
なぜグラフテクノロジーは“未来の技術”なのか? #Neo4j #GraphDatabase #グラフデータベース #ビギナーのためのグラフデータベース

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
本ブログは、Neo4j社のブログでNeo4j社が執筆し、2023年1月19日に公開された「Graph Databases for Beginners: Why Graph Technology Is the Future」の日本語翻訳です。
この「ビギナーのためのグラフデータベース」ブログシリーズでは、グラフテクノロジーに関するバックグラウンドがほとんどない(または全くない)方を想定して、グラフテクノロジーの基本を解説していきます。
今回はグラフデータベースの基本的な定義と、なぜ重要なのかを説明します。

はじめに
グラフデータベース技術について耳にしたことがある方は、その話題について知りたいと思っているのではないでしょうか。
意地悪な目で捉えると、「グラフデータベースは単なる一時的なトレンドに過ぎず、すぐに廃れる。技術的トレンドはすべてそうではないか!」
この皮肉は家に置いておいてください。その代わりに、あなたを新しい世界の見方の冒険へとお誘いします。
グラフのパラダイムは、データベースやアプリケーション開発の枠を超え、「つながり」を軸に何が可能かを再構築するものです。そして、異なる次元から課題にアプローチすることで、可能な解決策が桁違いに変わることがよくあります。
つまり、「グラフテクノロジーは、開発チームにとって、そしてビジネスにとって、見逃すことのできない大きなトレンドです。グラフデータベースは未来の技術であり、どんな初心者であっても、始めるのに遅すぎるということはありません。さっそく使ってみましょう。」
グラフデータベース技術に注目すべき理由
新しいテクノロジーは、プライベートで使う分には楽しいかもしれませんが、仕事となると話は全く別です。
仕事では、予算・スケジュール・会社ルール・競合他社などに囲まれた中で活動しなければなりません。その中で、新技術の絶対的な評価ポイントは、それがちゃんとうまく機能すること。そして、既存のものよりもはるかに優れていることです。
グラフデータベースは、そのような条件を満たします。その理由は以下の通りです:
- スケーラビリティ:
今後もデータ量は確実に増加しますが、それ以上に増加するのが、データ間のつながり(リレーションシップ)です。ビッグデータは間違いなく大きくなり、つながりも指数関数的に大きくなります。従来のデータベースでは、つながりの数や深さが増すにつれて、つながりを取得するクエリは異常終了してしまうことがよくあります。
これに対し、グラフデータベースは、データやビジネスニーズに合わせてスケールアップし、コストやハードウェアを最小限に抑えながら、つながれたデータセットのパフォーマンスを最大限に引き出します。 - 柔軟性:
グラフデータベースでは、ソリューションや業界の変化に応じてグラフデータモデルの構造やスキーマが変化するため、ITチームやデータアーキテクチャチームはビジネスのスピードに合わせて動くことができます。
一方、現在の機能を損なうことなく、既存のグラフモデル構造に新たな構造を追加することができます。RDBMSのデータモデルは、要件を指示し、表形式の方法に適応することを強いています。一方、グラフデータベースモデルでは、変更を指示し、主導権を握るのはあなた自身です。 - 俊敏性:
アジャイルやテスト駆動といった開発手法と、とても親和性が高いです。グラフデータベースを基盤としたアプリケーションは、変化するビジネス要件に合わせて進化させていくことができます。
アジャイル開発チームは、グラフデータベースをオンプレミスまたはクラウドに導入することで、日々の要求に対応するデータベースを手に入れることができます。
グラフデータベースとは何か?(非技術的な定義)
グラフデータベース技術を理解するために、グラフ理論の難解な数学を理解する必要はありません。それどころか、リレーショナルデータベース(RDB)よりも直感的に理解することがでます。
グラフは、ノードとリレーションという2つの要素で構成されています。
各ノードはエンティティ(人・場所・物・カテゴリ・その他のデータの一部)を表し、各リレーションは2つのノードがどのように関連づけられるかを表します。
例を考えてみましょう。Twitterは、数億人の月間アクティブユーザーをつなぐグラフデータベースの完璧な例です。
図1では、Twitterのユーザの一部をグラフデータベースで表現しています。各ノード(Userと表示)は一人のユーザを表し、各ユーザがどのようにつながっているかを表すリレーションシップで結ばれています。図1のように、PeterとEmil、EmilとJohanはお互いをフォローしていますが、JohanはPeterをフォローしているものの、Peterは(まだ)相互フォローしていないことがわかります。
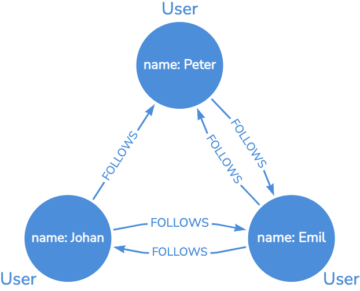
グラフデータベースの構成要素の基本は、これだけで十分です。
グラフデータベースの仕組み(わかりやすく解説します)
