
Neo4j-グラフデータベースとは #neo4j
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
これからCL-Labでは、グラフデータベースという新しいタイプのデータべースについて連載していきます。今回、紹介するNeo4jというグラフデータベースは、いくつかの基本的なデータ構造を理解し、Cypher(サイファーと読む)というSQLライクな言語を覚えるだけで、誰でもグラフ理論に基づいたデータ処理を利用することができます。今回は、第1回目として、グラフデータベースの背景の説明と共に、Neo4jのインストール、Cypher QLの操作方法を簡略に紹介します。
グラフデータベースは、グラフを描くデータベースではなく、グラフ理論の頭脳をもってデータ処理を行うことができる、とても汎用性の高いデータベースです。グラフを描く能力は、ただ、多様な才能の一つに過ぎません(筆者注)
関連記事-CL-Lab
Neo4j-グラフデータベースとは
Cypher Query Language(QL)-構成要素編
Cypher Query Language(QL)-初級編
Neo4j-大量データの読み込み
関連記事-Qiita
WindowsでNeo4jを使ってみる
MacでNeo4jを使ってみる
SoftLayerでNeo4jを使ってみる
AWSでNeo4jを使ってみる
Neo4jウェブインターフェースを使い倒す
グラフデータベースとは
ここでは、グラフデータベースの理論的な背景や様々なデータベースの仲間に加わることになった経緯などについて簡略に説明します。
グラフとは
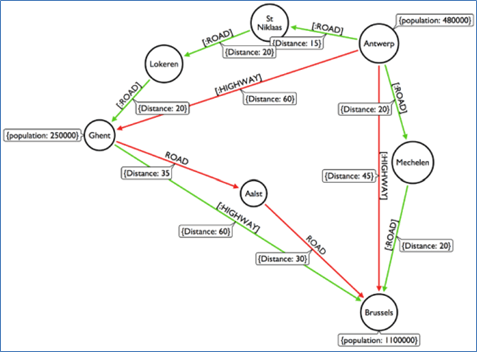
グラフとは何でしょうか。社内でNeo4jを紹介した時に聞いた第一声でした。Google辞書から調べてみると「二つ以上の数量や関数の関係を図形に示したもの」と定義しています。さらに調べてみると、グラフという数学のジャンルは、18世紀頃から始まり、現在は歴然とした数学の一分野として、様々な分野で複雑な問題解決の手段として活躍していることが分かりました。それは、科学の分野だけではなく、産業分野でも様々なジャンルで利用されてきたことが分かりました。例えば、最も身近なものとしては、経路を探るためのグラフがあります。次の図のようなグラフは、始点から終点までの経路が、何種類あるのか、最短経路はどれか、最も低コストの経路はどれかなどを探ることができます。もちろん、このほかにも様々なタイプのグラフがあります。

出典:Learning Neo4j、Rik Van Bruggen
次の図は、花火の現代アートに見えるかも知れませんが、グラフ表現の一つです。
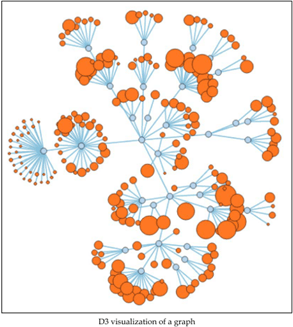
出典:Learning Neo4j、Rik Van Bruggen
次の図は、ぺルシャ絨毯の模様集めに見えるかも知れませんが、これもすべてグラフ表現です。
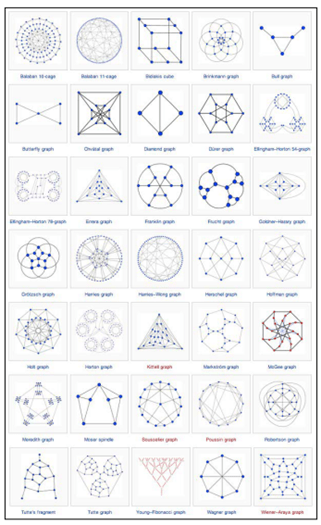
出典:Learning Neo4j、Rik Van Bruggen
グラフ理論の起源
グラフ理論の起源には実に面白いエピソードがあります。グラフ理論は18世紀、プロイセン王国の首都にある「ケーニヒスベルク」という町(現ロシア連邦カリーニングラード)から始まったそうです。その町には、プレーゲルという川があり、そこには7つの橋が架けられていたそうです。そして、いつの間かに、その橋のある時点から歩き始め、この7つの橋を2度渡ることなく、全て1度ずつ通って元に戻ってくる経路は存在するのかどうか、という話題が盛り上がったそうです。おそらく、多くの人が自分で歩いてみたり、描いてみたりしたに違いありません。

