michael Caine','Liam Neeson','Katie Holmes' ,'Benjamin Melniker'] RETURN id(p), labels(p),p.name id(p) labels(p) p.name 172 ["Person"] "Michael Caine" 173 ["Person"] "Liam Neeson" 174 ["Person"] "Katie Holmes" 175 ["Person"] "Benjamin Melniker"
プロパティのマージ( SET プロパティ = )
SET句はプロパテキーが存在すれば上書きし、存在しなければ追加します。
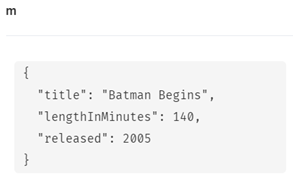
MATCH (m:Movie) WHERE m.title = 'Batman Begins' SET m.released = 2005, m.lengthInMinutes = 140 RETURN m
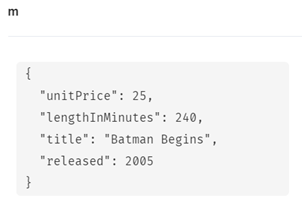
m.lengthInMinutesを変更し、m.unitPriceを追加してみます。
MATCH (m:Movie) WHERE m.title = ‘Batman Begins’ SET m.released = 2005, m.lengthInMinutes = 240, m.unitPrice= 25 RETURN m
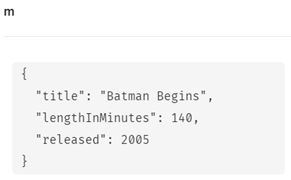
プロパティを全てリセット (SET 識別子 = )
次のようにマップ形式で指定すると、既存のプロパティをすべてリセットします。
- SET <識別子> = { key:value,key:value,…}
MATCH (m:Movie)
WHERE m.title = 'Batman Begins'
SET m = { title: 'Batman Begins',
released : 2005,
lengthInMinutes : 140
}
RETURN m
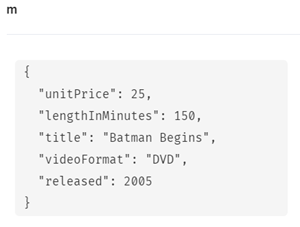
プロパティをマージ (SET <識別子> +=)
次のようにマップ形式で指定すると、既存のプロパティをマージします。
- SET <変数> += { key:value,key:value,…}
MATCH (m:Movie)
WHERE m.title = 'Batman Begins'
SET m += {
lengthInMinutes : 150,
videoFormat: 'DVD',
unitPrice : 25
}
RETURN m
プロパティを削除(NULL or REMOVE)
プロパティキーを削除してみます。
- REMOVE or NULL
MATCH (m:Movie) WHERE m.title = ‘Batman Begins’ SET m.unitPrice = null REMOVE m.videoFormat RETURN m
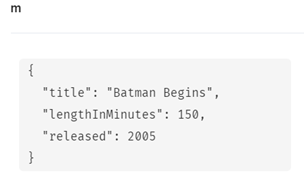
リレーションシップの登録(CREATE)
出演のリレーションシップを作成してみます。
MATCH (a:Person), (m:Movie) WHERE a.name = 'Michael Caine' AND m.title = 'Batman Begins' CREATE (a)-[:ACTED_IN]->(m) RETURN a, m
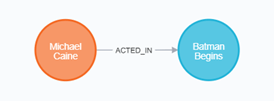
出演とプロデュースの複数のリレーションシップを作成してみます。
MATCH (a:Person), (m:Movie), (p:Person) WHERE a.name = 'Liam Neeson' AND m.title = 'Batman Begins' AND p.name = 'Benjamin Melniker' CREATE (a)-[:ACTED_IN]->(m)<-[:PRODUCED]-(p) RETURN a, m, p
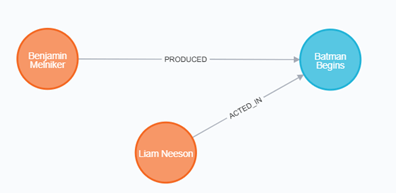
リレーションシップのプロパティを登録( SET プロパティ = )
リレーションシップにプロパティを登録してみます。
MATCH (a:Person), (m:Movie) WHERE a.name = 'Christian Bale' AND m.title = 'Batman Begins' CREATE (a)-[rel:ACTED_IN]->(m) SET rel.roles = ['Bruce Wayne','Batman'] RETURN a.name, type(rel), rel.roles, m.title a.name type(rel) rel.roles m.title "Christian Bale" "ACTED_IN" ["Bruce Wayne", "Batman"] "Batman Begins"
リレーションシップのプロパティ削除(REMOVE)
