
Neo4jによる機械学習イノベーション #Neo4j #データ分析

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本ブログは、「Neo4j」社の技術ブログで2022年9月23日に公開された「A Machine Learning Innovation in Predictive Analytics」の日本語翻訳です。

グラフデータサイエンスを使用することによって機械学習の予測精度が改善するという人たちがいます。
この考えは美しく、確かにグラフは強力なツールです。我々はつながりを持つデータが予測精度を大幅に向上させるという仮説を、大理石のように堅固に証明し、その効力を測定したいと思っています。
データサイエンスのエコシステムにおいてはよく知られている科学論文のCORAデータセットでやってみましょう。Neo4jとこれから説明するグラフエンベディングを使用すると、与えられた研究論文の論文カテゴリを予測するタスクにおいて、数点の精度の改善が得られます。
イントロダクション
このブログの構成は次の通りです。はじめに、グラフテクノロジおよびNeo4jグラフプラットフォームの紹介を行います。次に、Neo4jグラフデータサイエンスについて詳しく掘り下げます。そして、Neo4j GDSを活用したデモを行います。すでにNeo4jのエコシステムについてよく理解しているなら、Neo4j GDSを活用したデモセクションに直接進んでも構いません。最後に、このブログ記事の重要なポイントをまとめます。
1. グラフテクノロジ
グラフテクノロジは、データの関連性をより直感的でつながりのある状態に統一し、より深い文脈を解き明かします。
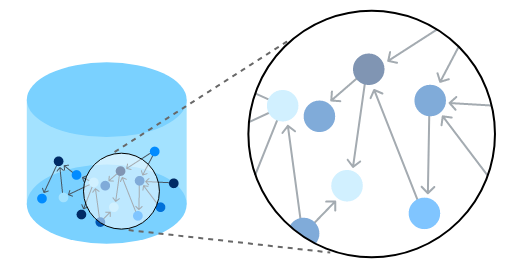
図1 -(人間やトランザクションなどの)グラフはデータをノードとリレーションシップとして結び付けます
データがグラフとして格納されると、それがどのようにつながっているかを理解するようになります。グラフテクノロジ以外では、2つのノード間のリンクが、何ホップも離れているため見えないこともあります。グラフデータベースは、つながりのあるデータ全体の深い経路をたどることを可能にするのです。グラフを通じて、信じられないような洞察が明らかになります。
Neo4jはグラフデータベースというカテゴリを創り出し、業界をリードしています。グラフデータベースは全てのデータマネジメントカテゴリの中で最も速く成長しているカテゴリです。Neo4jは800社以上の顧客を持っており、そのうち300社以上がグローバル企業です。
2. Neo4jグラフプラットフォーム
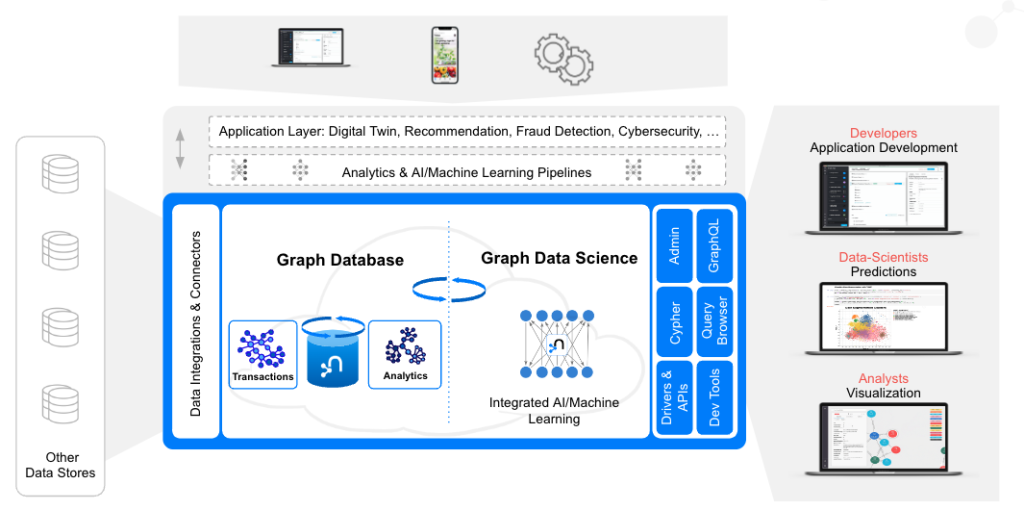
図2 - Neo4jグラフプラットフォーム
Neo4jグラフプラットフォームを簡潔に説明すると、下記のようになります。
- Neo4j Graph Databaseは、データだけでなくデータのリレーションシップも活用できるよう、ゼロから構築されたネイティブなグラフデータストアです。他のタイプのデータベースと異なり、Neo4jはデータのつながりをそのままの形で保存するため、これまで想像もしなかったようなクエリを、これまで想像もしなかったようなスピードで実行することができます。
- Neo4j Graph Data Scienceは、データサイエンティストがビッグデータのつながりを明らかにし、ビジネス上の重要な問題に答え、予測精度を向上させることを支援するソフトウェアプラットフォームです。
- Neo4j Bloomは、Neo4jのグラフを視覚的に操作するための、使いやすいグラフ探索アプリケーションです。Bloomは、グラフの初心者から専門家まで、さまざまなビジネスの観点からグラフデータを視覚的に調査・探索する能力を提供します。
- Cypherクエリ言語: Neo4jではデータ間の接続は保存され、クエリ実行時に計算されることはありません。Cypherは、グラフに最適化された強力なクエリ言語であり、保存されたデータ間接続を理解し、活用することができます。
- Neo4jはそれぞれのアーキテクチャでNeo4jを簡単に使用するためのいくつかのコネクタを提供し、一部のサードパーティー製ツールあるいはコミュニティ製ツールのインストラクションサポートを提供します。Neo4jは、Apache SparkやApache Kafkaをはじめ、さまざまなBIツールやデータサイエンススタジオと連携しています。Neo4jの公式ドライバはJava、JavaScript、python、.Net、Goをサポートし、GRANDstackのベースラインアーキテクチャによりGraphQLのサポートも最高レベルです。
- Neo4j developer toolsは、Neo4jによって提供された洗練されたツールで、グラフアプリケーションの開発を容易にするために設計されています。グラフプロジェクトを作成するためのNeo4j Desktop、グラフのクエリを実行するためのNeo4j Browser、データを素早くグラフに取り込むためのNeo4j Data Importerが含まれます。
Neo4j Graph Platformは、すぐに利用できるさまざまなクラウドデプロイメントオプションで実行することができます。今日では、Neo4jのカスタマーの50%以上がAWS、Azure、Google Cloud Platform (GCP)などのパブリッククラウド上でNeo4jを動作させています。もちろん、Neo4jはオンプレミス、プライベートクラウド、ハイブリッド環境でも動作します。
ここからは、Neo4j Graph Data Scienceにフォーカスしていきます。
3. Neo4j Graph Data Science
「データがあっても、質問がなければ役に立たない...」詠み人知らず。
では、Neo4j Graph Data Scienceでは、どのようなデータの質問に答えることができるのでしょうか?
それらは、3段階にまとめることができます。
- 何が重要なのか?
- 何が異常なのか?
- 次はどうなる?
それぞれの質問に対し、Neo4j Graph Databaseは効果的な答えを提供します。
- データの中で何が重要かを特定するためには、まずエンティティ同士をリレーションシップで接続し、ナレッジグラフを構築する必要があります。そうすることによって、つながりのあるデータの中で探しているパターンを見つけることができるようになります(Cypherクエリとグラフパターンを使用します)。
- 外れ値やクラスタやトレンドを検出するために、65種類を超えるグラフアルゴリズムがNeo4j Graph Data Scienceライブラリで使用可能です。
- 未来の予測をするために、機械学習モデルにグラフの特徴を与え、予測精度を向上させます。Neo4j Graph Data Scienceライブラリにはノード分類、ノード回帰、リンク予測の3種類のパイプラインが含まれます。
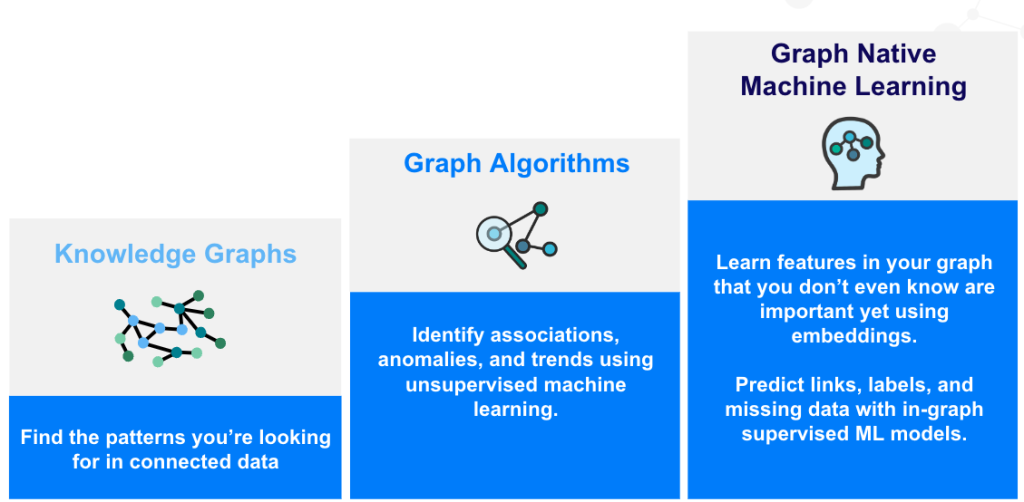
図3 - グラフデータサイエンスの成熟度のはしごを登る!
ある意味、この3つのステップは、あなたのグラフデータサイエンスの成熟度だと考えることができます。3つの質問を解決しようとするユースケースを増やせば増やすほど、グラフデータサイエンスの成熟度のはしごを登ることになるのです。
3.1. なぜNeo4j Graph Data Scienceを使用するのか?
3.1.1. メリット
Neo4j Graph Data Scienceには4つのキーアドバンテージがあります。
- 簡単に使用できる: ローコードやノーコードのツール、インテグレーション(統合)やワークフロー。クラウド経由での迅速な導入、緊密な統合、ワークフロー要素の自動化も可能。
- データサイエンティスト: 幅広いデータサイエンスアルゴリズム、Pythonなどの言語サポート、データソースとMLツールの両方への容易な接続性。
- エンタープライズに対応: あらゆる規模のお客様のニーズに対応する性能、信頼性、アーキテクチャの完全性。
- エコシステム: データシステム(データレイク、データウェアハウスなど)とGCP Vertex AI、AWS SageMaker、Azure Synapseなど他のテクノロジーの両方と簡単に相互接続可能。
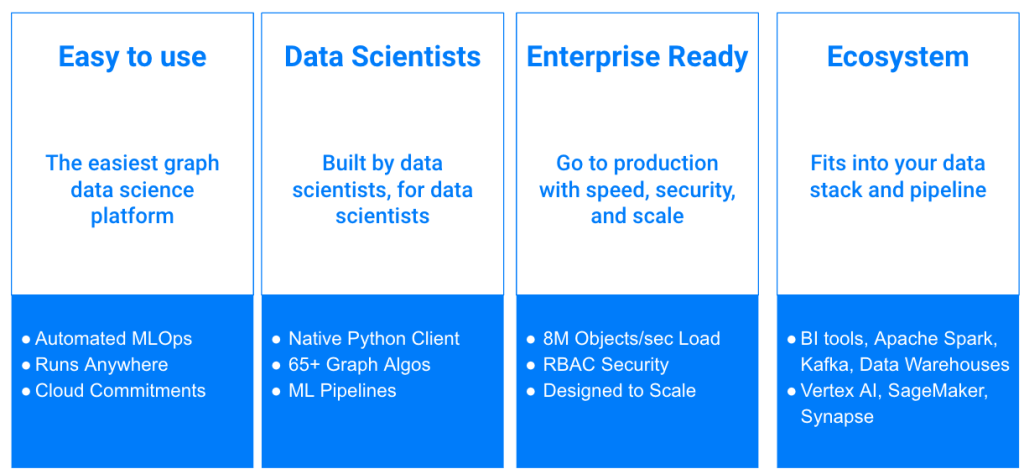
図4 - Neo4j Graph Data Scienceを使用することのメリット
3.1.2. アルゴリズムと機械学習
Neo4j Graph Data Scienceライブラリで使用可能なアルゴリズムは6つの主要なカテゴリに分類されます。
教師あり機械学習には、ノード回帰、ノード分類、リンク予測それぞれのパイプラインが含まれています。その他にも、多くの有用な補助関数やプロシージャがあります。最後に、Pregel Java APIでは、いくつかのインターフェースを実装することで、独自のアルゴリズムを構築することができます。
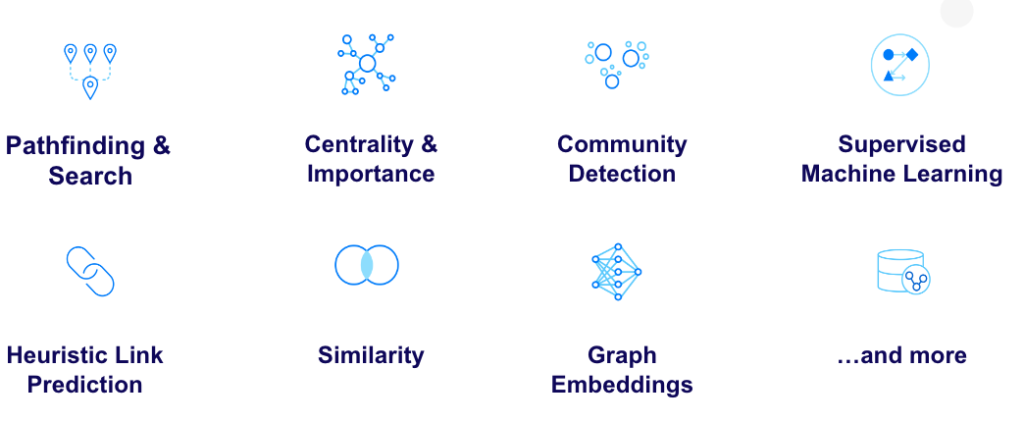
図5 - 65種類を超えるプリチューニングされた並列化アルゴリズム
3.1.3. 混沌から構造へ
Neo4j Graph Data Scienceは、文字通り、機械学習のあり方を変えるものです。
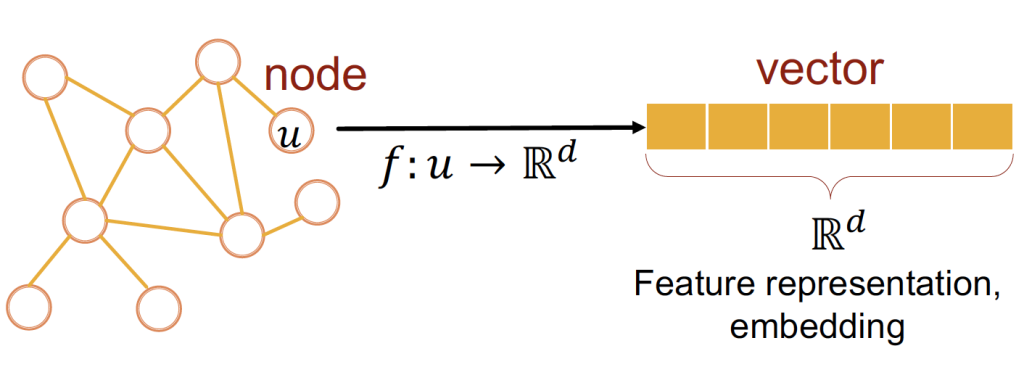
図6 - ノードエンベディングは任意のノードをベクトルに取り込める
グラフエンベディングは、グラフの拡張された明示的な知識を要約すると同時に、次元の削減を保証します。エンベディングベクトルは、ネットワークのトポロジーを吸収するため、機械学習パイプラインに加えられると、非常に予測性の高い特徴量となります。それでは、CORAデータセットについて簡単に説明したあと、実践的なパートに移りましょう。
4. CORAデータセット
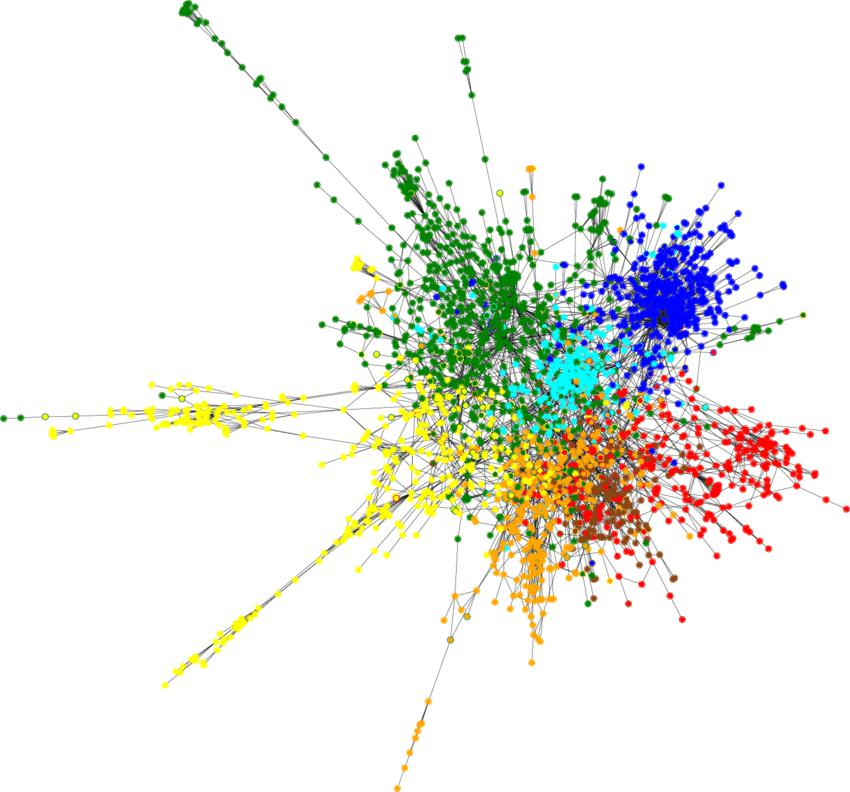
図7 - CORA引用グラフ Source
CORAデータセットは、「グラフランドのMNIST」(グラフデータの分野でのMNISTに相当するデータセット)と呼ばれています。7つのクラス(「理論」「強化学習」「確率的手法」など)に分類された2708編の学術論文(Paperノード)から構成されています。