出典:Learning Neo4j、Rik Van Bruggen
そこで、1736年。オイラーという学者が表れ、左側の現実世界を右側の点と線、つまり、グラフに置き換えて、いわゆる「ケーニヒスベルクの問題」を解決したそうです。結論をいうと、話題になっていたような幻のルートは存在しないことを証明したらしいです。つまり、議論を続けても、試行錯誤をしてみても、なかなか結論が出なかったある種の問題が、グラフを利用することにより単純明快に解決できたわけです。数学の世界でこの話は、「ケーニヒスベルクの問題」と言って、グラフ理論の起源として知られているらしいです。
グラフ理論がなぜデータベースエンジンに採用されたのか
お絵描きしかできなさそうなグラフ理論がどうやってデータベースの設計思想として採用されたのでしょうか。簡略に言うと、データベースの王者、リレーショナルデータベースに不向きな複雑な関係性を持ったデータ処理の要求を解決するためでした。次の図のようにリレーショナルデータベースのデータ処理は集合論に準拠していますから、相対的にグラフ理論に比べてデータの複雑さへの対応には限界があります。
コッドさんが、リレーショナルデータベースに関する最初の論文を発表したのが1969年、今日のようなSQLが登場したのが1976年で、Oracle が登場したのか1983年ですが、この数十年はデータベースにおいても大変動の時代でした。社会全体にコンピューターが普及し、そのコンピューター同士がネットワークで繋がり、インターネットが登場しました。そのなかで、データベースはかつて経験したことのない新たな局面を迎えます。それは「暴走するデータの量の問題と、どんどん複雑になっていくデータの関係性の問題」でした。データべースは、このような社会的な環境変化に順応する形で、生物学でいう種の爆発のような進化を成し遂げて来ました。現在は、3桁の数字になるぐらいの多数多様なデータベースが存在する時代になっています。アーキテクチャーやデータモデルも多様な種類が登場しています。下記は、代表的なデータベースのアーキテクチャーとデータモデルです。
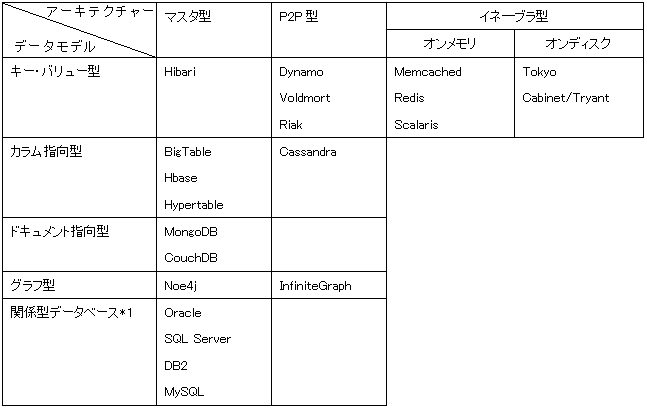
出典:NoSQLの基礎知識,リックテレコム,2012
*1)関係型データベースは、筆者が追加しています。
では、次の図をみてください。この図は、データベースの進化の方向を示しています。データベースの進化は、おおよそ、この4つの方向に向かっていると言われています。どれもすべての要求を完全に満たすデータベースは存在しません。他のデータベースはともかく、グラフのデータベースは、その優れた頭脳を生かし、とても複雑な関係性を持ったデータ処理に適したデータベースとして進化しています。
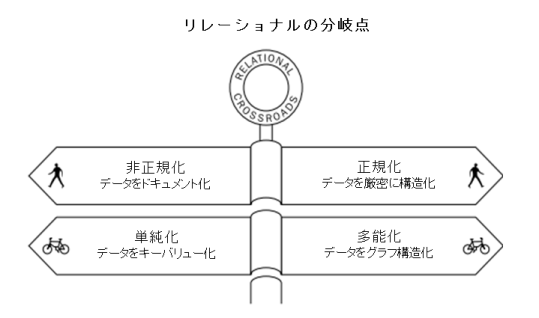
出典:Learning Neo4j、Rik Van Bruggen
この図の翻訳にはかなり悩みました。原文に忠実にしようすると、なんだか物足りない感をぬぐいきれなくて、筆者の独断でかなり意訳した箇所が多少あります。予めご了承お願いします(筆者注)
Neo4jとは
Neo4jはグラフデータベース
Neo4jは、「Neo Technology社」が開発したグラフデータベースであり、下記のような特徴を持っています。
