
ChatGPTやAzure OpenAI Serviceの課金単位「トークン」とは? 計算してみよう #ai
この記事は1年以上前に投稿されました。情報が古い可能性がありますので、ご注意ください。
2024年4月現在、ChatGPTで利用されているGPT-4をAPIで利用する場合の価格は入力が 30USD/1Mトークン、出力が 60USD/1Mトークンとなっています。一方、Azure OpenAI ServiceでGPT-4をAPIで利用する場合の価格は入力が 0.03USD/1,000トークン、出力が 0.06USD/1,000トークンとなっています。1USD=150JPYで計算すると両者ともに、1万トークン入力で45円、1万トークン出力で90円のようです。このようにGPT-4をAPIで利用する場合は入出力トークン分の従量課金制となっています(なお、ChatGPTの有料版は2024年4月現在、月額定額制です)。
では、この「トークン」とは何でしょうか? トークンが何かわからなければ、予算や費用の予測がつきませんし、料金体系が妥当なのかもわかりません。早速調べていきましょう。
OpenAIの「トークンって何?」
OpenAIのFAQに「What's a token?」というそのものズバリなQ&Aがありました。
You can think of tokens as pieces of words used for natural language processing. For English text, 1 token is approximately 4 characters or 0.75 words. As a point of reference, the collected works of Shakespeare are about 900,000 words or 1.2M tokens.
To learn more about how tokens work and estimate your usage…
- Experiment with our interactive Tokenizer tool.
- Log in to your account and enter text into the Playground. The counter in the footer will display how many tokens are in your text.
これを和訳してみましょう。
「トークン」とは、自然言語処理に使われる単語の一部と考えることができる。英文であれば、1トークンはおよそ4文字または0.75単語である。参考: シェイクスピアの全作品は90万単語か120万トークンである。
どうやらトークンは厳密な1単語ではなく、文字数で計算されるようです。シェイクスピアを例に取ると、英単語数の約1.3倍がトークン数となるようです。シェイクスピア全集をGPT-4に入力すると、36USD=5400JPY(1ドル150円計算)となるでしょうか。
