
mongo-connectorでMongoDBからElasticsearchへリアルタイム同期 #mongodb
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
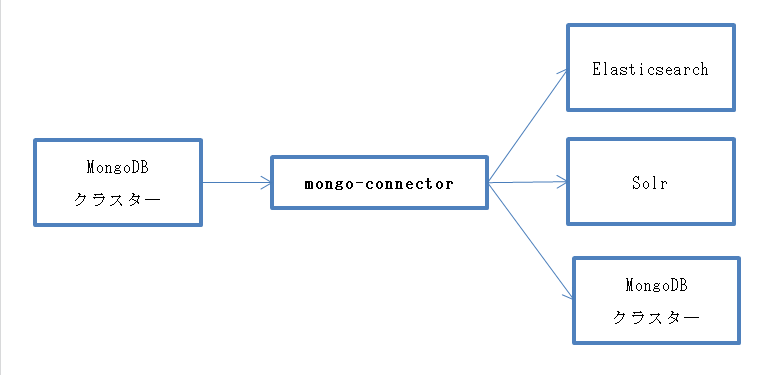
mongo-connectorは、MongoDBと他のデータストア(Solr、Elasticsearch、又は他のMongoDBクラスタ―)との間でパイプを作成し、MongoDBから既存のデータの同期を取ってから、増分のドキュメントに関しても継続的に同期を取ってくれるツールです。MongoDBクラスタ―は、プライマリとセカンダリとの間で同期を取るためにすべての変更をoplogに記録していますが、mongo-connectorはoplogのテールを取って来てターゲットストアに継続的に反映を行います。

- mongo-labsプロジェクトとして始まり、2017年6月以降では、YouGovでメンテナンスされている。
- ターゲットストアは、Solr、Elasticsearch、又は他のMongoDBクラスタ―に対応している。
- ライセンスは、Apache License2.0の下である。
- Python 3.4+及び MongoDB versions 3.4 and 3.6に対応している。
- MongoDBは、Oplogを取るためにレプリケーションモードである必要がある。
- 一時停止が発生しても停止した時点から再開してくれる。
- 不要なドキュメントはフィルターできる。
- ログなど運用のためのオプションも充実している。
- ドキュメントがとても充実している。
このような特徴から様々な応用ができそうですね。
* MongoDBが不得意とする日本語の全文検索を他のデータストアで行う。
* DR対策としてリモートのデータセンターにコピーを置く。
[参照サイト]
https://github.com/yougov/mongo-connector
https://github.com/yougov/mongo-connector/wiki
導入の流れ
-
MongoDBクラスタ―構築(MongoDB3.4/3.6)
-
Elasticsearchインストール(Elasticsearch5.x)
-
mongo-connectorインストール
MongoDBインストール
今回の検証では、既にあるMongoDBクラスタ―を利用しています。
クラスターは、必ずしも3台のレプリケーションセットである必要はありません。スタンドアロンのMongoDBをレプリケーションモードで起動し、rs.initiate()で1台のクラスタ―(プライマリ)にすることも可能です。
MongoDBを構築する必要がある人のためにスタンドアロンクラスタ―を構築する手順を簡略に紹介しておきます。
yumリポジトリをインストールします。
$sudo cat << EOF > /etc/yum.repos.d/mongodb.repo
[mongodb-enterprise]
name=MongoDB Enterprise Repository
baseurl=https://repo.mongodb.com/yum/redhat/\$releasever/mongodb-enterprise/3.6/\$basearch/
gpgcheck=0
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.6.asc
EOF
パッケージをインストールし、ユーザを作成します。
$ sudo yum install -y mongodb-enterprise-3.6.8 mongodb-enterprise-server-3.6.8 mongodb-enterprise-shell-3.6.8 mongodb-enterprise-mongos-3.6.8 mongodb-enterprise-tools-3.6.8
$ sudo systemctl start mongod
$ mongo
MongoDB Enterprise > show databases
admin 0.000GB
config 0.000GB
local 0.000GB
MongoDB Enterprise > use admin
switched to db admin
MongoDB Enterprise > db
admin
MongoDB Enterprise > db.createUser(
{
user:"root",
pwd:"Password",
roles: ["root"]
}
)
MongoDB Enterprise >exit;
認証を有効にし、レプリケーションモードで起動します。
$ sudo systemctl stop mongod $ sudo vi /etc/mongod.conf security: authorization: enabled replication: replSetName: myrepl $ sudo systemctl start mongod $ sudo systemctl status mongod
クラスタ―に切り替えて、初期データを登録しておきます。
$ mongo -uroot
MongoDB Enterprise > rs.initiate()
MongoDB Enterprise myrepl:SECONDARY>
MongoDB Enterprise myrepl:PRIMARY>
for(var i=1; i< 100000; i++) db.logs.insert({ "uid":i, "value1":Math.floor(Math.random()*10000+1), "value2": "AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA", "created_on" : Date.now() } )
MongoDB Enterprise myrepl:PRIMARY>exit;
MongoDB Atlasの無料枠を利用することもできます。
MongoDB Atlas Get started free
Elasticsearchインストール
Elasticsearch v5.6をダウンロードします。
[参照サイト]
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/installation.html
https://www.elastic.co/guide/en/beats/libbeat/5.6/elasticsearch-installation.html
$ curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.13.rpm $ sudo rpm -i elasticsearch-5.6.13.rpm $ sudo systemctl daemon-reload $ sudo service elasticsearch start $ sudo service elasticsearch status
インストールを確認します。特にエラーメッセージとかなく、次のように表示されたら成功しています。
$ curl http://127.0.0.1:9200
{
"name" : "owUN43l",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "n_qi3KvwQT-y9LQ8xjlTwQ",
"version" : {