論文同士を結ぶエッジは5429本(CITES(引用)リレーションシップ)です。
プロパティについては、論文テキストから抽出された1ノードあたりサイズ1433のfeaturesベクトルが存在します。
5. Pythonノートブックで試してみましょう
githubからPythonノートブックを開き、コマンドに従うだけです。githubからGoogle Driveにインポートすることもできますし、githubのプロジェクトをクローンするだけでもOKです。コメントへの回答やプルリクエストの管理など、できる限り対応します。
データ処理と機械学習のすべてを、単独のノートブックから実行することができます。必要なものは2つだけです。
- グラフデータサイエンスプラグインが動作しているNeo4jインスタンス
- Colabノートブック
5.1. Aura DSインスタンスを生成する
これは最初のステップです。Neo4jのインスタンスがなければ、魔法はかかりません。Neo4j AuraDSを使用して、Neo4j Graph Data Scienceプラグインを搭載したセルフマネージメントのNeo4jインスタンスを作成することをお勧めします(注意:Aura DSは有料です)。Neo4j Sandboxを使用してグラフデータサイエンスを行うこともできます。手を休めたくなったら、インスタンスを一時停止または停止することができます。
図8 - Neo4j Auraのコンソールでインスタンスを選択
インスタンスを生成すると、Neo4j AuraDSインスタンスに接続するための認証情報を含む.envファイルをダウンロードするよう促されます。
その.envファイルをColabノートブックに関連付けられたGoogle Driveのルートフォルダにアップロードしてください。
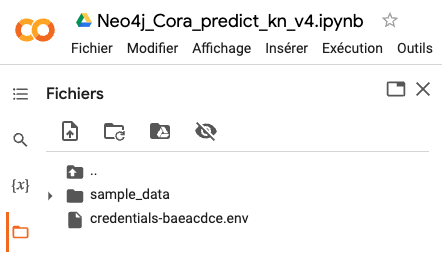
図9 - AuraDS の認証情報を含む.envファイルをアップロード
5.2. グラフデータサイエンスPythonクライアントのインストール
Neo4jグラフデータサイエンスPythonクライアントは、!pip installコマンドでノートブックにインストールします。
図10 - graphdatascience Python クライアントをインストール
5.3. データベース認証の保護
次のステップは、Neo4j データベースに接続するための認証情報を確保することです。
python-dotenvパッケージをインストールする必要があります。
!pip install python-dotenv
次に、このコードを実行します。
from dotenv import load_dotenv
import os
load_dotenv("/content/credentials-xxxxxx.env")
bolt = os.getenv("NEO4J_URI")
user = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
このノートブックの残りの部分では、これらの変数を明示的に表示することなく操作することができるようになりました。
5.4. グラフデータサイエンスPythonクライアントのインスタンス化
それでは、新しいgraphdatascienceクライアントを取得してみましょう。
import pandas as pd from IPython.display import display from graphdatascience import GraphDataScience gds = GraphDataScience(bolt, auth=auth, aura_ds=True)
gdsクライアントのバージョンを表示することができます。
print(gds.version()) 2.1.9
5.5. CORAデータセットの読み込み
CORAデータセットをNeo4jグラフデータベースにロードする時が来ました。2つのCypherコマンド、1つはPaperノード、もう1つはCITESリレーションシップを読み込むために使用します。これらのCypherコマンドは、Pythonクライアントのrun_cypherメソッドで実行されます。
node_load_q = """LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/node_list.csv" AS row
WITH toInteger(row.id) AS paperId, row.subject AS subject, row.features AS features
MERGE (p:Paper {paper_Id: paperId})
SET p.subject = subject, p.features = apoc.convert.fromJsonList(features)
RETURN count(p)
"""
edge_load_q = """
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/edge_list.csv" AS row
MATCH(source: Paper {paper_Id: toInteger(row.source)})
MATCH(target: Paper {paper_Id: toInteger(row.target)})
MERGE (source)-[r:CITES]->(target)
"""
gds.run_cypher(node_load_q)
gds.run_cypher(edge_load_q)
それでは、BloomでCORAグラフを可視化してみましょう(AuraDSコンソールまたはサンドボックスからBloomにアクセスしてください。)
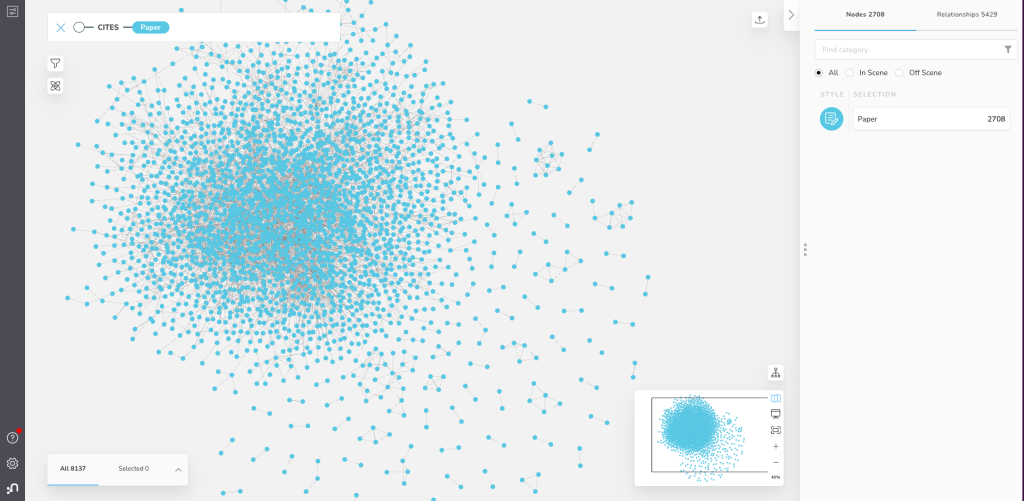
図11 - CORAグラフをNeo4j Bloomで可視化
5.6. featuresプロパティを見てみましょう
CORAデータセットに含まれる各論文の特徴を示すfeaturesは、各Paperノードのノードプロパティとして保存されています。
q_peak = """MATCH (n) WHERE EXISTS(n.features) RETURN DISTINCT n.paper_Id as PaperId, n.subject AS Paper_Subject, n.features AS features LIMIT 5""" res = gds.run_cypher(q_peak) df = pd.DataFrame.from_dict(res) display(df.head(5))
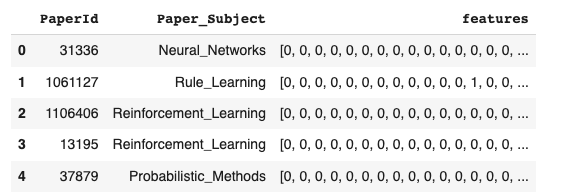
図12 - CORA論文ID、主題、features
featuresプロパティは、0と1の値を含むサイズ1433の配列(ベクトル)です。
Paper subjectは文字列プロパティです。これをIntegerにリファクタリングしたいと思います。
query_Subj = """MATCH (p:Paper) WITH collect(DISTINCT p.subject) as listSubjects WITH listSubjects, size(listSubjects) AS sizeListSubjects WITH listSubjects, range(1, sizeListSubjects) AS rangeSubjects WITH apoc.map.fromLists(listSubjects, rangeSubjects) AS mapSubjects MATCH (p:Paper) SET p.subjectClass = mapSubjects[p.subject];""" gds.run_cypher(query_Subj)
5.7. GDSエンジンを始動しましょう
CORAグラフをメモリ上に投影し、PaperノードとCITESリレーションシップからエンベディングの計算を行いたいと考えています。
G, res = gds.graph.project(
"cora-graph",
{"Paper": {"properties": ["subjectClass", "features"]} },
{"CITES": {"orientation": "UNDIRECTED", "aggregation": "SINGLE"}}
)
インメモリグラフの情報を少しみてみましょう。
print(G.name()) # cora-graph print(G.memory_usage()) # 30 MiB print(G.density()) # 0.0014399999126942077
5.8. FastRPの時間です!
各Paperノードのノードエンベディングを計算するために、FastRPアルゴリズム(FastRPはFast Random Projectionの略)を使用します。このアルゴリズムにより、各ノードはノード間のペアワイズ距離を保持したまま、次元を下げたベクトルに射影されます。
ここで少し説明します。
- 2708個のPaperノードがあります。
- 各ノードのエンベディングを計算します。
- エンベディングの次元は2708個から任意の数(ここでは128個)に削減されます。
やってみましょう。
fastrp_res = gds.fastRP.mutate( G, # Graph object featureProperties=["features"], # Configuration parameters embeddingDimension=128, iterationWeights=[0, 0, 1.0, 1.0], normalizationStrength=0.05, mutateProperty="fastRP_Extended_Embedding" ) assert fastrp_res["nodePropertiesWritten"] == G.node_count() print(fastrp_res)