- Neo4jの最大の特徴は、グラフ理論に基づいたデータベース最高の頭脳を持っていることです。これは、本記事全般を通して説明していきます。
- ドキュメント型データベースのようにスキーマレスでデータとデータ間の関係性をアプリで簡単に実装できます。データモデリングの側面では、映画や人などの実体の定義、データ間の関係性の定義、実体や関係性が持つ具体的な情報として属性の定義などが必要です。これは、関係型データベースの正規化モデルとは違いますが、その知識はほぼそのまま活かせます。
- データの操作はSQLライクなCypher QL(Cypher Query Language)を使って行います。Cypher QLは、誰でも短時間で習得して使うことができて、Neo4j標準のウェブインターフェースやNeo4-jシェル、REST APIなど複数の方法で実行できます。Cypher QLは、リレーショナル型データベースなどでは対応困難な、とても複雑な関係のデータ処理のために開発されたクエリ言語です。
- Cypher QLの実行結果は、その場で結果値をデータとして受け取るか、グラフとして見ることができます。グラフ化は、標準のブラウザー、オープンソース系のツール、サードパーティのツールなどが利用できます。
- ノード単位(レコードようなもの)のトランザクション処理が可能であり、ACIDが保証されます。そして、分離レベルは、READ COMMITTED ( 確定した最新データを常に読み取る )を提供しています。他のデータベース同様、Neo4jもデットロックが発生する可能性はありますが、デットロックを検知するクラスを提供し、アプリケーションで制御することができます。
- バッチ処理のためにはneo4j-shell、CSVやJSON形式の大量データのアップロードのためにはneo4j-import、フルバックアップやインクリメンタルバックアップ、バックアップのリストアのためにneo4j-backupが利用できます。
- Neo4jは、Javaで開発されていますが、REST APIを利用し、Java/.NET/JavaScript/Python/Ruby/PHPなどの言語でアプリの開発が可能です。
さらに詳しい情報は、下記の本家のホームページを参照してください。
Neo4jの生い立ち
Neo4jの開発は、2000年ごろから、関係型データベースのパフォーマンス問題を解決するために始まったようです。
2000 – Neo’s founders encountered performance problems with RDBMS and started building the first Neo4j prototype
2002 – Developed the first ever version of Neo4j
2003 – First 24×7 production Neo4j deployment
2007 – Formed a Swedish-based company behind Neo4j. Also open sourced the first graph database, Neo4j, under the GPL
2009 – Raised seed funding from Sunstone and Conor and continued development
2010 – Released Neo4j version 1.0
2011 – Raised A round and moved headquarters to Silicon Valley.
