
LambdaのイベンドソースとしてAmazon MSKを使用する
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
はじめに
今回の記事では、Lambdaのイベンドソース(Trigger)としてAmazon MSKを使用する方法を紹介します。これは、言い換えれば、LambdaをAmazon MSKのConsumerとして使用する方法です。イベントソースとしてMSKを利用すると、一般的なConsumerの実装でみられるような煩雑なコーディングが不要です。MSKからのデータは、Lambdaのイベントデータとして受け取るからです。
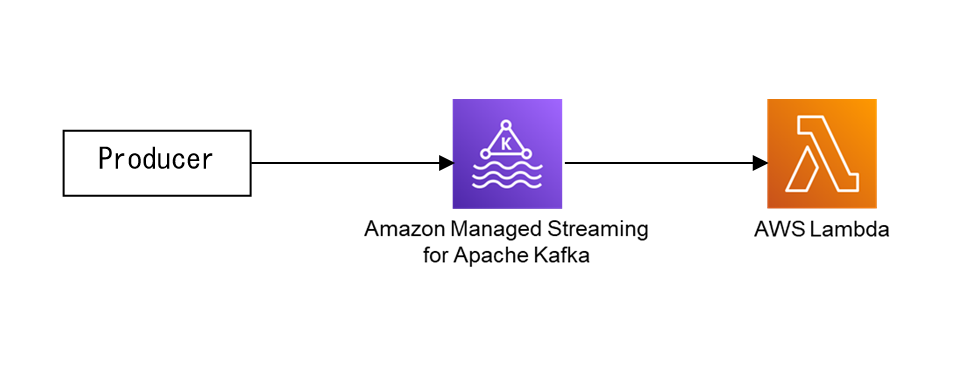
事前準備
Lambdaのためのロールを用意してください。
[MskLambdaRole]
{
Version: "2012-10-17",
Statement: [
{
Effect: "Allow",
Action: [
kafka-cluster:Connect,
kafka-cluster:AlterCluster,
kafka-cluster:DescribeCluster,
kafka-cluster:*Topic*,
kafka-cluster:WriteData,
kafka-cluster:ReadData,
kafka-cluster:AlterGroup,
kafka-cluster:DescribeGroup,
kafka-cluster:DescribeClusterDynamicConfiguration,
kafka:DescribeClusterV2,
kafka:GetBootstrapBrokers,
ec2:CreateNetworkInterface,
ec2:DescribeNetworkInterfaces,
ec2:DescribeVpcs,
ec2:DeleteNetworkInterface,
ec2:DescribeSubnets,
ec2:DescribeSecurityGroups,
logs:CreateLogGroup,
logs:CreateLogStream,
logs:PutLogEvents,
secretsmanager:GetSecretValue,
secretsmanager:DescribeSecret,
glue:GetSchemaVersion,
glue:GetSchemaVersionsDiff,
glue:GetSchema,
glue:GetRegistry
],
Resource: [ * ]
}
]
}
[Trusted Policy]
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}ネットワーク環境やMSKについては、姉妹記事:サーバレスのAmazon MSKクラスターをご参照ください。
Lambda作成
Lambdaを作成してください。
1.タイプの選択:Auther from scrach

2.Function Name: EdaMskTestLambda
3.Runtime: Python3.10
4.Architecture: x86_64
5.Execution role: User an existing role
6.Existing role: MskLambdaRole
7.Advanced setting :Enable VPC
8.VPC: eda-vpc
9.Subnets: eda-subnet-private-northeast-{1a,1c,1d}
10.Security groups: eda-security-g-private
11.Create Functionをクリック
Lambdaを作成したら、lambda_function.pyのソースコードを編集してください。初期状態では、次のようになっているはずです。
import json
def lambda_handler(event, context):
# TODO implement
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}
次のようにイベントソースから受け取ったメッセージのバリューを表示してみます。
import json
def lambda_handler(event, context):
# 全イベントデータを表示
print("Received event:", json.dumps(event, indent=2))
# 各レコードを処理
for record in event['records']:
# キーと値をデコード
key = record['key']
value = record['value']
# レコードの詳細を表示
print(f"Key: {key}, Value: {value}")
# 処理結果を返す
return {
'statusCode': 200,
'body': json.dumps('Event processed successfully!')
}
イベントソース設定(Add Trigger)
+Add triggerをクリックし、イベントソースを設定してください。

1.Select a source: MSK

2.MSK cluster: test-msk-cluster-1
3.Authentication: -
4.Secret Manager key: -
5.Active trigger: checked
6.Batch size: 100
7.String postion: Trim horizon(earlest相当)
8.Batch windows: -
9.Topic Name: testTopic
10.Consumer group ID(Option):testTopic-g1
11.Addボターンをクリック
イベントデータの受信を確認
姉妹記事:Amazon MSKを使用したデータ送受信プログラムの開発を参照し、メッセージを送信してみてください。
$ python procedure.py
Produced: {'orderId': 04b15cb6-afb0-4288-a197-7244c75884f7', 'time': '2024-01-03T10:50:06.282572', 'bookName': 'Book F', 'price': 48.72}結果は、Cloud WatchのLog Groupから確認できます。
/aws/lambda/EdaMskTestLambdログを確認してください。次のようなメッセージが表示されているはずです。
Partition: testTopic-1, Offset: 2948, Value: {
"orderId": "04b15cb6-afb0-4288-a197-7244c75884f7",
"time": "2024-01-03T10:50:06.282572",
"bookName": "Book F",
"price": 48.72
まとめ
このようにLambdaでMSKをイベントソースとして使用する場合、一般的なConsumerの開発に比べ、コーディングがとても簡単です。開発者は、特にConsumerであることを意識する必要がありません。また、サーバーレスプラットフォームで運用できるメリットも非常に大きいです。Consumerを開発し、EC2やコンテナーで運用する場合と比較してみてください。
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