図13 - FastRPによってそれぞれのPaperノードのエンベディングが計算される
fastRPアルゴリズムはmutateモードで使用しており、プロパティはディスク上ではなく、メモリ上に保存されています。
5.9. エンベディングの概要を見てみましょう
これで、128次元のベクトルであるエンベディングができました。
それらがどの程度近接しているかを可視化したいと思います。TSNEは、128次元のベクトルを2〜3次元に縮小し、視覚的に表示する手法の1つです。
from sklearn.manifold import TSNE
from numpy import reshape
import seaborn as sns
import pandas as pd
embedding_df = gds.graph.streamNodeProperty(G, 'fastRP_Extended_Embedding')
subject_df = gds.graph.streamNodeProperty(G, 'subjectClass')
# regroup in a single dataframe embedding and subjectClass
df = pd.DataFrame({'x':embedding_df["propertyValue"], 'y':subject_df["propertyValue"]})
X_embedded = TSNE(n_components=2, random_state=6).fit_transform(list(df.x))
subjects = df.y
tsne_df = pd.DataFrame(data = {
"subject": subjects,
"x": 本ブログは、「Neo4j」社の技術ブログで2022年9月23日に公開された「<a href="https://neo4j.com/blog/machine-learning-innovation-predictive-analysis/" target="_target" rel="noopener">A Machine Learning Innovation in Predictive Analytics</a>」の日本語翻訳です。
<hr />
<img class="aligncenter size-full wp-image-56081" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/MC_Blog_-Machine-learning.png" alt="" width="800" height="418" />
<b>グラフデータサイエンスを使用することによって機械学習の予測精度が改善するという人たちがいます。</b>
この考えは美しく、確かにグラフは強力なツールです。我々はつながりを持つデータが予測精度を大幅に向上させるという仮説を、大理石のように堅固に証明し、その効力を測定したいと思っています。
データサイエンスのエコシステムにおいてはよく知られている<a href="https://relational.fit.cvut.cz/dataset/CORA" target="_target" rel="noopener">科学論文のCORAデータセット</a>でやってみましょう。Neo4jとこれから説明するグラフエンベディングを使用すると、与えられた研究論文の論文カテゴリを予測するタスクにおいて、数点の精度の改善が得られます。
<h3>イントロダクション</h3>
このブログの構成は次の通りです。はじめに、グラフテクノロジおよびNeo4jグラフプラットフォームの紹介を行います。次に、Neo4jグラフデータサイエンスについて詳しく掘り下げます。そして、Neo4j GDSを活用したデモを行います。すでにNeo4jのエコシステムについてよく理解しているなら、<a href="#001">Neo4j GDSを活用したデモセクション</a>に直接進んでも構いません。最後に、このブログ記事の重要なポイントをまとめます。
<h2>1. グラフテクノロジ</h2>
グラフテクノロジは、データの関連性をより直感的でつながりのある状態に統一し、より深い文脈を解き明かします。
[caption id="attachment_56083" align="aligncenter" width="518"]<img class="size-full wp-image-56083" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/the-graph-tech.png" alt="" width="518" height="277" /> 図1 -(人間やトランザクションなどの)グラフはデータをノードとリレーションシップとして結び付けます[/caption]
データがグラフとして格納されると、それがどのようにつながっているかを理解するようになります。グラフテクノロジ以外では、2つのノード間のリンクが、何ホップも離れているため見えないこともあります。グラフデータベースは、<b>つながりのあるデータ全体の深い経路をたどることを可能にする</b>のです。グラフを通じて、信じられないような洞察が明らかになります。
Neo4jは<a href="https://db-engines.com/en/ranking_categories" target="_target" rel="noopener">グラフデータベースというカテゴリを創り出し、業界をリードしています</a>。グラフデータベースは全てのデータマネジメントカテゴリの中で最も速く成長しているカテゴリです。Neo4jは800社以上の顧客を持っており、そのうち300社以上がグローバル企業です。
<h2>2. Neo4jグラフプラットフォーム</h2>
[caption id="attachment_56085" align="aligncenter" width="1024"]<img class="size-large wp-image-56085" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/neo4j-graph-platform-2-1024x510.png" alt="" width="1024" height="510" /> 図2 - Neo4jグラフプラットフォーム[/caption]
Neo4jグラフプラットフォームを簡潔に説明すると、下記のようになります。
<ul>
<li><b>Neo4j Graph Database</b>は、データだけでなくデータのリレーションシップも活用できるよう、ゼロから構築されたネイティブなグラフデータストアです。他のタイプのデータベースと異なり、Neo4jはデータのつながりをそのままの形で保存するため、これまで想像もしなかったようなクエリを、これまで想像もしなかったようなスピードで実行することができます。</li>
<li><b>Neo4j Graph Data Science</b>は、データサイエンティストがビッグデータのつながりを明らかにし、ビジネス上の重要な問題に答え、予測精度を向上させることを支援するソフトウェアプラットフォームです。</li>
<li><b>Neo4j Bloomは、Neo4j</b>のグラフを視覚的に操作するための、使いやすいグラフ探索アプリケーションです。Bloomは、グラフの初心者から専門家まで、さまざまなビジネスの観点からグラフデータを視覚的に調査・探索する能力を提供します。</li>
<li><b>Cypherクエリ言語</b>: Neo4jではデータ間の接続は保存され、クエリ実行時に計算されることはありません。Cypherは、グラフに最適化された強力なクエリ言語であり、保存されたデータ間接続を理解し、活用することができます。</li>
<li>Neo4jはそれぞれのアーキテクチャでNeo4jを簡単に使用するためのいくつかの<a href="https://neo4j.com/developer/integration/?ref=product" target="_target" rel="noopener">コネクタ</a>を提供し、一部のサードパーティー製ツールあるいはコミュニティ製ツールのインストラクションサポートを提供します。Neo4jは、Apache SparkやApache Kafkaをはじめ、さまざまなBIツールやデータサイエンススタジオと連携しています。Neo4jの公式ドライバはJava、JavaScript、python、.Net、Goをサポートし、<a href="https://neo4j.com/product/graphql-library/" target="_target" rel="noopener">GRANDstack</a>のベースラインアーキテクチャによりGraphQLのサポートも最高レベルです。</li>
<li><b>Neo4j developer tools</b>は、Neo4jによって提供された洗練されたツールで、グラフアプリケーションの開発を容易にするために設計されています。グラフプロジェクトを作成するためのNeo4j Desktop、グラフのクエリを実行するためのNeo4j Browser、データを素早くグラフに取り込むためのNeo4j Data Importerが含まれます。</li>
</ul>
Neo4j Graph Platformは、すぐに利用できるさまざまなクラウドデプロイメントオプションで実行することができます。今日では、Neo4jのカスタマーの50%以上がAWS、Azure、Google Cloud Platform (GCP)などのパブリッククラウド上でNeo4jを動作させています。もちろん、Neo4jはオンプレミス、プライベートクラウド、ハイブリッド環境でも動作します。
ここからは、<a href="https://neo4j.com/product/graph-data-science" target="_target" rel="noopener">Neo4j Graph Data Science</a>にフォーカスしていきます。
<h2>3. Neo4j Graph Data Science</h2>
「データがあっても、質問がなければ役に立たない...」詠み人知らず。
では、Neo4j Graph Data Scienceでは、どのようなデータの質問に答えることができるのでしょうか?
それらは、3段階にまとめることができます。
<ol>
<li>何が重要なのか?</li>
<li>何が異常なのか?</li>
<li>次はどうなる?</li>
</ol>
それぞれの質問に対し、Neo4j Graph Databaseは効果的な答えを提供します。
<ol>
<li>データの中で何が重要かを特定するためには、まずエンティティ同士をリレーションシップで接続し、<a href="https://neo4j.com/use-cases/knowledge-graph/" target="_target" rel="noopener">ナレッジグラフ</a>を構築する必要があります。そうすることによって、つながりのあるデータの中で探しているパターンを見つけることができるようになります(Cypherクエリとグラフパターンを使用します)。</li>
<li>外れ値やクラスタやトレンドを検出するために、65種類を超えるグラフアルゴリズムがNeo4j Graph Data Scienceライブラリで使用可能です。</li>
<li>未来の予測をするために、機械学習モデルにグラフの特徴を与え、予測精度を向上させます。Neo4j Graph Data Scienceライブラリには<a href="https://neo4j.com/docs/graph-data-science/current/machine-learning/node-property-prediction/nodeclassification-pipelines/node-classification/" target="_target" rel="noopener">ノード分類</a>、<a href="https://neo4j.com/docs/graph-data-science/current/machine-learning/node-property-prediction/noderegression-pipelines/node-regression/" target="_target" rel="noopener">ノード回帰</a>、<a href="https://neo4j.com/docs/graph-data-science/current/machine-learning/linkprediction-pipelines/link-prediction/" target="_target" rel="noopener">リンク予測</a>の3種類のパイプラインが含まれます。</li>
</ol>
[caption id="attachment_56088" align="aligncenter" width="1024"]<img class="size-large wp-image-56088" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/neo4j-gds-1024x502.png" alt="" width="1024" height="502" /> 図3 - グラフデータサイエンスの成熟度のはしごを登る![/caption]
ある意味、この3つのステップは、あなたのグラフデータサイエンスの成熟度だと考えることができます。3つの質問を解決しようとするユースケースを増やせば増やすほど、グラフデータサイエンスの成熟度のはしごを登ることになるのです。
<h3>3.1. なぜNeo4j Graph Data Scienceを使用するのか?</h3>
<h4>3.1.1. メリット</h4>
Neo4j Graph Data Scienceには4つのキーアドバンテージがあります。
<ul>
<li>簡単に使用できる: ローコードやノーコードのツール、インテグレーション(統合)やワークフロー。クラウド経由での迅速な導入、緊密な統合、ワークフロー要素の自動化も可能。</li>
<li>データサイエンティスト: 幅広いデータサイエンスアルゴリズム、Pythonなどの言語サポート、データソースとMLツールの両方への容易な接続性。</li>
<li>エンタープライズに対応: あらゆる規模のお客様のニーズに対応する性能、信頼性、アーキテクチャの完全性。</li>
<li>エコシステム: データシステム(データレイク、データウェアハウスなど)とGCP Vertex AI、AWS SageMaker、Azure Synapseなど他のテクノロジーの両方と簡単に相互接続可能。</li>
</ul>
