
NVIDIA-NIMの発表内容について

この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
NVIDIA-NIMの概要
先日、NVIDIA-NIMが発表されました。NVIDIA-NIMは、AIモデルの大規模展開に最適化された推論マイクロサービスを提供します。この多彩なランタイムは、「オープンソースモデル」から「NVIDIA AI 基盤モデル」さらには「カスタムAIモデル」まで、幅広いAIモデルをサポートします。業界標準のAPIを活用することで、開発者はわずか数行のコードで、エンタープライズ規模のAIアプリケーションを迅速に構築できるというものです。その特長や利点について様々な記事から抜粋してまとめてみようと思います。
NVIDIA-NIMの3つの特
- 自己ホスト型展開: NVIDIA-NIMを使用すると、AIモデルを独自のインフラストラクチャにホストすることができ、モデルに送信されるデータが自社の施設を離れることはありません。これは、機密データを扱うアプリケーション(例: 検索増強生成(RAG)システム)に特に有用です。
- 事前構築済みコンテナ: NVIDIA-NIMには、最新の生成AIモデル用のいくつかの事前構築済みコンテナが付属しており、煩雑なセットアップなしに必要なモデルを迅速に選択して展開することができます。
- スケーラブル推論: NVIDIA-NIMは信頼性の高いスケーラブルな推論を提供するよう設計されており、プロトタイプから本番向けのAIアプリケーションへの移行を容易にします。
NVIDIA-NIMは、エンタープライズ全体での生成AIの展開を加速させるために設計されたクラウドネイティブなマイクロサービスのコレクションです。これはNVIDIA AI Enterpriseプラットフォームの一部であり、本番向けのAIアプリケーションの開発と展開を効率化しています。
NVIDIA-NIMの特徴
NVIDIA-NIMには、業界標準のAPI、ドメイン固有のコード、NVIDIA Triton Inference Server、NVIDIA TensorRT、NVIDIA TensorRT-LLMなどの効率的な推論エンジンが含まれています。これは幅広いスペクトラムのAIモデルをサポートし、開発者がわずか数行のコードで企業向けのAIアプリケーションを迅速に構築できるようにしています。
NVIDIA-NIMの利点
NVIDIA-NIMの利点には、AIを活用した職場アプリの簡素な作成手法、スケーラブルなAI推論の円滑化、本番向けのAIモデルの作成とパッケージ化の複雑さの削減が含まれています。これは開発者の数を増やし、GPUアクセラレートワークステーション、クラウド環境、データセンターでの生成AIモデルの展開を効率化することを目指しています。
NVIDIA NIM による AI 推論処理の最適化のキーポイント
NVIDIA NIMを使用することで、10~100倍のビジネスアプリケーション開発者が、AI開発の複雑な領域と企業の運用要件とのギャップを埋めることで、組織のAI変革に貢献できます。
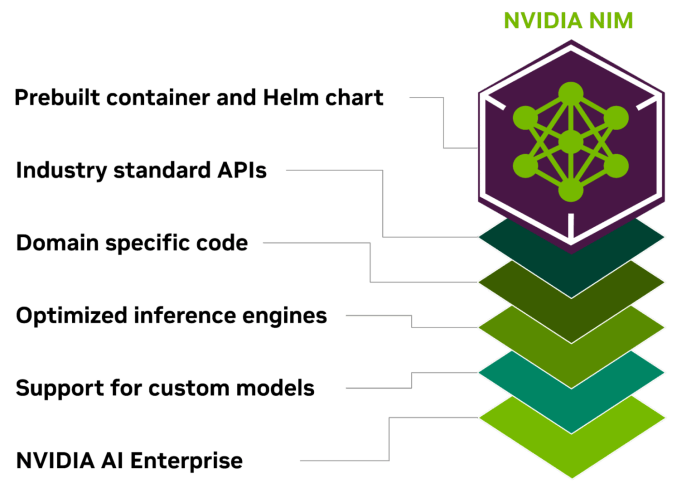
図:業界標準のAPI、特定のドメインのコード、効率的な推論エンジン、エンタープライズランタイムがすべて含まれているNVIDIA NIM、コンテナ化された推論マイクロサービス。
NIMの主な利点
どこにでもインストール可能
NIMの制御可能でポータブルなアーキテクチャにより、NIMはローカルワークステーション、クラウド、オンプレミスデータセンターなど、さまざまなインフラストラクチャにモデルを展開できます。これには、NVIDIA RTXを搭載したワークステーションやPC、NVIDIA Certified Systems、NVIDIA DGX、NVIDIA DGX Cloudが含まれます。
さまざまなNVIDIAハードウェアプラットフォーム、クラウドサービスプロバイダ、Kubernetesディストリビューションは、最適化されたモデルが詰め込まれた事前構築のコンテナやHelmチャートに対して厳格な検証とベンチマークプロセスが行われます。これにより、企業は生成AIアプリケーションをどこにでも展開し、アプリと扱うデータに完全な制御を維持できます。また、NVIDIAによって提供されるすべての環境をサポートします。
開発時に業界標準のAPIを使用