"number" : "5.6.13",
"build_hash" : "4d5320b",
"build_date" : "2018-10-30T19:05:08.237Z",
"build_snapshot" : false,
"lucene_version" : "6.6.1"
},
"tagline" : "You Know, for Search"
}
日本語検索フラグイン(kuromozi)をインストール
Elasticsearchで日本語の検索のためには、フラグインをインストールする必要があります。
[参照サイト]
https://qiita.com/shin_hayata/items/41c07923dbf58f13eec4
https://www.elastic.co/guide/en/elasticsearch/plugins/5.6/analysis-kuromoji-analyzer.html
$ sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji
Elasticsearchのデータモデルは、次のとおりです。
| Elasticsearch | リレーショナルデータベース |
|---|---|
| Index | データベース |
| Type | テーブル |
| Document | レコード |
mongo-connectorインストール
mongo-connectorは、Python3.4+が必要です。
$sudo yum search python36 $sudo yum -y install python36 python36-devel $python3.6 --version $sudo python3.6 -m ensurepip $pip3.6 --version
mongo-connectorをインストールします。
$ sudo pip3.6 install mongo-connector $ sudo pip3.6 install 'mongo-connector[elastic5]' $ sudo pip3.6 install 'elastic2-doc-manager[elastic5]' $ mongo-connector --version mongo-connector version: 3.1.0
mongo-connectorの実行
config.jsonを編集します。ここでは、必須的なオプションだけにしています。
{
"mainAddress": "10.0.0.15:27000,10.0.0.16:27000,10.0.0.17:27000",
"oplogFile": "/tmp/oplog.timestamp",
"verbosity": 1,
"logging": {
"type": "file",
"filename": "/tmp/mongo-connector.log",
"__rotationWhen": "D",
"__rotationInterval": 1,
"__rotationBackups": 10
},
"authentication": {
"adminUsername": "root",
"password": "Password"
} ,
"namespaces": {
"test.logs": true
},
"docManagers": [
{
"docManager": "elastic2_doc_manager",
"targetURL": "localhost:9200"
}
]
}
スタンドアロンクラスタ―をローカルに構築している場合、次のように書き換えてください。
"mainAddress": "localhost:27017",
mongo-connectorを実行します。
$ mongo-connector --config-file=config.json Logging to /tmp/mongo-connector.log.
実行すると、初期データの同期が始まります。
Elasticsearchからマッピング情報を表示すると、スキーマが特定できます。
$curl -XGET 'http://localhost:9200/_all/_mapping?pretty=true'
{
"test" : {
"mappings" : {
"logs" : {
"properties" : {
"created_on" : {
"type" : "float"
},
"uid" : {
"type" : "float"
},
"value1" : {
"type" : "float"
},
"value2" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
},
"mongodb_meta" : {
"mappings" : {
"mongodb_meta" : {
"properties" : {
"_ts" : {
"type" : "long"
},
"ns" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
}
データの同期を確認するために、Elasticsearch側のトキュメント数をカウントしてみます。
今回の検証では、たままた、MongoDB側に4,100,000件のテストデータがありました。
$ curl -XGET 'http://localhost:9200/test/logs/_count?pretty=true'
{
"count" : 4100000,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
}
}
MongoDB側に日本語を追加します。
myrepl1:PRIMARY> db.logs.insert({ title: "晴れの日", body: "晴れの日は暑い" });
WriteResult({ "nInserted" : 1 })
myrepl1:PRIMARY> db.logs.insert({ title: "雨の日", body: "雨の日は湿度が高い" });
WriteResult({ "nInserted" : 1 })
myrepl1:PRIMARY>
Elasticsearch側で「暑く」で検索してみます。ダリレクとに「暑く」という言葉は、存在しない状態です。
curl -XPOST 'http://localhost:9200/test/logs/_search?pretty' -d '
{
"query": {
"match": {
"body" : "暑く"
}
}
}'
検索結果は、次のように返ってきました。つまり、多少言葉の揺れがあっても検索ができるということです。
{
"took" : 71,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.7261542,
"hits" : [
{
"_index" : "test",
"_type" : "logs",
"_id" : "5bf79d97f432d29096644190",
"_score" : 0.7261542,
"_source" : {
"title" : "晴れの日",
"body" : "晴れの日は暑い"
}
}
]
}
}
まとめ
mongo-connectorは、非常に完成度が高いという印象を受けました。今回は、紹介していないオプションも豊富にあります。アイデア次第では、色々応用が出来そうですね。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