リレーションシップのプロパティを削除してみます。
MATCH (a:Person)-[rel:ACTED_IN]->(m:Movie) WHERE a.name = 'Christian Bale' AND m.title = 'Batman Begins' REMOVE rel.roles RETURN a.name, type(rel), rel.roles, m.title a.name type(rel) rel.roles m.title "Christian Bale" "ACTED_IN" null "Batman Begins"
ノードとリレーションシップの削除(DELETE)
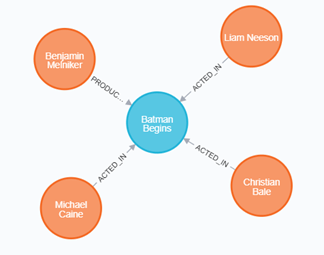
Batman Beginsのパターンを表示してみます。
MATCH (a:Person)-->(m:Movie) WHERE m.title = 'Batman Begins' RETURN a, m
Christian Baleノードを削除してみます。
MATCH (a:Person)-[rel:ACTED_IN]->(m:Movie) WHERE a.name = 'Christian Bale' AND m.title = 'Batman Begins' DELETE a Neo.ClientError.Schema.ConstraintValidationFailed Cannot delete node<93>, because it still has relationships. To delete this node, you must first delete its relationships.
このようにリレーションシップが存在する場合、そのノードは削除できません。
リレーションシップを削除してみます。
MATCH (a:Person)-[rel:ACTED_IN]->(m:Movie) WHERE a.name = 'Christian Bale' AND m.title = 'Batman Begins' //RETURN a, m DELETE rel Deleted 1 relationship, completed after 4 ms.
リレーションシップが削除できました。
MATCH (a:Person), (m:Movie) WHERE a.name = 'Christian Bale' AND m.title = 'Batman Begins' RETURN a, m

では、ノードを削除してみます。
MATCH (a:Person) WHERE a.name = 'Christian Bale' DELETE a Neo.ClientError.Schema.ConstraintValidationFailed Cannot delete node<93>, because it still has relationships. To delete this node, you must first delete its relationships.
確認できてないリレーションシップが存在しているようです。
MATCH p=(a:Person)-->() WHERE a.name = 'Christian Bale' RETURN p
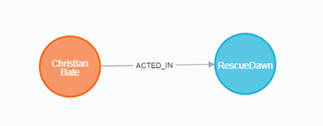
このようなノードの削除はDETACH句を併用することで強制的に削除できます。
- DETACH DELETE句はリレーションシップを無視してノードを削除します
- 危険なので使う時の要件に注意して下さい
MATCH (a:Person) WHERE a.name = 'Christian Bale' DETACH DELETE a Deleted 1 node, deleted 1 relationship, completed after 1 ms.
次のようにリレーションシップとノードは同時に削除できます。
MATCH (a:Person)-[rel:ACTED_IN]->(m:Movie) WHERE a.name = 'Liam Neeson' //RETURN a,m DELETE a, rel Deleted 1 node, deleted 1 relationship, completed after 2 ms.
マージによる登録・更新
マージによるノードの登録
ノードが存在しなければ登録し、存在すれば更新します。
まず、Michael Caineノードの存在を確認します。
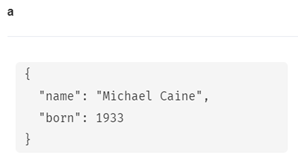
MATCH (a:Person {name: 'Michael Caine'})
RETURN a
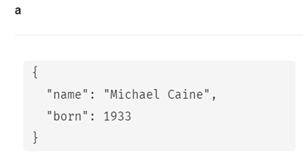
ActorラベルでMichael Caineノードをマージしてみます。
MERGE (a:Actor {name: 'Michael Caine'})
SET a.born = 1933
RETURN a
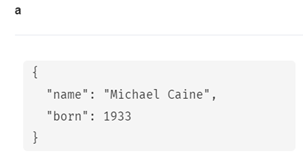