データベースのアーキテクチャー
データベースのアーキテクチャーは、大きくマスター型とP2P型がありますが、Neo4jのアーキテクチャーは、マスター型です。
マスター型のアーキテクチャー
このタイプは、すべてのデータ及びシステムの状況をマスターデータベース1本に集中して管理しています。つまり、基本的にサーバー1台の構成です。このタイプのデータベースは、データ管理の品質が高く、運用も容易であるために、長い間、業務系データベースとして広く支持を集めてきました。殆どの関係型データベースがこのタイプです。
しかし、マスター型のデータベースは、障害時にデータを失ってしまう可能性があります。だだ、この単一障害点は、他のサーバーにマスターデータベースのレプリケーションを作ることによって回避できます。マスターデータベースが壊れた場合は、レプリカのなかで一つをマスターデータベースとして利用できます。いわゆる高可用性構成が可能です。さらに、レプリカを読み取り用のデータベースとして利用することで、データベースへの負荷を分散させることもできます。
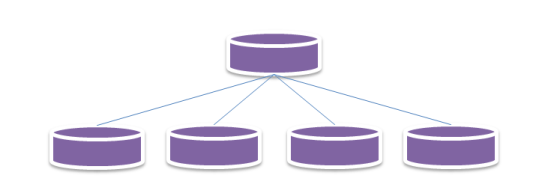
Neo4jの場合、残念ながら高可用性構成やリードレプリカなどが利用できるのは、商用版のみです。但し、コミュニティ版でも、DRBD(Distributed Replicated Block Device)などを利用し、データベースファイルが格納されているディスクを丸ごと複製することによって、高可用性構成にすることが可能です。
P2P型のアーキテクチャー
P2P(ピア・ツゥ・ピア)型は、マスターデータベースに相当するものは存在しません。個々のデータベースがお互いのメタ―情報を共有しており、同じデータのレプリケーションを複数持っているために、単一障害点(SPOF:Single Point Of Failure)が存在しません。このタイプのデータベースは、そもそも複数のサーバーを並べて、データを分散してもつことを前提にしているアーキテクチャーですから、ビックデータを複数のサーバーに分散してもつことに、とても強い特徴をもっています。
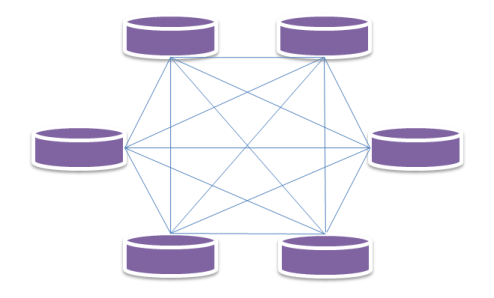
データベースのアーキテクチャーがマスター型か、P2P型かによって、データを複数のサーバーに分散できるかどうかの問題は存在しません。どちらのアーキテクチャーでも、ビックデータを複数のサーバーに分散して持つことができます。但し、Neo4j(2.2.x, 13 February, 2015)は、複数のサーバーにデータを分散できるようにはなっていません。高可用性構成やリードレプリカのためのマスターデータベースの複製のみが可能です。
データモデル
Noe4jは、しっかりした「グラフ構造のデータモデル」をもっています。「グラフ」の最小単位は「ノード」です。そして、ノードとノードが多様な関係性を持って絡み合っている形状を「パターン」といいます。ノードは、ラベル、関係性、属性をもちます。関係性はノード間のタイプを示し、属性を持ちます。
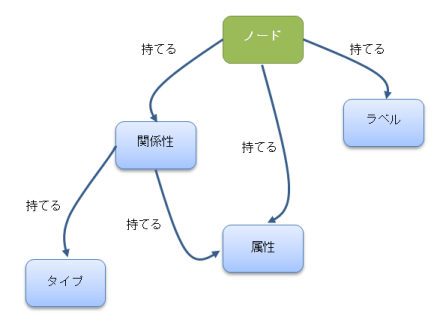
データモデリング
どのようなデータベースでも、データ処理を行うためには、ソースデータを目的に沿って種類や役割などを考慮し、分類したり、関係性を割り出したりし、誰もが分かるような形で文書化する必要があります。また、それは誰がやっても同じようなアウトプットにならなければなりません。それらの作業をデータモデリングといいます。この作業は、ある程度Cypher QLを理解してから扱ったほうが分かりやすいために、今回の連載では後半に紹介します。但し、難しいんじゃないか、という先入観を持つ必要はまったくありません。関係型データベースの正規化の概念は、そのまま活かせます。グラフデータモデルは、正規化モデルに比べて、はるかに分かりやすい構造になります。なぜかというと、関係性を明確に言葉で定義し、データモデルに書くからです。グラフデータベースで口酸っぱく言っている、このデータの関係性も、よく考えてみれば、関係型データベースで、複雑なSQLは殆どデータ間の関係性の問題が絡んでいたはずです。例えば、「知っている」ということに対して、「好感をもっている」は「フラグ1」、「好感を持っていない」は「フラグ0」のような表現でデータ処理をやってきたはずです。Neo4jになると、関係性はより人間の思考に近い形で独立した要素として扱います。
Neo4jの3大要素
Neo4jは、下記のような3つの基本要素で構成されています。
ノード(node)