他のデータベース管理システム(DBMS)とは異なり、グラフデータベースではリレーションシップが最優先です。グラフの世界では、データ間のつながりが、個々のデータやプロパティ値と同じくらい、いや、それ以上に重要です。
このようなリレーション優先のアプローチは、データのライフサイクルのあらゆる部分(構想から論理モデルでの設計・物理モデルでの実装・クエリー言語による操作・スケーラブルで信頼性の高いデータベースシステム内での永続化まで)において、リレーションシップやつながりが、永続的に維持されるということです。
このアプローチは、他のDBMSとは異なり、アプリケーションが外部キーや、分散コンピューティングを支援するMapReduceのような特殊な処理で、データのつながりを必要になる度に膨大に計算する必要がないことを意味します。
その結果、RDBMSやNoSQLで作成するよりもシンプルで表現力豊かなデータモデルを作成することができます。
グラフデータベースの特徴
多くのデータベースは似たような特徴を持っていますが、グラフデータベースにはユニークな点がいくつかあります。ここでは、グラフデータベース技術の中でも特に理解しておくべき2つの特性を紹介します:
- グラフストレージ:
グラフデータベースの中には、グラフを保存・管理するべく特別に設計されたストレージ層であるネイティブグラフストレージを使用するものがあります。その他のアプローチ方法では、ストレージ層としてリレーショナルデータベース・カラム型データベース・オブジェクト指向データベースを使用しています。非ネイティブストレージは、すべてのグラフリレーションを異なるデータモデルに変換する必要があるため、ネイティブアプローチよりも遅くなることが多いです。 - グラフプロセス:
ネイティブのグラフ処理(別名:インデックスフリーアジェイサンシ index-free Adjacency)は、つながっているノード同士が直接ディスク上で"隣同士であること"を表現するため、グラフ内のデータを処理する最も効率的な手段です。非ネイティブのグラフ処理エンジンは、つながっているデータの処理に最適化されていないため、CRUD(Create, Read, Update, Delete)操作を処理するために、他の非効率的な手段を使用します。
Neo4jはグラフの保存と処理の両方に関して現時点で最もネイティブであるため、このグラフDBMS分野をリードしています。
ネイティブなグラフデータベースと非ネイティブなグラフテクノロジーとの違いについてもっと知りたい方は、このビギナーズシリーズ「ネイティブと非ネイティブのグラフテクノロジーの比較」をお読みください。
結論:グラフはあなたが思っているより、どこにでもある
現実の世界の物事とは相互に密接に関連しており、グラフデータベースは、リアルデータの時に一貫し・時に不規則なつながりを直感的に模倣することを目指しています。
この点が、グラフパラダイムが他のデータベースモデルと異なる点です。つまり、人間の脳がどのように物事を捉えて処理するかを、よりリアルに模倣しようとしているのです。
ある場所(例えば、レコメンデーションエンジン)で相互につながっているデータのグラフで物事を捉え始めたら、他の場所(例えば、不正検出やマスターデータ管理)でも捉え始めるでしょう。やがて、「グラフはどこにでもある」ということに気が付くでしょう。
グラフ・テクノロジーが台頭してきたことは驚くことではありません。
競合他社がグラフデータベースの導入を検討している可能性は十分あります。
グラフデータベース技術を今日から活用することで、あなたのビジネスは今後も競争優位性を維持することができます。この機会に、以下のようなリーディングカンパニーにステップアップすることをお勧めします。
- メレディス・コーポレーション (エンティティ解決)
- eBay (人工知能)
- ピツニーボウズ (マスターデータ管理)
- NASA (ナレッジグラフ)
- その他、Fortune500の金融サービス会社 (不正検知)
「ビギナーのためのグラフデータベース」ブログシリーズの一覧
- なぜグラフテクノロジーは“未来の技術"なのか? 2023.01.19
- ところで「グラフ」ってどういう意味? 2019.12.16
- [随時公開予定]なぜコネクテッドデータが重要なのか? 2018.07.17
- [随時公開予定]データモデリングの基本 2018.07.24
- [随時公開予定]データモデリングの落とし穴 2018.07.31
- [随時公開予定]データベースクエリ言語が思っている以上に重要な理由 2018.08.15
- [随時公開予定]命令型クエリ言語と宣言型クエリ言語の違いとは? 2018.08.21
- [随時公開予定]グラフ理論と予測モデリング 2018.09.05
- [随時公開予定]グラフ検索アルゴリズムの基本 2018.10.10
- [随時公開予定]NoSQLデータベースが必要な理由 2018.10.25
- [随時公開予定]ACIDとBASEの違い 2018.11.13
- [随時公開予定]Aggregate Storesの簡単な解説 2018.11.27
- [随時公開予定]Neo4j以外グラフデータベース技術 2018.12.11
- [随時公開予定]ネイティブと非ネイティブのグラフテクノロジーの比較 2023.05.08



