
MongoDBにおけるレプリケーションの仕組み ~oplogってなに?~

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
MongoDBテクニカルサポート担当の山森です。こちらはクリエーションラインアドベントカレンダー、15日目の記事です。
世間はすっかりクリスマスムードですね。みなさんはどうお過ごしでしょうか。我が家のクリスマスは、モスチキン、近所の洋食屋さんのビーフシチュー、クリスマスケーキといった定番コースのディナーを予定しています。アメリカではフライドチキンではなくターキーを食べるのが定番だそうですが、ここは日本なので、好きなものを食べます。モスチキンはいいぞ。
1歳の息子用のプレゼントの発注も済ませ、自宅に隠してあります。まだクリスマスという概念は分かっていないと思いますが、プレゼントを見せたときにどんな反応をするのか、今から楽しみです。
さて、前回は1日目でこんな記事を書きました。今回は私がテクニカルサポートを担当している、MongoDBについての記事を書いてみることにします。
MongoDBには標準でクラスタを構成する機能があり、レプリカセットと呼ばれています。複数台のMongoDBでクラスタを組み、全員で同じデータを保持することで冗長性を担保しています。
ここでいうクラスタ構成の最小単位は、物理的もしくはVirtual Machineのサーバ1台ですが、MongoDBではノードと表記されることが多いため、今回もそれにならってノードと呼ぶことにします。
アプリケーションからのデータの読み出し・書き込みを受け持つノードをプライマリ、プライマリからデータをコピーして保持する役割のノードはセカンダリと呼ばれます。(※データの書き込みはプライマリのみですが、設定を変えればセカンダリに読み出し担当を任せることもできます。)
通常時はプライマリでデータの読み書きを行いますが、万が一プライマリに障害が発生したらどうなるのでしょうか?
このようなときは、セカンダリが新しいプライマリになることで、データベースとしての仕事を継続します。この一連の動作はフェイルオーバーと呼ばれます。
公式ドキュメントでは3台以上でレプリカセットを組むことが推奨されています。また、MongoDB Atlasでインスタンスをデプロイした場合の構成はレプリカセットの3台構成です。このように、レプリカセットはMongoDBを使用する上で欠かせない機能ですが、実際はどのように実現しているのでしょうか?
レプリカセットとは
MongoDBのReplicationのドキュメントを読んでみましょう。レプリカセットは次の特長を持っています。
- 1台のみのプライマリノードと2台以上のセカンダリノード、オプションでアービター(投票要員)
- プライマリノードがすべての読み出し・書き込みのオペレーションを受け取る
- プライマリはデータセットに対するすべての操作をoplogに記録する
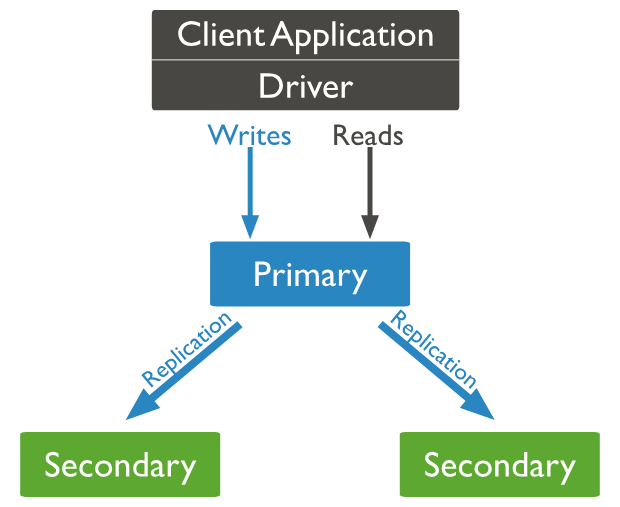
上の図では、プライマリからセカンダリに「Replication」の矢印が伸びていますね。具体的にはどのように実現しているのでしょうか?ドキュメントに以下のように説明されています。
The secondaries replicate the primary's oplog and apply the operations to their data sets such that the secondaries' data sets reflect the primary's data set.
MongoDB公式ドキュメントより
セカンダリはプライマリ内のoplogを自身にコピーし、それを元に、差分を自分が持っているデータセットに非同期で反映します。
「oplog」はデータベースへのオペレーションを記録したものです。つまり、レプリカセット内でデータを同期するときは、データベースのデータそのものではなく、データベースへのオペレーション記録をコピーして、各自の手元のデータベースに反映していることになります。
oplogはどのようなファイルなのでしょうか?oplogに関するドキュメントを見てみましょう。
The oplog (operations log) is a special capped collection that keeps a rolling record of all operations that modify the data stored in your databases.