[caption id="attachment_56090" align="aligncenter" width="1024"]<img class="size-large wp-image-56090" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/gds-benefits-1024x474.png" alt="" width="1024" height="474" /> 図4 - Neo4j Graph Data Scienceを使用することのメリット[/caption]
<h4>3.1.2. アルゴリズムと機械学習</h4>
Neo4j Graph Data Scienceライブラリで使用可能なアルゴリズムは6つの主要なカテゴリに分類されます。
<ul>
<li><a href="https://neo4j.com/docs/graph-data-science/current/algorithms/pathfinding/" target="_target" rel="noopener">経路探索</a></li>
<li><a href="https://neo4j.com/docs/graph-data-science/current/algorithms/centrality/" target="_target" rel="noopener">中心性解析</a></li>
<li><a href="https://neo4j.com/docs/graph-data-science/current/algorithms/community/" target="_target" rel="noopener">コミュニティ検知</a></li>
<li><a href="https://neo4j.com/docs/graph-data-science/current/algorithms/linkprediction/" target="_target" rel="noopener">ヒューリスティックリンク予測</a></li>
<li><a href="https://neo4j.com/docs/graph-data-science/current/algorithms/similarity/" target="_target" rel="noopener">類似性</a></li>
<li><a href="https://neo4j.com/docs/graph-data-science/current/machine-learning/node-embeddings/" target="_target" rel="noopener">グラフエンベディング</a></li>
</ul>
教師あり機械学習には、ノード回帰、ノード分類、リンク予測それぞれのパイプラインが含まれています。その他にも、多くの有用な<a href="https://neo4j.com/docs/graph-data-science/current/algorithms/auxiliary/" target="_target" rel="noopener">補助関数やプロシージャ</a>があります。最後に、<a href="https://neo4j.com/docs/graph-data-science/current/algorithms/pregel-api/" target="_target" rel="noopener">Pregel Java API</a>では、いくつかのインターフェースを実装することで、独自のアルゴリズムを構築することができます。
[caption id="attachment_56092" align="aligncenter" width="1024"]<img class="size-large wp-image-56092" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/algorithms-1024x422.png" alt="" width="1024" height="422" /> 図5 - 65種類を超えるプリチューニングされた並列化アルゴリズム[/caption]
<h4>3.1.3. 混沌から構造へ</h4>
Neo4j Graph Data Scienceは、文字通り、機械学習のあり方を変えるものです。
[caption id="attachment_56096" align="aligncenter" width="1024"]<img class="size-large wp-image-56096" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/chaos-structure-1024x367.png" alt="" width="1024" height="367" /> 図6 - ノードエンベディングは任意のノードをベクトルに取り込める[/caption]
グラフエンベディングは、グラフの拡張された明示的な知識を要約すると同時に、次元の削減を保証します。エンベディングベクトルは、ネットワークのトポロジーを吸収するため、機械学習パイプラインに加えられると、非常に予測性の高い特徴量となります。それでは、CORAデータセットについて簡単に説明したあと、実践的なパートに移りましょう。
<h2>4. CORAデータセット</h2>
[caption id="attachment_56099" align="aligncenter" width="850"]<img class="size-full wp-image-56099" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/cora-dataset.png" alt="" width="850" height="792" /> 図7 - CORA引用グラフ <a href="https://paperswithcode.com/dataset/cora" target="_target" rel="noopener">Source</a>[/caption]
<a id="001"></a>
CORAデータセットは、「グラフランドのMNIST」(グラフデータの分野での<a href="https://ja.wikipedia.org/wiki/MNIST%E3%83%87%E3%83%BC%E3%82%BF%E3%83%99%E3%83%BC%E3%82%B9" target="_target" rel="noopener">MNIST</a>に相当するデータセット)と呼ばれています。7つのクラス(「理論」「強化学習」「確率的手法」など)に分類された2708編の学術論文(Paperノード)から構成されています。
論文同士を結ぶエッジは5429本(CITES(引用)リレーションシップ)です。
プロパティについては、論文テキストから抽出された1ノードあたりサイズ1433のfeaturesベクトルが存在します。
<h2>5. Pythonノートブックで試してみましょう</h2>
<a href="https://github.com/nrouyer/cora-graphdatascience" target="_target" rel="noopener">github</a>からPythonノートブックを開き、コマンドに従うだけです。githubからGoogle Driveにインポートすることもできますし、githubのプロジェクトをクローンするだけでもOKです。コメントへの回答やプルリクエストの管理など、できる限り対応します。
データ処理と機械学習のすべてを、単独のノートブックから実行することができます。必要なものは2つだけです。
<ul>
<li>グラフデータサイエンスプラグインが動作しているNeo4jインスタンス</li>
<li>Colabノートブック</li>
</ul>
<h3>5.1. Aura DSインスタンスを生成する</h3>
これは最初のステップです。Neo4jのインスタンスがなければ、魔法はかかりません。<a href="https://neo4j.com/cloud/platform/aura-graph-data-science/" target="_target" rel="noopener">Neo4j AuraDS</a>を使用して、Neo4j Graph Data Scienceプラグインを搭載したセルフマネージメントのNeo4jインスタンスを作成することをお勧めします(注意:Aura DSは有料です)。<a href="https://sandbox.neo4j.com/?_ga=2.225888538.1822386521.1666745609-600699322.1654058459&_gl=1*1mgq1u5*_ga*NjAwNjk5MzIyLjE2NTQwNTg0NTk.*_ga_DL38Q8KGQC*MTY1OTQyMDY3NC4xNzMuMS4xNjU5NDIwNjc0LjA." target="_target" rel="noopener">Neo4j Sandbox</a>を使用してグラフデータサイエンスを行うこともできます。手を休めたくなったら、インスタンスを一時停止または停止することができます。
[caption id="attachment_56101" align="aligncenter" width="600"]<img class="size-full wp-image-56101" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/aurads-instance.gif" alt="" width="600" height="400" /> 図8 - Neo4j Auraのコンソールでインスタンスを選択[/caption]
インスタンスを生成すると、Neo4j AuraDSインスタンスに接続するための認証情報を含む.envファイルをダウンロードするよう促されます。
その.envファイルをColabノートブックに関連付けられたGoogle Driveのルートフォルダにアップロードしてください。
[caption id="attachment_56103" align="aligncenter" width="442"]<img class="size-full wp-image-56103" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/upload-env-g-drive.png" alt="" width="442" height="266" /> 図9 - AuraDS の認証情報を含む.envファイルをアップロード[/caption]
<h3>5.2. グラフデータサイエンスPythonクライアントのインストール</h3>
<a href="https://neo4j.com/docs/graph-data-science-client/current/" target="_target" rel="noopener">Neo4jグラフデータサイエンスPythonクライアント</a>は、!pip installコマンドでノートブックにインストールします。
[caption id="attachment_56106" align="aligncenter" width="1024"]<img class="size-large wp-image-56106" src="/tech-blog/cms_x3GWkuX/uploads/2022/11/gds-python-client-1024x346.png" alt="" width="1024" height="346" /> 図10 - graphdatascience Python クライアントをインストール[/caption]
<h3>5.3. データベース認証の保護</h3>
次のステップは、Neo4j データベースに接続するための認証情報を確保することです。
python-dotenvパッケージをインストールする必要があります。
[cc lang='python']
!pip install python-dotenv
次に、このコードを実行します。
from dotenv import load_dotenv
import os
load_dotenv("/content/credentials-xxxxxx.env")
bolt = os.getenv("NEO4J_URI")
user = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
このノートブックの残りの部分では、これらの変数を明示的に表示することなく操作することができるようになりました。
5.4. グラフデータサイエンスPythonクライアントのインスタンス化
それでは、新しいgraphdatascienceクライアントを取得してみましょう。
import pandas as pd from IPython.display import display from graphdatascience import GraphDataScience gds = GraphDataScience(bolt, auth=auth, aura_ds=True)
gdsクライアントのバージョンを表示することができます。
print(gds.version()) 2.1.9
5.5. CORAデータセットの読み込み
CORAデータセットをNeo4jグラフデータベースにロードする時が来ました。2つのCypherコマンド、1つはPaperノード、もう1つはCITESリレーションシップを読み込むために使用します。これらのCypherコマンドは、Pythonクライアントのrun_cypherメソッドで実行されます。
node_load_q = """LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/node_list.csv" AS row
WITH toInteger(row.id) AS paperId, row.subject AS subject, row.features AS features
MERGE (p:Paper {paper_Id: paperId})
SET p.subject = subject, p.features = apoc.convert.fromJsonList(features)
RETURN count(p)
"""
edge_load_q = """
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/edge_list.csv" AS row
MATCH(source: Paper {paper_Id: toInteger(row.source)})
MATCH(target: Paper {paper_Id: toInteger(row.target)})
MERGE (source)-[r:CITES]->(target)
"""
gds.run_cypher(node_load_q)
gds.run_cypher(edge_load_q)
それでは、BloomでCORAグラフを可視化してみましょう(AuraDSコンソールまたはサンドボックスからBloomにアクセスしてください。)