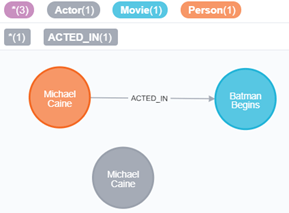
次のようにMichael Caineを検索してみると、ラベル違いで「Michael Caine」が2つになっています。
MATCH (a { name: 'Michael Caine'}), (m:Movie)
WHERE m.title = 'Batman Begins'
RETURN a, m
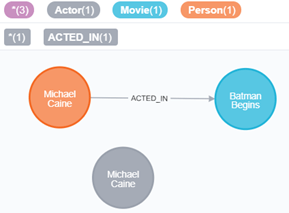
ActorラベルのMichael Caineのマージを実行してみます。
この処理は、何度実行しても上書きされます。
MERGE (a:Actor {name: 'Michael Caine'})
SET a.born = 1933
RETURN a
MATCH (a { name: 'Michael Caine'}), (m:Movie)
WHERE m.title = 'Batman Begins'
RETURN a, m
マージによるプロパティの登録・更新(ON CREATE SET/ON MATCH SET)
ノードが存在するときと存在しないときに分けてSETのプロパティを指定できます。
- ON CREATE SET・・・ノードが存在せず、新規登録する時にプロパティを設定します
- ON MATCH SET ・・・ノードが存在する時にプロパティの追加又はプロパティの更新を行います
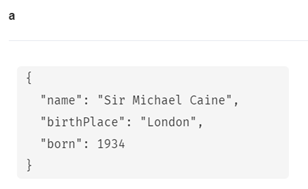
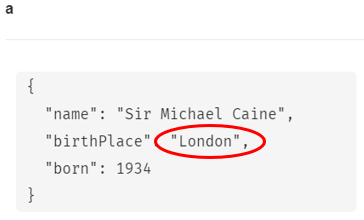
ON CREATE SET句を使ってSir Michael Caineという名前でマージを実行してみます。
MERGE (a:Person {name: 'Sir Michael Caine'})
ON CREATE SET a.birthPlace = 'London',
a.born = 1934
RETURN a
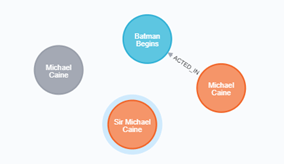
結果をみると、名前が異なるためにノードが追加されていることが分かります。
MATCH (a), (m:Movie { title: 'Batman Begins'})
WHERE a.name ENDS WITH 'Caine'
RETURN a, m
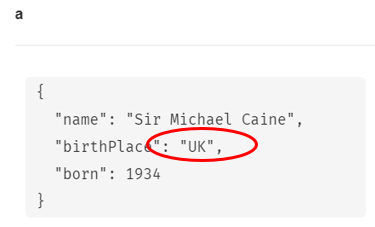
もう一回、ON CREATE SET句を使ってSir Michael Caineのマージを実行してみます。
MERGE (a:Person {name: 'Sir Michael Caine'})
ON CREATE SET a.birthPlace = 'UK',
a.born = 1934
RETURN a
結果を見るとスルーされていることが分かります(すでに存在するために)。
ON MATCH SET句を使ってSir Michael Caineのマージ実行してみます。
MERGE (a:Person {name: 'Sir Michael Caine'})
ON MATCH SET a.birthPlace = 'UK',
a.born = 1934
RETURN a
今回は反映されています。
要件に応じてON CREATE SETとON MATCH SETはペアで使用することもできます。
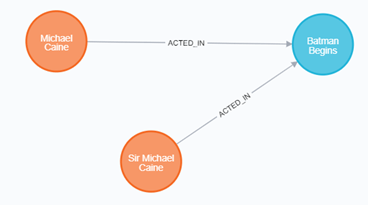
マージによるリレーションシップの登録
Caineで終わる名前の人をBatman Beginsにリレーションシップを張ります。
MATCH (p:Person), (m:Movie) WHERE m.title = 'Batman Begins' AND p.name ENDS WITH 'Caine' MERGE (p)-[:ACTED_IN]->(m) RETURN p, m
まとめ
以上、今回の記事はNeo4jのオンライントレーニングから基礎的な構文を選別して紹介しました。
実践においてはもっと広いナレッジが必要でしょう。
参考になりそうなサイトを紹介します。
Neo4jのオンライントレーニングはこちらです。
基礎から覚えたい人におすすめです。
https://neo4j.com/graphacademy/online-training/
公式マニュアルはシンタックスの理解には欠かせません。
https://neo4j.com/docs/cypher-manual/4.0/
実践に参考になりそうな例文を探している人は、サンプルグラフ集(GraphGists)がおすすめです。
https://neo4j.com/graphgists/
オンラインサンドボックスでは実践的なデータモデルの見聞を広げることができます。
https://neo4j.com/sandbox/
構文の構成要素を参照したい人はこちらを見てください。
https://neo4j.com/docs/cypher-refcard/current/
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