MongoDB公式ドキュメントより
oplog(オペレーションログ)はMongoDBのデータベース内に、管理用の上限付きコレクションのひとつとして保存されています。デフォルトではディスクサイズの5%のサイズで作成されます。
oplogを見てみよう!
実際にレプリカセットを構築して、oplogを見てみましょう。今回は6.0.6のEnterpriseを使用しています。レプリカセットはプライマリ1台セカンダリ2台の3ノード構成です。構築手順は割愛します。
nika@rep1sv ~ $uname -a Linux rep1sv 5.10.0-23-amd64 #1 SMP Debian 5.10.179-1 (2023-05-12) x86_64 GNU/Linux Using MongoDB: 6.0.6 Using Mongosh: 2.1.0
サーバ内にあるデータベース一覧を見てみます。インストール直後なので、デフォルトの管理用データベースしか存在していません。
Enterprise rs0 [direct: primary] test> show dbs admin 204.00 KiB config 228.00 KiB local 23.55 MiB
localというデータベースの中のコレクション一覧を見てみましょう。一番上に、oplog.rsという名前のコレクションがあります。これがoplogの実態です。
Enterprise rs0 [direct: primary] local> show collections oplog.rs replset.election replset.initialSyncId replset.minvalid replset.oplogTruncateAfterPoint startup_log system.replset system.rollback.id system.tenantMigration.oplogView [view] system.views
oplogはコレクションなので、他のコレクションと同様に中身を見ることができます。
Enterprise rs0 [direct: primary] local> db.oplog.rs.findOne()
{
op: 'n',
ns: '',
o: { msg: 'initiating set' },
ts: Timestamp({ t: 1690855438, i: 1 }),
v: Long('2'),
wall: ISODate('2023-08-01T02:03:58.126Z')
}
レプリカセット関連のコマンドはrs.~で操作可能です。補完されて沢山出てきます。
Enterprise rs0 [direct: primary] test> rs. rs.__proto__ rs.constructor rs.hasOwnProperty rs.isPrototypeOf rs.propertyIsEnumerable rs.toLocaleString rs.toString rs.valueOf rs.initiate rs.config rs.conf rs.reconfig rs.reconfigForPSASet rs.status rs.isMaster rs.hello rs.printSecondaryReplicationInfo rs.printReplicationInfo rs.add rs.addArb rs.remove rs.freeze rs.stepDown rs.syncFrom
例えば、rs.printReplicationInfo()コマンドを使用すると、oplogの実際のサイズや最後に同期した時間が分かります。
Enterprise rs0 [direct: primary] local> rs.printReplicationInfo() actual oplog size '990 MB' --- configured oplog size '990 MB' --- log length start to end '10820290 secs (3005.64 hrs)' --- oplog first event time 'Tue Aug 01 2023 11:03:58 GMT+0900 (日本標準時)' --- oplog last event time 'Mon Dec 04 2023 16:42:08 GMT+0900 (日本標準時)' --- now 'Mon Dec 04 2023 16:42:12 GMT+0900 (日本標準時)'
では、実際にデータベースにデータを追加したら、oplogでどのように記録されるのでしょうか?やってみましょう。
手始めにデータベースとコレクションを作成します。Asticassiaがデータベース名、pilotがコレクション名です。
Enterprise rs0 [direct: primary] test> use Asticassia
switched to db Asticassia
Enterprise rs0 [direct: primary] Asticassia> db.createCollection("pilot")
{ ok: 1 }
Enterprise rs0 [direct: primary] Asticassia> show collections
pilot
oplogでどのように反映されているか、見てみましょう。o.createでpilotが作成されていることがわかります。
Enterprise rs0 [direct: primary] local> db.oplog.rs.find({ "o.create":"pilot" })
[
{
op: 'c',
ns: 'Asticassia.$cmd',
ui: UUID('35e5b59a-5fa4-43c7-8c16-96be4a2415fc'),
o: {
create: 'pilot',
idIndex: { v: 2, key: { _id: 1 }, name: '_id_' }
},
ts: Timestamp({ t: 1701756432, i: 1 }),
t: Long('3'),
v: Long('2'),
wall: ISODate('2023-12-05T06:07:12.966Z')
}
]
レコードを追加してみましょう。(蛇足:insertを使ったらそれはdeprecatedだよと怒られてしまいました。こういう場面ではinsertOneを使った方が良さそうです。)
Enterprise rs0 [direct: primary] Assticasia> db.pilot.insert({ name:"Suletta Mercury",age:17,dorm:"earth" })
DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.