図11 - CORAグラフをNeo4j Bloomで可視化
5.6. featuresプロパティを見てみましょう
CORAデータセットに含まれる各論文の特徴を示すfeaturesは、各Paperノードのノードプロパティとして保存されています。
q_peak = """MATCH (n) WHERE EXISTS(n.features) RETURN DISTINCT n.paper_Id as PaperId, n.subject AS Paper_Subject, n.features AS features LIMIT 5""" res = gds.run_cypher(q_peak) df = pd.DataFrame.from_dict(res) display(df.head(5))

図12 - CORA論文ID、主題、features
featuresプロパティは、0と1の値を含むサイズ1433の配列(ベクトル)です。
Paper subjectは文字列プロパティです。これをIntegerにリファクタリングしたいと思います。
query_Subj = """MATCH (p:Paper) WITH collect(DISTINCT p.subject) as listSubjects WITH listSubjects, size(listSubjects) AS sizeListSubjects WITH listSubjects, range(1, sizeListSubjects) AS rangeSubjects WITH apoc.map.fromLists(listSubjects, rangeSubjects) AS mapSubjects MATCH (p:Paper) SET p.subjectClass = mapSubjects[p.subject];""" gds.run_cypher(query_Subj)
5.7. GDSエンジンを始動しましょう
CORAグラフをメモリ上に投影し、PaperノードとCITESリレーションシップからエンベディングの計算を行いたいと考えています。
G, res = gds.graph.project(
"cora-graph",
{"Paper": {"properties": ["subjectClass", "features"]} },
{"CITES": {"orientation": "UNDIRECTED", "aggregation": "SINGLE"}}
)
インメモリグラフの情報を少しみてみましょう。
print(G.name()) # cora-graph print(G.memory_usage()) # 30 MiB print(G.density()) # 0.0014399999126942077
5.8. FastRPの時間です!
各Paperノードのノードエンベディングを計算するために、FastRPアルゴリズム(FastRPはFast Random Projectionの略)を使用します。このアルゴリズムにより、各ノードはノード間のペアワイズ距離を保持したまま、次元を下げたベクトルに射影されます。
ここで少し説明します。
- 2708個のPaperノードがあります。
- 各ノードのエンベディングを計算します。
- エンベディングの次元は2708個から任意の数(ここでは128個)に削減されます。
やってみましょう。
fastrp_res = gds.fastRP.mutate( G, # Graph object featureProperties=["features"], # Configuration parameters embeddingDimension=128, iterationWeights=[0, 0, 1.0, 1.0], normalizationStrength=0.05, mutateProperty="fastRP_Extended_Embedding" ) assert fastrp_res["nodePropertiesWritten"] == G.node_count() print(fastrp_res)

図13 - FastRPによってそれぞれのPaperノードのエンベディングが計算される
fastRPアルゴリズムはmutateモードで使用しており、プロパティはディスク上ではなく、メモリ上に保存されています。
5.9. エンベディングの概要を見てみましょう
これで、128次元のベクトルであるエンベディングができました。
それらがどの程度近接しているかを可視化したいと思います。TSNEは、128次元のベクトルを2〜3次元に縮小し、視覚的に表示する手法の1つです。
from sklearn.manifold import TSNE
from numpy import reshape
import seaborn as sns
import pandas as pd
embedding_df = gds.graph.streamNodeProperty(G, 'fastRP_Extended_Embedding')
subject_df = gds.graph.streamNodeProperty(G, 'subjectClass')
# regroup in a single dataframe embedding and subjectClass
df = pd.DataFrame({'x':embedding_df["propertyValue"], 'y':subject_df["propertyValue"]})
X_embedded = TSNE(n_components=2, random_state=6).fit_transform(list(df.x))
subjects = df.y
tsne_df = pd.DataFrame(data = {
"subject": subjects,
"x": [value[0] for value in X_embedded],
"y": [value[1] for value in X_embedded]
})
tsne_df.head()

図14 - TSNEエンベディングによって2次元まで次元削減された
altair Pythonパッケージをインストールします。
!pip install altair
TSNEで次元削減したエンベディングを可視化してみます。
import altair as alt alt.Chart(tsne_df).mark_circle(size=60).encode( x='x', y='y', color='subject', tooltip=['subject'] ).properties(width=700, height=400)

図15 - TSNEを用いてノードエンベディングを可視化
同じテーマの論文のノードはそれほど離れていないようです。このT-SNEによる洞察を確認してみましょう。
5.10. 予測してみましょう!
グラフの20%をテストグラフとして予測を行い、未知のデータに対するモデルの精度を確認します。
まず、featuresプロパティのみを用いて学習とテストを行います。次に、featuresとエンベディングを用いて予測を行います。
5.10.1 featuresを用いたノードの分類
新しいパイプラインを作成し、設定パラメータを少し変更します。
pipe, _ = gds.beta.pipeline.nodeClassification.create("cora-pipe")
pipe.configureSplit(testFraction=0.2, validationFolds=5)
さて、特徴量を選択します。(注意:featuresプロパティはメソッドと同じ名前になっています。)
pipe.selectFeatures(['features'])

図16 - featuresをパイプラインに追加
そして、パイプにいくつかの機械学習モデルを選択します。
pipe.addLogisticRegression(tolerance=0.001, maxEpochs=100, penalty=0.0, batchSize=32) pipe.addRandomForest(maxDepth=(20))

図17 - MLモデルを選択
学習を行いましょう。ここで重要なのは、Paperの対象クラスであるtargetPropertyを指定している点です。targetPropertyは、パイプラインで予測したいプロパティで、既存の特徴量を指定します。
trained_pipe_model, res = pipe.train(G, modelName="cora-features-model", targetProperty="subjectClass", metrics=["ACCURACY", "F1_WEIGHTED"]) assert res["trainMillis"] >= 0
図18 - ノード分類学習の実行
選択されたMLモデルについて、学習段階におけるメトリクスを表示することができます。
trained_pipe_model.metrics()