ノードは、Neo4jでデータの基本単位です。属性を持つことでレコードのような枠割を果たします。「ラベル」は、同じような種類や性質のノードを代表するグループ名です。例えば、(person:人)で「人」は、「李」、「須藤」、「安田」などのノードには、人というレベルを付けてテーブルのように扱うことができます。下記の例で「company:会社」のような定義は「識別子:ラベル」という意味の書式であり、ユーザが任意に定義します。ラベルは永続的ですが、識別子は1構文のなかでデータパターンを一意的に識別するためのテンポラリ的な定義です。検索(match)のときに、ノードを「company:会社」と定義したからと言って、識別子を「company」にする必要はありません。(c:会社)でも(cc:会社)でも(n:会社)でもいいです。ここで、「へえ~、日本語でいいのお~」と仰る方がいらっしゃるかもしれません。問題ありません。但し、大量のデータを扱う時は、パフォーマンスに影響する可能性があると関係者の方に言われました。とりあえず、CL-Labの連載では分かり易さを重視していきます。
CREATE (company:会社 { name: "クリエーションライン"})
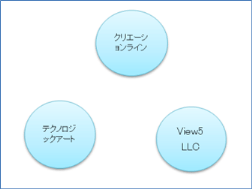
ノードは、リレーショナルデータベースで言えば、レコード的なものですが、ラベルをつけてグループ化するとテーブルのような扱いもできます。下記のように「会社」とラベルの下に複数の属性を束ねることができます。そうなると、会社というテーブルに複数のレコードが存在するような扱いができます。
create (company:会社 { name: "クリエーションライン"})
create (company:会社 { name: "テクノロジックアート"})
create (company:会社 { name: "View5 LLC"})
リレーショナルデータベース的に表現すると、次のようになります。
| 会社テーブル |
| クリエーションライン |
| テクノロジックアート |
| View5 LLC |
しかし、Neo4jでこれらは、関係性をもたない3つのノードです。ノードは、リレーショナルデータベースで言えば、テーブル的な機能も、レコード的な機能も果たしますが、テーブルでもレコードでもありません。
属性(property)
属性は「キー:バリュー」の書式で、ノードと関係性の両方に設定できます。例えば、(person:人)というノードの属性には、「名前」、「性別」、「年齢」、「住所」、「電話番号」などが設定できます。関係性を示す「知っている」というタイプには、「好感を持っている」、「好感は持っていない」、「趣味があう」、「趣味が合わない」などの属性が設定できます。下記の例で{ name:"李" }の部分が属性の定義であり、書式は{キー:"バリュー"}です。コンマで区切って、{name: "李",address: "東京都",tel="090-9999-9999",・・・ }のように複数の属性を登録することもできます。
CREATE (engineer:技術者 { name:"李" })
関係性(relationship)
ノードとノードの間に存在し、タイプという関係性の名称で関係の種類と、とちらかの方向を示し、さらに属性を持つことができます。下記の「(company)-[roles:雇用している]-> (engineer)」が関係性の定義です。これは、「クリエーションライン社が李という技術者を雇用している」という関係性の表現です。ハイフン(-)は方向が存在しない関係性、ハイフンリダイレクト(->)は関係性の方向を示します。マニュアルの例示をみると、映画を題材にして「ACTED_IN」とか、「DIRECTED」のような関係性が登場し、一瞬、予約語に見えてしまいますが、それは単に「出演した」とか、「監督した」とかの英語的な関係性の表現であるだけです。
MATCH (company:会社 { name:'クリエーションライン' }),(engineer:技術者 { name:'李' })
MERGE (company)-[roles:雇用している]->(engineer)
上記の実行結果は、次のようなシンプルなグラフになります。

データサイズとファイルサイズの制限
データサイズ
Neo4j v2.xまで、ノードとリレーションの数の制限は、それぞれ340億件、属性は2740億件でした。
Neo4j v3.0からデータストアに格納できるノードやリレーション、プロパティ、インデックスの数などのすべての制限がなくなりました。Neo4jは、そのためにデータストアのフォーマットを再設計し、インデックスの構造にも手を入れています。