各ドメインの業界標準に従うAPIを使用することで、開発者はAIモデルにアクセスしやすくなり、エコシステムの通常の展開手順との互換性により、わずか3行のコードでAIアプリを迅速に更新できます。シームレスな統合と使いやすさにより、企業システム内でのAIテクノロジーの迅速な実装とスケーラビリティが実現されます。
特定のドメイン向けのモデルを使用
NVIDIA NIMは、特定のドメイン向けのソリューションと最適なパフォーマンスの要求にも応えます。言語、音声、ビデオ処理、医療など、さまざまな分野に関連する専門コードとNVIDIA CUDAライブラリがバンドルされています。この方法により、アプリは特定のユースケースに正確で関連性があります。
チューニングされた推論エンジンを使用
NIMは、各モデルとハードウェア構成に合わせてチューニングされた推論エンジンを使用することで、高速なインフラストラクチャで最適なレイテンシとパフォーマンスを提供します。これにより、推論ワークロードの運用コストを低減しながらエンドユーザーエクスペリエンスを向上させます。また、開発者は、データセンター内に残るプライベートデータソースとモデルを整合させ最適化することで、より高い精度と効率を得ることができます。
エンタープライズレベルのAIの支援
NIMは、NVIDIA AI Enterpriseの一部であり、企業向けの強固な基盤コンテナを使用して構築されており、機能ブランチ、厳格な検証、エンタープライズサポートのためのサービスレベル契約、定期的なCVEセキュリティのアップグレードを通じて、実世界の環境でスケーラブルで効果的かつパーソナライズされたAIシステムの実装においてNIMの重要性が強調されます。
多くのAIモデルをサポート
NIMは、コミュニティモデル、NVIDIA AI Foundationモデル、NVIDIAパートナーから提供される特注モデルを含む多くのAIモデルをサポートし、大規模言語モデル(LLM)、ビジョン言語モデル(VLM)、音声、画像、ビデオ、3D、薬剤探索、医療画像などが含まれます。
NVIDIAが提供するクラウドAPIを使用して、開発者は最新の生成AIモデルをテストできます。または、NIMをダウンロードして自分でモデルをホストすることもできます。この場合、NIMを迅速に展開することで、開発時間、複雑さ、費用を削減できます。
NIMマイクロサービス
NIMマイクロサービスは、業界標準のAPIを提供し、アルゴリズム、システム、ランタイムの改善をバンドルすることで、AIモデルの展開プロセスを合理化します。これにより、開発者は複雑なカスタマイズや専門知識なしにNIMを既存のインフラストラクチャやアプリケーションに組み込むことができます。
企業は、AIインフラストラクチャを最適なパフォーマンスとコスト効率に最適化するためにNIMを使用できます。NIMは、高速なAIインフラストラクチャの上でのパフォーマンスとスケーラビリティを向上させながら、ハードウェアおよび運用コストを削減します。
Nvidia NeMoによるマルチモーダル
企業向けのカスタマイズされたモデルを作成したい企業向けに、NVIDIAはクロスドメインモデルのマイクロサービスを提供しています。NVIDIA NeMoを使用すると、マルチモーダルモデル、音声AI、LLMをプライベートデータを使用して微調整できます。NVIDIA BioNeMoは、生成生物学、化学、分子予測のためのモデルライブラリを使用して、薬剤開発プロセスを迅速化します。Edifyモデルを使用すると、NVIDIA Picassoがクリエイティブな操作を高速化します。これらのモデルのトレーニングにより、視覚コンテンツの開発にカスタマイズされた生成AIモデルを実装できます。
AI駆動開発について興味関心があり、
ご相談があれば以下よりお問い合わせください

主要データプラットフォームプロバイダーとの協力も発表
Box、Cloudera、Cohesity、Datastax、Dropbox、NetAppなどの主要データプラットフォームプロバイダーは、NVIDIAマイクロサービスと協力して、RAGパイプラインを効率化し、独自のデータを生成AIアプリケーションに統合しています。SnowflakeはNeMo Retrieverを使用して、AIアプリケーション向けに企業データを収集しています。
インフラストラクチャとソフトウェアプラットフォームでのNVIDIAマイクロサービスのサポート