図19 - パイプライン学習時のモデルのメトリクス
学習が終わったら、予測を行ってみましょう。
result = trained_pipe_model.predict_write(G, concurrency=8, writeProperty="featuresPredictedClass", predictedProbabilityProperty="featuresPredictedProbability")
具体的にはどのようなことが行われたのでしょうか?各ノードに2つの新しいプロパティが書き込まれました。

図20 - パイプライン予測時のメトリクス
最後に、このモデルの精度をチェックします。これは、予測されたプロパティと実際のsubjectClassプロパティを比較することで行われます。
query_check = """MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL WITH count(p) AS nbPapers MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL AND p.featuresPredictedClass = p.subjectClass RETURN toFloat(count(p)) / nbPapers AS ratio""" q_check = gds.run_cypher(query_check) df_q_check = pd.DataFrame.from_dict(q_check) # print(q_check) display(df_q_check)

図21 - 最初のモデル(featuresで学習)の精度
5.10.2 featuresとエンベディングを用いたノードの分類
では、これまでの手順をすべて再現してみましょう。異なるのは特徴量の選択だけです。
pipe_embedding.selectFeatures(['features', 'fastRP_Extended_Embedding'])
次に、エンベディングプロパティを追加し、学習とテストのフェーズを実行します。
trained_pipe_embedding_model.metrics()
エンベディングを考慮することで、テストメトリクスが格段に向上することが分かります。

図22 - 新しいパイプラインの学習時のメトリクス
新しい予測モデルの精度は、89%になりました。

図23 - 予測精度の比較
全くチューニングをせずに、+7%の精度を実現しました。
Bloomでは、100個のPaperノードを表示し、ルールベースのポリシーを適用して、精度の高い予測対象を紺色で表示することができます。

図24 - Bloomルールベースのポリシーによる予測結果の区別
主題の予測に失敗したPaperノードの数は簡単に数えることができます。11/100です。
=> 89%の精度が得られています。
6. まとめ
Neo4jとグラフデータサイエンスは、より良い予測結果をもたらします。エンベディングアルゴリズムは、高度な予測機能を生み出し、MLモデルをより正確にします。

図25 - GDSは(1)シンプルであり、(2)データサイエンティストや(3)産業に、(4)より良い予測をもたらす統合ツールです(イメージソースはpexelsから取得)
そして今、ボールはあなたのコートにあるのです。
あなたのデータをグラフとして見ることで、より良い予測パフォーマンスを得ることができるとしたらどうしますか?
データをつなげるのに数秒、価値ある洞察に変換するのに数分かかり、重要な質問に答えることができます。
- 何が重要なのか?
- 何が異常なのか?
- 次はどうなる?
リソース
- CORA Graph Data Science notebook (GitHub)
- Neo4j Graph Data Science Library manual
- このブログは次の環境で実行・テストされています: Neo4j 4.4.x, Neo4j Graph Data Science python client 2.1.9 for value in X_embedded],
"y": 本ブログは、「Neo4j」社の技術ブログで2022年9月23日に公開された「A Machine Learning Innovation in Predictive Analytics」の日本語翻訳です。

グラフデータサイエンスを使用することによって機械学習の予測精度が改善するという人たちがいます。
この考えは美しく、確かにグラフは強力なツールです。我々はつながりを持つデータが予測精度を大幅に向上させるという仮説を、大理石のように堅固に証明し、その効力を測定したいと思っています。
データサイエンスのエコシステムにおいてはよく知られている科学論文のCORAデータセットでやってみましょう。Neo4jとこれから説明するグラフエンベディングを使用すると、与えられた研究論文の論文カテゴリを予測するタスクにおいて、数点の精度の改善が得られます。
イントロダクション
このブログの構成は次の通りです。はじめに、グラフテクノロジおよびNeo4jグラフプラットフォームの紹介を行います。次に、Neo4jグラフデータサイエンスについて詳しく掘り下げます。そして、Neo4j GDSを活用したデモを行います。すでにNeo4jのエコシステムについてよく理解しているなら、Neo4j GDSを活用したデモセクションに直接進んでも構いません。最後に、このブログ記事の重要なポイントをまとめます。
1. グラフテクノロジ
グラフテクノロジは、データの関連性をより直感的でつながりのある状態に統一し、より深い文脈を解き明かします。

図1 -(人間やトランザクションなどの)グラフはデータをノードとリレーションシップとして結び付けます
データがグラフとして格納されると、それがどのようにつながっているかを理解するようになります。グラフテクノロジ以外では、2つのノード間のリンクが、何ホップも離れているため見えないこともあります。グラフデータベースは、つながりのあるデータ全体の深い経路をたどることを可能にするのです。グラフを通じて、信じられないような洞察が明らかになります。
Neo4jはグラフデータベースというカテゴリを創り出し、業界をリードしています。グラフデータベースは全てのデータマネジメントカテゴリの中で最も速く成長しているカテゴリです。Neo4jは800社以上の顧客を持っており、そのうち300社以上がグローバル企業です。
2. Neo4jグラフプラットフォーム

図2 - Neo4jグラフプラットフォーム
Neo4jグラフプラットフォームを簡潔に説明すると、下記のようになります。
- Neo4j Graph Databaseは、データだけでなくデータのリレーションシップも活用できるよう、ゼロから構築されたネイティブなグラフデータストアです。他のタイプのデータベースと異なり、Neo4jはデータのつながりをそのままの形で保存するため、これまで想像もしなかったようなクエリを、これまで想像もしなかったようなスピードで実行することができます。
- Neo4j Graph Data Scienceは、データサイエンティストがビッグデータのつながりを明らかにし、ビジネス上の重要な問題に答え、予測精度を向上させることを支援するソフトウェアプラットフォームです。
- Neo4j Bloomは、Neo4jのグラフを視覚的に操作するための、使いやすいグラフ探索アプリケーションです。Bloomは、グラフの初心者から専門家まで、さまざまなビジネスの観点からグラフデータを視覚的に調査・探索する能力を提供します。
- Cypherクエリ言語: Neo4jではデータ間の接続は保存され、クエリ実行時に計算されることはありません。Cypherは、グラフに最適化された強力なクエリ言語であり、保存されたデータ間接続を理解し、活用することができます。
- Neo4jはそれぞれのアーキテクチャでNeo4jを簡単に使用するためのいくつかのコネクタを提供し、一部のサードパーティー製ツールあるいはコミュニティ製ツールのインストラクションサポートを提供します。Neo4jは、Apache SparkやApache Kafkaをはじめ、さまざまなBIツールやデータサイエンススタジオと連携しています。Neo4jの公式ドライバはJava、JavaScript、python、.Net、Goをサポートし、GRANDstackのベースラインアーキテクチャによりGraphQLのサポートも最高レベルです。
- Neo4j developer toolsは、Neo4jによって提供された洗練されたツールで、グラフアプリケーションの開発を容易にするために設計されています。グラフプロジェクトを作成するためのNeo4j Desktop、グラフのクエリを実行するためのNeo4j Browser、データを素早くグラフに取り込むためのNeo4j Data Importerが含まれます。
Neo4j Graph Platformは、すぐに利用できるさまざまなクラウドデプロイメントオプションで実行することができます。今日では、Neo4jのカスタマーの50%以上がAWS、Azure、Google Cloud Platform (GCP)などのパブリッククラウド上でNeo4jを動作させています。もちろん、Neo4jはオンプレミス、プライベートクラウド、ハイブリッド環境でも動作します。
ここからは、Neo4j Graph Data Scienceにフォーカスしていきます。
3. Neo4j Graph Data Science
「データがあっても、質問がなければ役に立たない...」詠み人知らず。
では、Neo4j Graph Data Scienceでは、どのようなデータの質問に答えることができるのでしょうか?
それらは、3段階にまとめることができます。- 何が重要なのか?
- 何が異常なのか?
- 次はどうなる?
それぞれの質問に対し、Neo4j Graph Databaseは効果的な答えを提供します。
- データの中で何が重要かを特定するためには、まずエンティティ同士をリレーションシップで接続し、ナレッジグラフを構築する必要があります。そうすることによって、つながりのあるデータの中で探しているパターンを見つけることができるようになります(Cypherクエリとグラフパターンを使用します)。
- 外れ値やクラスタやトレンドを検出するために、65種類を超えるグラフアルゴリズムがNeo4j Graph Data Scienceライブラリで使用可能です。
- 未来の予測をするために、機械学習モデルにグラフの特徴を与え、予測精度を向上させます。Neo4j Graph Data Scienceライブラリにはノード分類、ノード回帰、リンク予測の3種類のパイプラインが含まれます。

図3 - グラフデータサイエンスの成熟度のはしごを登る!
ある意味、この3つのステップは、あなたのグラフデータサイエンスの成熟度だと考えることができます。3つの質問を解決しようとするユースケースを増やせば増やすほど、グラフデータサイエンスの成熟度のはしごを登ることになるのです。
3.1. なぜNeo4j Graph Data Scienceを使用するのか?
3.1.1. メリット
Neo4j Graph Data Scienceには4つのキーアドバンテージがあります。
- 簡単に使用できる: ローコードやノーコードのツール、インテグレーション(統合)やワークフロー。クラウド経由での迅速な導入、緊密な統合、ワークフロー要素の自動化も可能。
- データサイエンティスト: 幅広いデータサイエンスアルゴリズム、Pythonなどの言語サポート、データソースとMLツールの両方への容易な接続性。
- エンタープライズに対応: あらゆる規模のお客様のニーズに対応する性能、信頼性、アーキテクチャの完全性。
- エコシステム: データシステム(データレイク、データウェアハウスなど)とGCP Vertex AI、AWS SageMaker、Azure Synapseなど他のテクノロジーの両方と簡単に相互接続可能。

図4 - Neo4j Graph Data Scienceを使用することのメリット
3.1.2. アルゴリズムと機械学習
Neo4j Graph Data Scienceライブラリで使用可能なアルゴリズムは6つの主要なカテゴリに分類されます。
教師あり機械学習には、ノード回帰、ノード分類、リンク予測それぞれのパイプラインが含まれています。その他にも、多くの有用な補助関数やプロシージャがあります。最後に、Pregel Java APIでは、いくつかのインターフェースを実装することで、独自のアルゴリズムを構築することができます。

図5 - 65種類を超えるプリチューニングされた並列化アルゴリズム
3.1.3. 混沌から構造へ
Neo4j Graph Data Scienceは、文字通り、機械学習のあり方を変えるものです。