データベースのファイルサイズ
データベースファイルのサイズは、OSが許容する最大サイズまでです。
スキーマレス
Neo4jでは、データを登録する前にテーブルを作ったり、なんらかのデータストアを作ったりする必要はありません。Neo4jでデータの構造が決まるのは、Cypher QL構文が実行され、データが登録されるときです。入力データは、CSVやJSON形式のどちらでもいいです。このスキーマレスの特徴は、ドキュメントタイプのデータベースに似ています。
実は、Neo4jでは「スキーマ」という言葉をなんらかのデータ構造とは全然異なる意味で使っています。Neo4jでスキーマというと、CONSTRAINT(UNIQUE INDEX)/INDEX/STATISTICを意味します。
Neo4Jがカバーできるデータ処理の方位
グラフデータベースを紹介しながら最も誤解してほしくないことは、グラフデータベースは限られた分野でしか使えないお絵描きツールみたいな印象を持ってしまうことです。グラフデータベースは、グラフを描くデータベースではなく、グラフ理論の頭脳をもってデータ処理を行うことができる、とても汎用性の高いデータベースです。グラフを描く能力は、多様な才能の一つに過ぎません。グラフデータベースは、JSON形式やCSV形式のログなどを蓄積して分析を行うような用途にも強力です。お急ぎのときは、とりあえず、正規化されたデータをそのまま移行してもデータ処理が可能です。特に分析系のデータ処理では、SQLライクな処理ができなかったり、できてもJOINが出来なかったりすると、それは致命的です。しかし、Cypher QLは、ドキュメント型のデータベースやリレーショナル型のデータべースの強みを合わせ持っています。例えば、JSONやCSV形式のデータをスキーマ定義なしで登録し、リアルタイムでJOINを含むSQLライクなCypher QLで集計などが可能です。この件は、今回の本題ではないので紹介する程度にさせて頂きます。下記は、簡単なカウントの例です。さらに詳しいことは、次回以降を楽しみにしてください。
create (book:Book { isbn:"1234567890", title:"Amazon Cloudテクニカルガイド", publisher:"インプレスジャパン",year:"2010", author:"李",price:"3900",page:"360"});
create (book:Book { isbn:"1234567891", title:"Amazon MapReduceテクニカルガイド", publisher:"インプレスジャパン",year:"2012", author:"李",price:"3900",page:"360"});
MATCH (b:Book) WHERE b.author="李" RETURN b.author AS 著者, count(*) AS 冊

Cypher QLは、実に強力な言語です。次の表を見てください。分析系のデータベースの利用でドキュメント型のエンジンだからJOINが出来ない、リレーショナル型ですが階層が複雑なJOINでパフォーマンスが出ない、他に何等かのプログラムを書かないといけない、といったような状況では、Neo4jが解決策になる可能性がとても高いです。そもそも、Neo4j誕生は、リレーショナルデータベースのパフォーマンス問題の解決がきっかけでした。現在も、様々なユースケースのなかで最も多いのは、他のデータベースエンジンで何等かの悩みを持っているユーザーがNeo4jに移行するケースだと言われています。
| 区分 | ドキュメント | リレーショナル | カラム指向 | キーバリュー | グラフ | |
| スキーマ定義 | × | ○ | △ | × | × | |
| データ更新 | △ | ○ | △ | △ | ○ | |
| トランザクション処理 | △ | ○ | × | × | ○ | |
| フィルター | ○ | ○ | ○ | ○ | ○ | |
| 集計 | ○ | ○ | △ | △ | ○ | |
| JOIN | × | ○ | × | × | ○ | |
| 関係化※1 | × | △ | × | × | ○ | |
| グラフ化※2 | × | × | × | × | ○ | |
凡例:○⇒できる、必要である △:エンジンに依存する ×:できない、要らない
※1 データ間の複雑な関係の定義や処理という意味です。
※2 グラフにして可視化するという意味です。