NVIDIAマイクロサービスは、NVIDIA AI Enterprise 5.0に含まれており、一般的なクラウドや400以上のNVIDIA認定システムなど、さまざまなインフラストラクチャでサポートされています。VMware Private AI FoundationやRed Hat OpenShiftなどのインフラストラクチャソフトウェアプラットフォームも、最適化されたセキュリティ、コンプライアンス、および制御機能を備えた生成AI機能の簡単な統合のためにNVIDIAマイクロサービスをサポートしています。
NVIDIAエコシステム内でのサポートの拡大
Abridge、Anyscale、Dataiku、DataRobot、H2O.aiなどのNVIDIAのエコシステムパートナーは、NVIDIA AI Enterpriseを通じてNVIDIAマイクロサービスのサポートを拡大しています。さらに、Apache Lucene、Datastax、Faissなどのベクトル検索プロバイダーは、企業向けの応答性の高いRAG機能を強化するために、NVIDIA NeMo Retrieverマイクロサービスと協力しています。
CUDA-X Microservices for RAG, Data Processing, Guardrails, HPC
CUDA-Xマイクロサービスは、データの準備、カスタマイズ、トレーニングのためのエンドツーエンドのビルディングブロックを提供し、さまざまな産業における製品AI開発のスピードを向上させます。
AIの導入を加速するために、企業はNVIDIA Rivaを使用してカスタマイズ可能な音声および翻訳AI、NVIDIA cuOpt™を使用してルーティングの最適化、および高解像度の気候および天候シミュレーションのためのNVIDIA Earth-2など、CUDA-Xマイクロサービスを利用できます。
NeMo Retriever™マイクロサービスを使用すると、開発者はAIアプリケーションをビジネスデータにリンクさせることができ、テキスト、画像、棒グラフ、折れ線グラフ、円グラフなどの視覚化を含む高精度で文脈に即した応答を生成できます。これらのRAG機能により、企業は共同運転者、チャットボット、生成AI生産性ツールによりより多くのデータを提供し、精度と洞察を向上させることができます。
NVIDIA NeMo™マイクロサービスには、近日中にカスタムモデル開発用の追加のサービスが登場します。これには、トレーニングおよび検索用のクリーンなデータセットを構築するNVIDIA NeMo Curator、特定のドメインデータでLLMを微調整するNVIDIA NeMo Customizer、AIモデルのパフォーマンスを分析するNVIDIA NeMo Evaluator、およびLLM用のNVIDIA NeMo Guardrailsが含まれます。
NIMインファレンスマイクロサービスによる、デプロイ作業が数週間から数分に短縮
NIMインファレンスマイクロサービスは、NVIDIAの推論ソフトウェア(Triton Inference Server™およびTensorRT™-LLMを含む)によってパワードされた事前構築済みコンテナを提供し、開発者が展開時間を数週間から数分に短縮できるようにします。
これらは、言語、音声、および医薬品探索などの業界標準のAPIを提供し、開発者が独自のデータを安全に自社インフラでホストしてAIアプリケーションを迅速に構築できるようにします。これらのアプリケーションは需要に応じてスケーリングでき、NVIDIAアクセラレーテッドコンピューティングプラットフォームで生成AIを本番環境で実行するための柔軟性とパフォーマンスを提供します。
NIMマイクロサービスは、NVIDIA、A121、Adept、Cohere、Getty Images、Shutterstockからのモデルの展開に最も高速かつ高性能な本番用AIコンテナを提供し、Google、Hugging Face、Meta、Microsoft、Mistral AI、Stability AIからのオープンモデルも提供します。
ServiceNowは本日、NIMを使用して、新しい特定ドメインのコパイロットやその他の生成AIアプリケーションをより迅速かつ費用効果的に開発および展開していることを発表しました。(下記に発表内容を記載)
顧客は、Amazon SageMaker、Google Kubernetes Engine、Microsoft Azure AIからNIMマイクロサービスにアクセスし、Deepset、LangChain、LlamaIndexなどの人気のあるAIフレームワークと統合できます。