図6 - ノードエンベディングは任意のノードをベクトルに取り込める
グラフエンベディングは、グラフの拡張された明示的な知識を要約すると同時に、次元の削減を保証します。エンベディングベクトルは、ネットワークのトポロジーを吸収するため、機械学習パイプラインに加えられると、非常に予測性の高い特徴量となります。それでは、CORAデータセットについて簡単に説明したあと、実践的なパートに移りましょう。
4. CORAデータセット

図7 - CORA引用グラフ Source
CORAデータセットは、「グラフランドのMNIST」(グラフデータの分野でのMNISTに相当するデータセット)と呼ばれています。7つのクラス(「理論」「強化学習」「確率的手法」など)に分類された2708編の学術論文(Paperノード)から構成されています。論文同士を結ぶエッジは5429本(CITES(引用)リレーションシップ)です。
プロパティについては、論文テキストから抽出された1ノードあたりサイズ1433のfeaturesベクトルが存在します。
5. Pythonノートブックで試してみましょう
githubからPythonノートブックを開き、コマンドに従うだけです。githubからGoogle Driveにインポートすることもできますし、githubのプロジェクトをクローンするだけでもOKです。コメントへの回答やプルリクエストの管理など、できる限り対応します。
データ処理と機械学習のすべてを、単独のノートブックから実行することができます。必要なものは2つだけです。
- グラフデータサイエンスプラグインが動作しているNeo4jインスタンス
- Colabノートブック
5.1. Aura DSインスタンスを生成する
これは最初のステップです。Neo4jのインスタンスがなければ、魔法はかかりません。Neo4j AuraDSを使用して、Neo4j Graph Data Scienceプラグインを搭載したセルフマネージメントのNeo4jインスタンスを作成することをお勧めします(注意:Aura DSは有料です)。Neo4j Sandboxを使用してグラフデータサイエンスを行うこともできます。手を休めたくなったら、インスタンスを一時停止または停止することができます。

図8 - Neo4j Auraのコンソールでインスタンスを選択
インスタンスを生成すると、Neo4j AuraDSインスタンスに接続するための認証情報を含む.envファイルをダウンロードするよう促されます。
その.envファイルをColabノートブックに関連付けられたGoogle Driveのルートフォルダにアップロードしてください。

図9 - AuraDS の認証情報を含む.envファイルをアップロード
5.2. グラフデータサイエンスPythonクライアントのインストール
Neo4jグラフデータサイエンスPythonクライアントは、!pip installコマンドでノートブックにインストールします。

図10 - graphdatascience Python クライアントをインストール
5.3. データベース認証の保護
次のステップは、Neo4j データベースに接続するための認証情報を確保することです。
python-dotenvパッケージをインストールする必要があります。
!pip install python-dotenv
次に、このコードを実行します。
from dotenv import load_dotenv import os load_dotenv("/content/credentials-xxxxxx.env") bolt = os.getenv("NEO4J_URI") user = os.getenv("NEO4J_USERNAME") password = os.getenv("NEO4J_PASSWORD")このノートブックの残りの部分では、これらの変数を明示的に表示することなく操作することができるようになりました。
5.4. グラフデータサイエンスPythonクライアントのインスタンス化
それでは、新しいgraphdatascienceクライアントを取得してみましょう。
import pandas as pd from IPython.display import display from graphdatascience import GraphDataScience gds = GraphDataScience(bolt, auth=auth, aura_ds=True)
gdsクライアントのバージョンを表示することができます。
print(gds.version()) 2.1.9
5.5. CORAデータセットの読み込み
CORAデータセットをNeo4jグラフデータベースにロードする時が来ました。2つのCypherコマンド、1つはPaperノード、もう1つはCITESリレーションシップを読み込むために使用します。これらのCypherコマンドは、Pythonクライアントのrun_cypherメソッドで実行されます。
node_load_q = """LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/node_list.csv" AS row WITH toInteger(row.id) AS paperId, row.subject AS subject, row.features AS features MERGE (p:Paper {paper_Id: paperId}) SET p.subject = subject, p.features = apoc.convert.fromJsonList(features) RETURN count(p) """ edge_load_q = """ LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/Kristof-Neys/Neo4j-Cora/main/edge_list.csv" AS row MATCH(source: Paper {paper_Id: toInteger(row.source)}) MATCH(target: Paper {paper_Id: toInteger(row.target)}) MERGE (source)-[r:CITES]->(target) """ gds.run_cypher(node_load_q) gds.run_cypher(edge_load_q)それでは、BloomでCORAグラフを可視化してみましょう(AuraDSコンソールまたはサンドボックスからBloomにアクセスしてください。)
図11 - CORAグラフをNeo4j Bloomで可視化
5.6. featuresプロパティを見てみましょう
CORAデータセットに含まれる各論文の特徴を示すfeaturesは、各Paperノードのノードプロパティとして保存されています。
q_peak = """MATCH (n) WHERE EXISTS(n.features) RETURN DISTINCT n.paper_Id as PaperId, n.subject AS Paper_Subject, n.features AS features LIMIT 5""" res = gds.run_cypher(q_peak) df = pd.DataFrame.from_dict(res) display(df.head(5))
図12 - CORA論文ID、主題、features
featuresプロパティは、0と1の値を含むサイズ1433の配列(ベクトル)です。
Paper subjectは文字列プロパティです。これをIntegerにリファクタリングしたいと思います。
query_Subj = """MATCH (p:Paper) WITH collect(DISTINCT p.subject) as listSubjects WITH listSubjects, size(listSubjects) AS sizeListSubjects WITH listSubjects, range(1, sizeListSubjects) AS rangeSubjects WITH apoc.map.fromLists(listSubjects, rangeSubjects) AS mapSubjects MATCH (p:Paper) SET p.subjectClass = mapSubjects[p.subject];""" gds.run_cypher(query_Subj)
5.7. GDSエンジンを始動しましょう
CORAグラフをメモリ上に投影し、PaperノードとCITESリレーションシップからエンベディングの計算を行いたいと考えています。
G, res = gds.graph.project( "cora-graph", {"Paper": {"properties": ["subjectClass", "features"]} }, {"CITES": {"orientation": "UNDIRECTED", "aggregation": "SINGLE"}} )インメモリグラフの情報を少しみてみましょう。
print(G.name()) # cora-graph print(G.memory_usage()) # 30 MiB print(G.density()) # 0.0014399999126942077
5.8. FastRPの時間です!
各Paperノードのノードエンベディングを計算するために、FastRPアルゴリズム(FastRPはFast Random Projectionの略)を使用します。このアルゴリズムにより、各ノードはノード間のペアワイズ距離を保持したまま、次元を下げたベクトルに射影されます。
ここで少し説明します。
- 2708個のPaperノードがあります。
- 各ノードのエンベディングを計算します。
- エンベディングの次元は2708個から任意の数(ここでは128個)に削減されます。
やってみましょう。
fastrp_res = gds.fastRP.mutate( G, # Graph object featureProperties=["features"], # Configuration parameters embeddingDimension=128, iterationWeights=[0, 0, 1.0, 1.0], normalizationStrength=0.05, mutateProperty="fastRP_Extended_Embedding" ) assert fastrp_res["nodePropertiesWritten"] == G.node_count() print(fastrp_res)
図13 - FastRPによってそれぞれのPaperノードのエンベディングが計算される
fastRPアルゴリズムはmutateモードで使用しており、プロパティはディスク上ではなく、メモリ上に保存されています。
5.9. エンベディングの概要を見てみましょう
これで、128次元のベクトルであるエンベディングができました。
それらがどの程度近接しているかを可視化したいと思います。TSNEは、128次元のベクトルを2〜3次元に縮小し、視覚的に表示する手法の1つです。
from sklearn.manifold import TSNE from numpy import reshape import seaborn as sns import pandas as pd embedding_df = gds.graph.streamNodeProperty(G, 'fastRP_Extended_Embedding') subject_df = gds.graph.streamNodeProperty(G, 'subjectClass') # regroup in a single dataframe embedding and subjectClass df = pd.DataFrame({'x':embedding_df["propertyValue"], 'y':subject_df["propertyValue"]}) X_embedded = TSNE(n_components=2, random_state=6).fit_transform(list(df.x)) subjects = df.y tsne_df = pd.DataFrame(data = { "subject": subjects, "x": [value[0] for value in X_embedded], "y": [value[1] for value in X_embedded] }) tsne_df.head()図14 - TSNEエンベディングによって2次元まで次元削減された
altair Pythonパッケージをインストールします。
!pip install altair
TSNEで次元削減したエンベディングを可視化してみます。
import altair as alt alt.Chart(tsne_df).mark_circle(size=60).encode( x='x', y='y', color='subject', tooltip=['subject'] ).properties(width=700, height=400)
図15 - TSNEを用いてノードエンベディングを可視化
同じテーマの論文のノードはそれほど離れていないようです。このT-SNEによる洞察を確認してみましょう。
5.10. 予測してみましょう!
グラフの20%をテストグラフとして予測を行い、未知のデータに対するモデルの精度を確認します。
まず、featuresプロパティのみを用いて学習とテストを行います。次に、featuresとエンベディングを用いて予測を行います。
5.10.1 featuresを用いたノードの分類
新しいパイプラインを作成し、設定パラメータを少し変更します。
pipe, _ = gds.beta.pipeline.nodeClassification.create("cora-pipe") pipe.configureSplit(testFraction=0.2, validationFolds=5)さて、特徴量を選択します。(注意:featuresプロパティはメソッドと同じ名前になっています。)
pipe.selectFeatures(['features'])
図16 - featuresをパイプラインに追加
そして、パイプにいくつかの機械学習モデルを選択します。
pipe.addLogisticRegression(tolerance=0.001, maxEpochs=100, penalty=0.0, batchSize=32) pipe.addRandomForest(maxDepth=(20))
図17 - MLモデルを選択
学習を行いましょう。ここで重要なのは、Paperの対象クラスであるtargetPropertyを指定している点です。targetPropertyは、パイプラインで予測したいプロパティで、既存の特徴量を指定します。
trained_pipe_model, res = pipe.train(G, modelName="cora-features-model", targetProperty="subjectClass", metrics=["ACCURACY", "F1_WEIGHTED"]) assert res["trainMillis"] >= 0