勿論、Neo4jが他のすべてのデータべースの代わりになれるという意味ではありません。まだ、進化の途上にあり、不向きもあります。しかし、Neo4jのデータ処理能力は、他のどんなデータベースよりも強力な汎用性を持っているらしい、ということを覚えて頂ければ幸いです。
Neo4jのライセンス
Neo4jのライセンスはGPLです。現在、ラインセンスは、コミュニティ版と商用版に分かれており、コミュニティ版はパフォーマンスキャッシュ、クラスター構成、ホットバックアップ、モニタリングなどのリッチな機能は使えない制約がありますが、とりあえず無料で利用できます。
- Enterprise
- Startup(3M-10M USD/Annual)
- Personal(10K USD/Annual)
- Community(Free)
詳しいことは、下記を参照してください。
- コミュニティ版と商用版の機能比較(http://neo4j.com/editions)
- サブスクリプション毎のサービス内容比較(http://neo4j.com/subscriptions)
日本国内でのNeo4jのライセンス及び技術的な相談などは、クリエーションライン(www.creationline.com)までにご連絡お願いします
ユースケース
日本国内では、これからという状況ですが、グローバルでは500社以上の導入事例があります。これらの企業は、既存のデータベースで何等かの限界にぶつかり、その解決策としてNeo4jへ移行するケースが最も多い割合を占めていると言われています。
詳しいことは、下記のURLを参照してください。
Neo4jを使ってみよう
今回は、Neo4jウェブインターフェースから簡単なデータ処理をやってみます。Neo4jは、Javaで開発されたソフトウェアで、Linux/Mac/Windowsに対応しています。下記の記事を参考にし、Neo4jの環境を用意してください。
WindowsでNeo4jを使ってみる
MacでNeo4jを使ってみる
SoftLayerでNeo4jを使ってみる
AWSでNeo4jを使ってみる
Cypher QLでデータ処理をやってみる
ここでは、デモデータではなく、手作りの「データ+Cypherクエリ」を使ってシンプルな関係性をもつグラフを作ってみます。Neo4jにおいて最小単位のグラフは、1つ以上の属性をもった1つのノードです。Neo4jウェブインターフェースのコマンドライン($)に、次のようなCypherクエリを入力し、画面の右上の実行(▶)をクリックします。
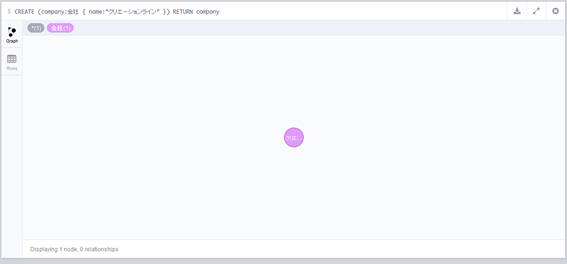
CREATE (company:会社 { name:"クリエーションライン" }) RETURN company
画面の下段に、次のような結果が表示されるはずです。この1点が最小単位のグラフです。このグラフは、「会社」というラベル、「クリエーションライン」という属性のノードであり、関係性は持っていません。
この構文をもう少し詳しく説明します。
| CREATE | 文 | 文字通りノードを作成するという宣言です |
| company:会社 | 識別子:ラベル | ノードを定義する書式です。(識別子:ラベル)は任意定義です。ラベルは永続的ですが、識別子は1構文のなかでしか使わないテンポラリ的な名称です |
| name:"クリエーションライン" | キー:バリュー | 属性を定義する書式です。「キー:バリュー」で表現し、コンマ区切りで複数定義することもできます |
| RETURN | 文 | 結果値を返還するという宣言です。 |
| company | 識別子 | 識別子の中身は、グラフ、リスト、マップなど多様です。 |
次は、クリエーションラインの社員を3名登録してみます。ブラウザーで操作するときに、1回で入力する構文は1個にしてください。3つを同時に流すと、1構文と認識し、識別子が重複するというシンタックスエラーになります。
CREATE (engineer:技術者 { name:"李" })
CREATE (engineer:技術者 { name:"須藤" })
CREATE (engineer:技術者 { name:"坂上" })
今回は、グラフの表示はされないはずです。RETURN文を指定していないからです。
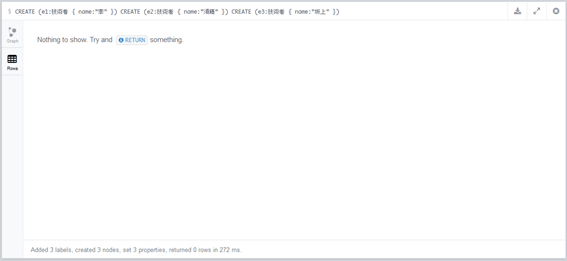
複数を構文を同時に流すときは、標準のブラウザーとNeo4j-シェルとの間で若干、違いがあります。標準のNeo4jウェブインターフェースでCypherクエリを操作するときは、1回で1構文の入力を推奨します。もし、ブラウザでこれらの3つの構文を1回で入力する場合は、ノードの(識別子:技術者)の書式で識別子を一意にすればいいです。サーバー上でシェル(neo4j-shell)を使う場合は、構文の最後にセミコロン(;)で区切りを付ければいいです。