NVIDIA-NIM を LangChainにて統合する実装例
NVIDIA-NIMをLangChainと使用するには、専用の統合パッケージをインストールできます。
pip install langchain_nvidia_ai_endpoints
このパッケージは、NVIDIA-NIMと連携するためのLangChain固有のコンポーネントを提供します。NVIDIAEmbeddingsやChatNVIDIAクラスなどが含まれます。
以下は、NVIDIA-NIMをLangChainと組み合わせてRetrieval Augmented Generation (RAG)アプリケーションを構築する方法の例です。
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings, ChatNVIDIA
from langchain_community.vectorstores import FAISS
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import chain
# Load and process the documents
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
documents = text_splitter.split_documents(docs)
# Initialize the NVIDIA-Nim components
embeddings = NVIDIAEmbeddings()
model = ChatNVIDIA(model="mistral_7b")
# Create the vector store and retriever
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
# Define the hypothetical document generator
hyde_template = """
Even if you do not know the full answer,
generate a one-paragraph hypothetical answer to the below question:
{question}
"""
hyde_prompt = ChatPromptTemplate.from_template(hyde_template)
hyde_query_transformer = hyde_prompt | model | StrOutputParser()
@chain
def hyde_retriever(question):
hypothetical_document = hyde_query_transformer.invoke({"question": question})
return retriever.invoke(hypothetical_document)
# Define the final answer generation chain
template = """
Answer the question based only on the following context: {context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
answer_chain = prompt | model | StrOutputParser()
@chain
def final_chain(question):
documents = hyde_retriever.invoke(question)
for s in answer_chain.stream({"question": question, "context": documents}):
yield s
# Use the final chain to generate an answer
for s in final_chain.stream("how can langsmith help with testing"):
print(s, end="")
この例では、langchain\_nvidia\_ai\_endpoints パッケージで提供されるNVIDIA-NIMコンポーネントを使用して、仮想的なドキュメント埋め込み(HyDE)を活用したRAGアプリケーションを構築します。主なステップは次のとおりです:
- NVIDIA-NIM埋め込みと言語モデルを初期化します。
- NVIDIA-NIM埋め込みを使用してベクトルストアとリトリーバを作成します。
- NVIDIA-NIM言語モデルを使用して仮想的なドキュメント生成チェーンを定義します。
- 仮想的なドキュメントリトリーバと最終的な回答生成チェーンを組み合わせて、最終結果を生成します。
NVIDIA-NIMをLangChainと組み合わせることで、NVIDIAの推論マイクロサービスのパフォーマンスと拡張性の利点を活用しながら、LangChainフレームワークが提供する柔軟性と抽象化を利用することができます。
ServiceNow社とNVIDIA社のパートナーシップによるテレコム業界向けの次世代AI協業戦略の発表

パートナーシップ概要
NVIDIAとServiceNowは、Now Platform上でテレコム向けの生成AIソリューションを導入するために協力関係を拡大しています。最初のソリューションである「Now Assist for Telecommunications Service Management (TSM)」は、NVIDIA AIを使用して顧客体験を向上させ、エージェントの生産性を向上させます。世界の通信事業者の73%が最優先の変革課題としてAI/MLへの投資を行っており、GenAIはテレコム業界に革新をもたらし、使用ごとに学習・改善する能力を提供し、これまでにないレベルのビジネス価値と影響をもたらします。ServiceNowとNVIDIAの協力により、テレコム業界はGenAIを活用して特定の課題に対処し、より強力で効果的なエクスペリエンスを創造することができます。
ユースケースの例;
これらのユースケースには次のものが含まれます:
顧客サービス: Telcoの顧客サービス担当者には、クライアントに正確で迅速な支援を提供することが求められます。 GenAIによるエージェント支援機能やチャット要約機能は生産性を向上させ、コールの回避に不可欠です。 GenAIは、エージェントに最適な対応策を提供するだけでなく、ケースの活動、作業ノート、および顧客とのやり取りをまとめることができます。これにより、エージェントによる迅速な顧客サービスが実現し、彼らは個別の注意を要する複雑な問い合わせに集中することができます。
サービス保証: GenAIは、インシデントをサービス保証チーム、利害関係者、および顧客に対して簡素で正確かつ迅速に理解させることができます。 光ファイバーの切断など、通信事業者に問題を引き起こす典型的なサービス保証のユースケースを考えてみましょう。これらのインシデントの対処は、技術データの取り扱いや専門用語や略語による誤解の可能性など、インシデント管理チームに多くの課題を提供します。 GenAIは技術用語を簡素化し、複雑な情報を要約することで、問題解決を迅速化し、コストを節約し、顧客満足度を向上させます。
Servicenowコンサルティングサービス
Servicenow開発支援:
ソフトウェア会社ServiceNowが提供する、ビジネスにおけるさまざまな管理ワークフローを自動化するためのクラウドベースのAI駆動プラットフォームです。同社の専門分野はITビジネス管理、ITオペレーション管理、およびITサービス管理です。
ServiceNowコンサルサービスの内容
企業は単一のクラウドプラットフォームで革新を推進し、計画から運用までのITバリューチェーンを変革し、ビジネスの優先事項との整合性を向上させることができます。
- 継続的な運用を自動化
- ServiceNowは繰り返しのタスクを自動化することで、管理作業に費やす時間を劇的に削減し、従業員の日常業務を効率化します。
- タスクの自動割り当てと優先順位付け
- 入ってくる作業依頼は、ServiceNowによってエージェントの容量、可用性、スキルレベルに応じて自動的に割り当てられ、優先順位が付けられます。
- ステークホルダーに対する透明なビューを維持
- ServiceNowはすべてのプロジェクトでのオープンネスと協力のための統合プラットフォームを提供し、すべての企業のステークホルダーを完全に情報提供します。
- 複数のシステムを1つのアーキテクチャに統合
- ServiceNowの柔軟性と統合により、ビジネスは複数のITシステムを1つのプラットフォームに統合することができます。これは今日のネットワーク化された職場で有利です。
AI駆動開発について興味関心があり、
ご相談があれば以下よりお問い合わせください
参照記事