{
acknowledged: true,
insertedIds: { '0': ObjectId('656ec24add675a48e31a3b91') }
}
レコード追加がどのように記録されているのか、oplogを見てみましょう。
Enterprise rs0 [direct: primary] Assticasia> use local
switched to db local
Enterprise rs0 [direct: primary] local> db.oplog.rs.find({ "o.name":"Suletta Mercury"})
[
{
lsid: {
id: UUID('8a0102ce-c139-4d4e-9a56-72bad1f5a85b'),
uid: Binary.createFromBase64('47DEQpj8HBSa+/TImW+5JCeuQeRkm5NMpJWZG3hSuFU=', 0)
},
txnNumber: Long('1'),
op: 'i',
ns: 'Assticasia.pilot',
ui: UUID('91d94105-a7ae-43a6-9d76-f91f43b7b9c3'),
o: {
_id: ObjectId('656ec24add675a48e31a3b91'),
name: 'Suletta Mercury',
age: 17,
dorm: 'earth'
},
o2: { _id: ObjectId('656ec24add675a48e31a3b91') },
stmtId: 0,
ts: Timestamp({ t: 1701757514, i: 2 }),
t: Long('3'),
v: Long('2'),
wall: ISODate('2023-12-05T06:25:14.510Z'),
prevOpTime: { ts: Timestamp({ t: 0, i: 0 }), t: Long('-1') }
}
]
今回はoplog内を確認するためにmongoshを使っていますが、コレクション内を眺めたりするのに少し不都合を感じるかもしれません。そんなときはjsonにしてしまいましょう。みんな大好きなjqを使うことができます。
mongoexportコマンドを使用すれば簡単にjsonにすることができます。その時点のものをダウンロードするので、リアルタイムでoplogを眺める用途には使えません。
nika@rep1sv ~ $mongoexport --collection=oplog.rs --db=local --out=oplog.json 2023-12-05T15:33:41.471+0900 connected to: mongodb://localhost/ 2023-12-05T15:33:42.481+0900 [#.......................] local.oplog.rs 80000/1019090 (7.9%) 2023-12-05T15:33:43.481+0900 [#####...................] local.oplog.rs 216000/1019090 (21.2%) 2023-12-05T15:33:44.490+0900 [########................] local.oplog.rs 344000/1019090 (33.8%) 2023-12-05T15:33:45.482+0900 [###########.............] local.oplog.rs 480000/1019090 (47.1%) 2023-12-05T15:33:46.476+0900 [##############..........] local.oplog.rs 624000/1019090 (61.2%) 2023-12-05T15:33:47.492+0900 [##################......] local.oplog.rs 768000/1019090 (75.4%) 2023-12-05T15:33:48.472+0900 [#####################...] local.oplog.rs 912000/1019090 (89.5%) 2023-12-05T15:33:49.082+0900 [########################] local.oplog.rs 1019096/1019090 (100.0%) 2023-12-05T15:33:49.082+0900 exported 1019096 records
私はよくこれでMongoDBのログを眺めています。気になる方はぜひご自身の環境でoplogを眺めてみてください。
nika@rep1sv ~ $jq -C . oplog.json |less -R
oplogのデータ構造は公式ドキュメントには記載されていないようです。(もちろん私が発見できなかっただけの可能性もあります)海外のブログでソースを読み込んで解説している方がいました。すごい。
レプリカセット間でどうやってoplogを同期しているのか?
プライマリとセカンダリはどのようにoplogを更新しているのでしょうか?それはドキュメントのこのページで解説されています。
Initial SyncとReplicationという2つの同期方法を使っています。
Initial Syncはレプリカセットを最初に構築したときに実行される、いわゆる初期同期です。ReplicationはInitial Syncが終わった後も継続的にデータを同期する仕組みです。
streaming replicationという機能でプライマリからセカンダリにデータストリームを投げています。また、Tailable Cursorsという機能でセカンダリからもプライマリのoplogを追尾します。
詳しいことはMongoDB Universityの「Replication in MongoDB」コースでも解説されているので、気になる方はこちらも受講してみてください。無料です。
おわりに
今回はoplogの正体と仕組みについて追っかけてみました。どのようにレプリケーションを実現しているのか、少し理解が深まって良かったです。oplogの実運用(ウィンドウサイズや更新頻度のパラメータとか)について、もう少し突っ込んで調べたかったですね。そのほかにも、oplogはポイントインタイムリカバリやwrite concern(書き込み保証)の実現に重要な役割をしているので、こちらも調べてまとめようと思っていたのですが、クリスマスどころか年が明けてしまいそうです。またの機会に。
MongoDBは名前(「巨大な」という意味のhumongousという単語が由来しているそうです)の通り、「大量のデータを速度重視でバカスカどんどん突っ込める」というイメージがありました。それを実現するための仕組みのひとつである、Tailable Cursorsのことも知れてよかったです。
それでは、16日目にバトンタッチすることにします。次はどんな記事かな~?