では、今までの登録したグラフをすべて表示してみましょう。MATCHとは、関係型データベースのSELECT文に当たります。
MATCH all RETURN all
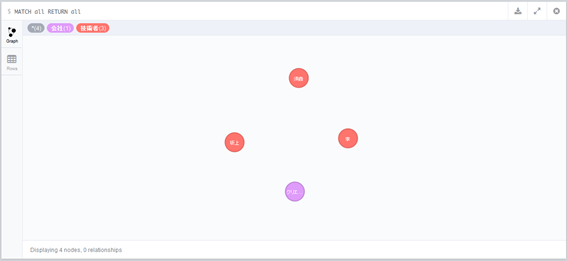
まだ、関係性を定義していないので、会社と技術者がバラバラな状態で表示されます。では、次のようなCypherクエリを入力し、関係を定義してみます。
MATCH (c:会社 { name:"クリエーションライン" }),(e:技術者 { name:"須藤" })
MERGE (c)-[r:雇用している]->(e)
MATCH (c:会社 { name:"クリエーションライン" }),(e:技術者 { name:"坂上" })
MERGE (c)-[r:雇用している]->(e)
MATCH (c:会社 { name:"クリエーションライン" }),(e:技術者 { name:"李" })
MERGE (c)-[r:雇用している]->(e)
このCypherクエリは、 (会社{"クリエーションライン" })ノードと (技術者{name="名前"})ノードとの関係性を定義しています。どうやら、「クリエーションライン社」は、技術者3人に対し、「雇用している」という関係性をもっているようです。ここで、MATCHとは、リレーショナルデータベースでいえば、SELECTとJOINの機能を同時に果たします。無理やりリレーショナル的に表現してみると、次のようになります。
SELECT c.name, e.name
FROM 会社 c, 技術者 e
WHERE c.company_id = e.company_id
AND c.name="クリエーションライン"
AND e.name="須藤";
そして、MERGEとは、リレーショナルデータベースでいえば、UPDATEに近いです。新たなノードを作らず、存在しているノード間の関係性だけを定義します。もし、これをリレーショナルデータベース的に表現しようとすると、関係性をもつテーブルを作成し、互いのIDで紐づけ、関係性の情報を登録するようなことが必要になるでしょう。しかも、ちゃんと表現できるかどうかは疑問です。
とにかく、検索をしてみましょう。下記は、「会社」というラベル付きで「クリエーションライン」という属性を持ったノードと、関係性を持っているすべてのノードを検索し、結果を返還する構文です。その結果は、下図の通り、「クリエーションライン社」は、「李、坂上、須藤」の3人の技術者を「雇用している」という関係性を持っているようです。このCypherクエリでは、会社ノードと社員ノードの間に「-[r]-」のように書いています。これは、すべてのタイプの関係性を検索対象にする、という表現です。
MATCH ( n:会社 { name: "クリエーションライン" })-[r]-() RETURN n,r
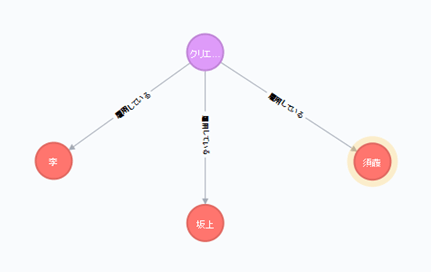
今回の記事でCypher QLの操作に関する紹介はここまでです。とりあえず、SQLそっくりの言語でデータ処理ができるんだ、というイメージを持って頂ければ幸いです。
最後に、この記事を読んで、とりあえず、Neo4jのマニュアルを見ながら独学をしてみたい方は、次のようなコマンドを覚えておくと便利です。
①すべてのグラフを表示したい
Cypher QLですべてのグラフを見るときは、次にようなクエリを使います。ノード数がとても多い場合は、LIMITの次に数字を設定し、表示する結果値を制限します。
MATCH n RETURN n
又は
MATCH (n) OPTIONAL MATCH (n)-[r]-() RETURN n,r [LIMIT number]
②すべてのグラフを削除したい
色々やっているうちに訳分からないグラフが一杯になってしまって紛らわしい、というときは、すべてを削除(DELETE)してしまえばいいです。
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
まとめ
今回は、第1回目として、Neo4j-グラフデータベースとSQLライクなデータ処理ができるCypher QL言語について、軽く紹介する程度に構成しています。これから、CL-Labでは、開発者向けのNeo4j-グラフデータベースの解説を掲載していきます。一緒に勉強していくつもりで見て頂ければ幸いです。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