図18 - ノード分類学習の実行
選択されたMLモデルについて、学習段階におけるメトリクスを表示することができます。
trained_pipe_model.metrics()
図19 - パイプライン学習時のモデルのメトリクス
学習が終わったら、予測を行ってみましょう。
result = trained_pipe_model.predict_write(G, concurrency=8, writeProperty="featuresPredictedClass", predictedProbabilityProperty="featuresPredictedProbability")
具体的にはどのようなことが行われたのでしょうか?各ノードに2つの新しいプロパティが書き込まれました。
図20 - パイプライン予測時のメトリクス
最後に、このモデルの精度をチェックします。これは、予測されたプロパティと実際のsubjectClassプロパティを比較することで行われます。
query_check = """MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL WITH count(p) AS nbPapers MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL AND p.featuresPredictedClass = p.subjectClass RETURN toFloat(count(p)) / nbPapers AS ratio""" q_check = gds.run_cypher(query_check) df_q_check = pd.DataFrame.from_dict(q_check) # print(q_check) display(df_q_check)
図21 - 最初のモデル(featuresで学習)の精度
5.10.2 featuresとエンベディングを用いたノードの分類
では、これまでの手順をすべて再現してみましょう。異なるのは特徴量の選択だけです。
pipe_embedding.selectFeatures(['features', 'fastRP_Extended_Embedding'])
次に、エンベディングプロパティを追加し、学習とテストのフェーズを実行します。
trained_pipe_embedding_model.metrics()
エンベディングを考慮することで、テストメトリクスが格段に向上することが分かります。
図22 - 新しいパイプラインの学習時のメトリクス
新しい予測モデルの精度は、89%になりました。
図23 - 予測精度の比較
全くチューニングをせずに、+7%の精度を実現しました。
Bloomでは、100個のPaperノードを表示し、ルールベースのポリシーを適用して、精度の高い予測対象を紺色で表示することができます。
図24 - Bloomルールベースのポリシーによる予測結果の区別
主題の予測に失敗したPaperノードの数は簡単に数えることができます。11/100です。
=> 89%の精度が得られています。6. まとめ
Neo4jとグラフデータサイエンスは、より良い予測結果をもたらします。エンベディングアルゴリズムは、高度な予測機能を生み出し、MLモデルをより正確にします。
図25 - GDSは(1)シンプルであり、(2)データサイエンティストや(3)産業に、(4)より良い予測をもたらす統合ツールです(イメージソースはpexelsから取得)
そして今、ボールはあなたのコートにあるのです。
あなたのデータをグラフとして見ることで、より良い予測パフォーマンスを得ることができるとしたらどうしますか?
データをつなげるのに数秒、価値ある洞察に変換するのに数分かかり、重要な質問に答えることができます。
- 何が重要なのか?
- 何が異常なのか?
- 次はどうなる?
リソース
- CORA Graph Data Science notebook (GitHub)
- Neo4j Graph Data Science Library manual
- このブログは次の環境で実行・テストされています: Neo4j 4.4.x, Neo4j Graph Data Science python client 2.1.9 for value in X_embedded]
})
tsne_df.head()
[/cc]
図14 - TSNEエンベディングによって2次元まで次元削減された
altair Pythonパッケージをインストールします。
!pip install altair
TSNEで次元削減したエンベディングを可視化してみます。
import altair as alt alt.Chart(tsne_df).mark_circle(size=60).encode( x='x', y='y', color='subject', tooltip=['subject'] ).properties(width=700, height=400)
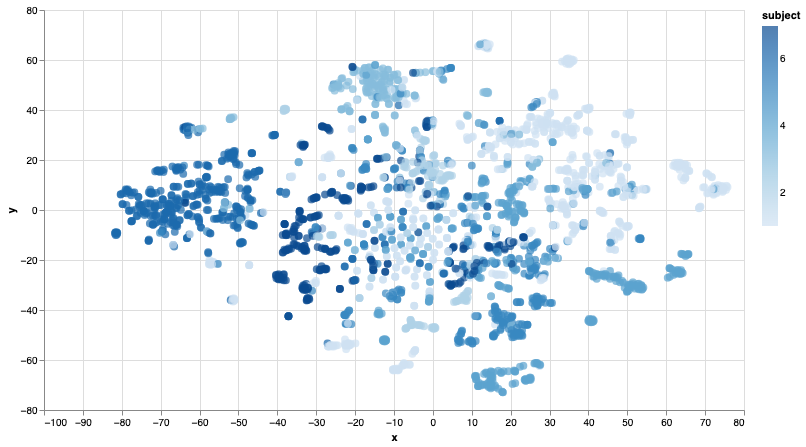
図15 - TSNEを用いてノードエンベディングを可視化
同じテーマの論文のノードはそれほど離れていないようです。このT-SNEによる洞察を確認してみましょう。
5.10. 予測してみましょう!
グラフの20%をテストグラフとして予測を行い、未知のデータに対するモデルの精度を確認します。
まず、featuresプロパティのみを用いて学習とテストを行います。次に、featuresとエンベディングを用いて予測を行います。
5.10.1 featuresを用いたノードの分類
新しいパイプラインを作成し、設定パラメータを少し変更します。
pipe, _ = gds.beta.pipeline.nodeClassification.create("cora-pipe") pipe.configureSplit(testFraction=0.2, validationFolds=5)さて、特徴量を選択します。(注意:featuresプロパティはメソッドと同じ名前になっています。)
pipe.selectFeatures(['features'])

図16 - featuresをパイプラインに追加
そして、パイプにいくつかの機械学習モデルを選択します。
pipe.addLogisticRegression(tolerance=0.001, maxEpochs=100, penalty=0.0, batchSize=32) pipe.addRandomForest(maxDepth=(20))

図17 - MLモデルを選択
学習を行いましょう。ここで重要なのは、Paperの対象クラスであるtargetPropertyを指定している点です。targetPropertyは、パイプラインで予測したいプロパティで、既存の特徴量を指定します。
trained_pipe_model, res = pipe.train(G, modelName="cora-features-model", targetProperty="subjectClass", metrics=["ACCURACY", "F1_WEIGHTED"]) assert res["trainMillis"] >= 0

図18 - ノード分類学習の実行
選択されたMLモデルについて、学習段階におけるメトリクスを表示することができます。
trained_pipe_model.metrics()

図19 - パイプライン学習時のモデルのメトリクス
学習が終わったら、予測を行ってみましょう。
result = trained_pipe_model.predict_write(G, concurrency=8, writeProperty="featuresPredictedClass", predictedProbabilityProperty="featuresPredictedProbability")
具体的にはどのようなことが行われたのでしょうか?各ノードに2つの新しいプロパティが書き込まれました。

図20 - パイプライン予測時のメトリクス
最後に、このモデルの精度をチェックします。これは、予測されたプロパティと実際のsubjectClassプロパティを比較することで行われます。
query_check = """MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL WITH count(p) AS nbPapers MATCH (p:Paper) WHERE p.featuresPredictedClass IS NOT NULL AND p.featuresPredictedClass = p.subjectClass RETURN toFloat(count(p)) / nbPapers AS ratio""" q_check = gds.run_cypher(query_check) df_q_check = pd.DataFrame.from_dict(q_check) # print(q_check) display(df_q_check)

図21 - 最初のモデル(featuresで学習)の精度
5.10.2 featuresとエンベディングを用いたノードの分類
では、これまでの手順をすべて再現してみましょう。異なるのは特徴量の選択だけです。
pipe_embedding.selectFeatures(['features', 'fastRP_Extended_Embedding'])
次に、エンベディングプロパティを追加し、学習とテストのフェーズを実行します。
trained_pipe_embedding_model.metrics()
エンベディングを考慮することで、テストメトリクスが格段に向上することが分かります。

図22 - 新しいパイプラインの学習時のメトリクス
新しい予測モデルの精度は、89%になりました。

図23 - 予測精度の比較
全くチューニングをせずに、+7%の精度を実現しました。
Bloomでは、100個のPaperノードを表示し、ルールベースのポリシーを適用して、精度の高い予測対象を紺色で表示することができます。
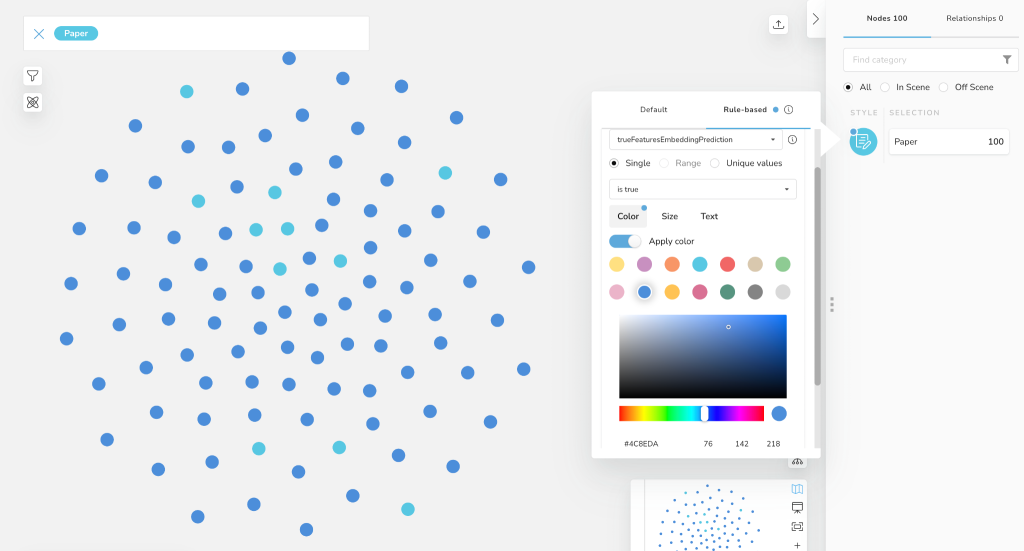
図24 - Bloomルールベースのポリシーによる予測結果の区別
主題の予測に失敗したPaperノードの数は簡単に数えることができます。11/100です。
=> 89%の精度が得られています。6. まとめ
Neo4jとグラフデータサイエンスは、より良い予測結果をもたらします。エンベディングアルゴリズムは、高度な予測機能を生み出し、MLモデルをより正確にします。

図25 - GDSは(1)シンプルであり、(2)データサイエンティストや(3)産業に、(4)より良い予測をもたらす統合ツールです(イメージソースはpexelsから取得)
そして今、ボールはあなたのコートにあるのです。
あなたのデータをグラフとして見ることで、より良い予測パフォーマンスを得ることができるとしたらどうしますか?
データをつなげるのに数秒、価値ある洞察に変換するのに数分かかり、重要な質問に答えることができます。
- 何が重要なのか?
- 何が異常なのか?
- 次はどうなる?
リソース
- CORA Graph Data Science notebook (GitHub)
- Neo4j Graph Data Science Library manual
- このブログは次の環境で実行・テストされています: Neo4j 4.4.x, Neo4j Graph Data Science python client 2.1.9