筆者はシェイクスピアを全部読んだことがないのでピンと来ませんが、おおざっぱに「英単語数の約1.3倍がトークン数」と考えておけば、おおよその価格感がつかめるのかもしれません。
引き続き和訳していきましょう。
さらにトークンの仕組みと使用量を学ぶには…
- インタラクティブな トークナイザーツール を試してみてください。
- アカウントにログインし、プレイグラウンドに文章を入力してください。フッターのカウンタに、文章内のトークン数を表示します。
「トークナイザーツール」を利用すると、文章のトークン数を調べることができるようです。次項ではこのトークナイザーを見ていきましょう。なお、本稿では「プレイグラウンド」は割愛します。
OpenAIのトークナイザー
Tokenizer では、入力した文章をトークン化して可視化し、さらに含まれるトークンの数を表示します。
FAQにあったようにシェイクスピアの作品を入力しようと思いましたが、ここではオー・ヘンリーの短編「賢者の贈り物 (原題: The Gift of the Magi)」を使うことにしました。原文はThe Project Gutenberg から頂きました。
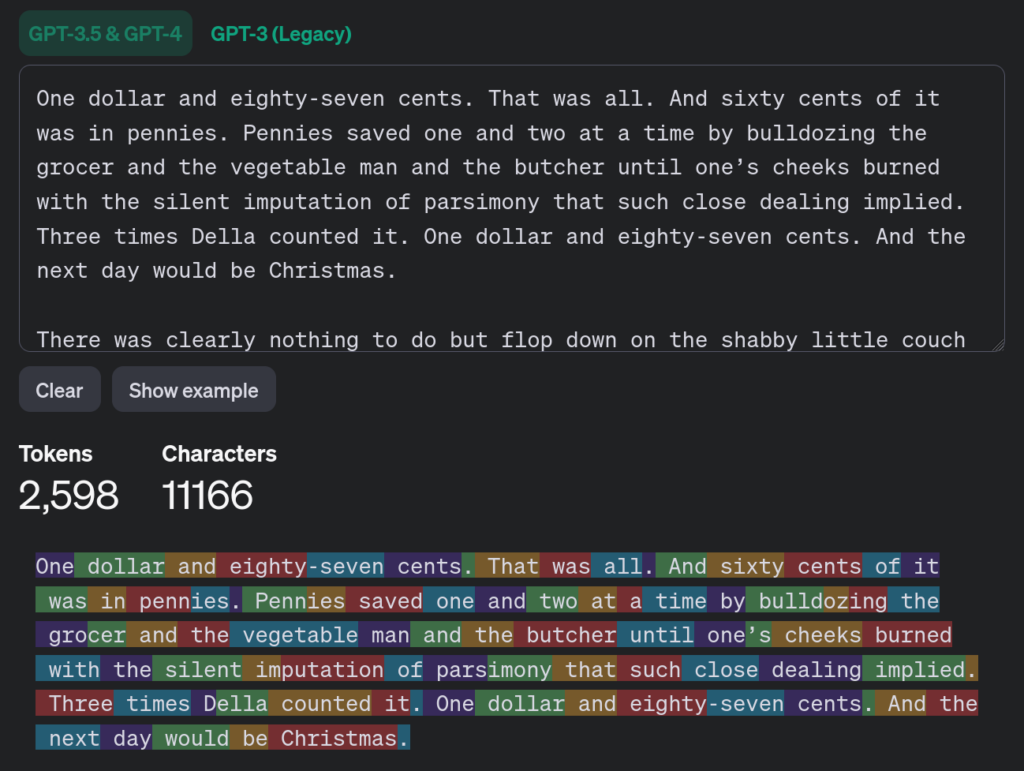
「賢者の贈り物」は 2,598トークン(11,166文字)となりました。なお、別に単語数を数えてみると2,057語のようで、トークン数はおおよそ1.27倍となっています。
さらに下を見ると、どのようにトークンに分割されたか色分けて可視化されていることがわかります。1単語1トークンに対応していると思いきや「pennies」は「penn」と「ies」の2トークンに、「bulldozing (無理強い)」は「bulld」「oz」「ing」の3トークンに分割されているようです。
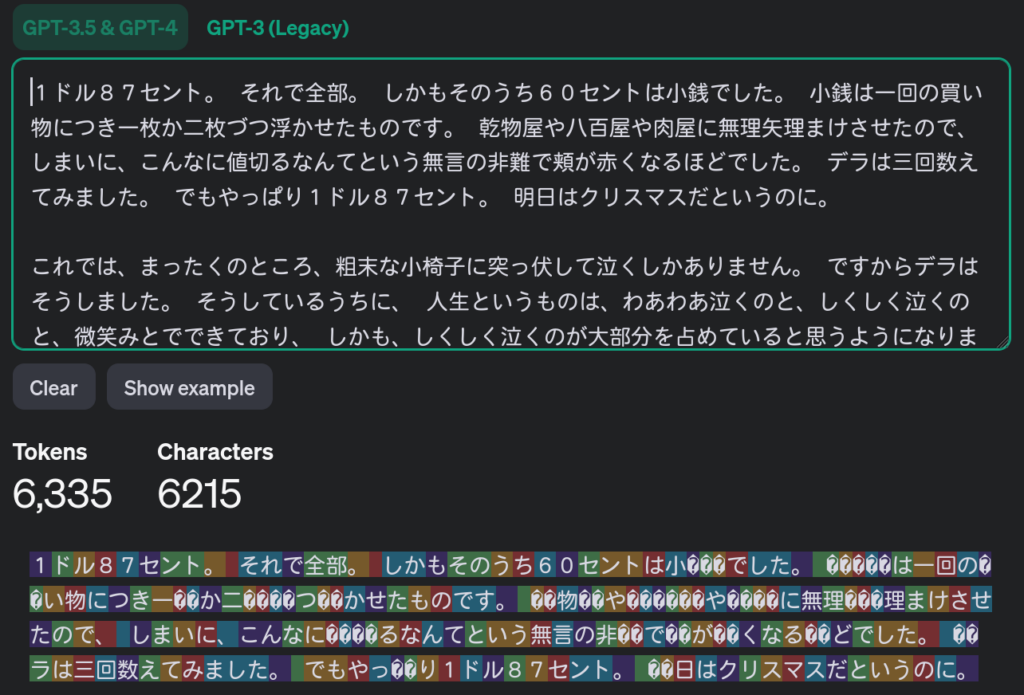
さて、日本語の文章だとどうなるでしょうか? 同じくオー・ヘンリーの短編「賢者の贈り物」を使いましょう。翻訳文はプロジェクト杉田玄白 (Copyright (C) 1999 Hiroshi Yuki (結城 浩))から頂きました。

日本語の「賢者の贈り物」は6,335トークンとなりました。特筆すべきは文字数で、6,215文字となっているところです。英語では文字数よりトークン数が圧倒的に小さくなりましたが、日本語では文字数とトークン数がほぼ等しいどころか、トークン数のほうが増えてしまっています。
トークン分割の可視化表示を見てみましょう。ぱっと見ただけでもとてもカラフルで、どうやらほとんど1文字が1トークンになっているように見えます。さらに、「小銭」の「銭」は3トークンに細切れになってしまっています。UTF-8では漢字を表すのに3バイト必要なため、おそらく1バイトにつき1トークンとなってしまっているのでしょう。
tiktokenとは
日本語では1文字が1〜3トークンになるらしいと予想できましたが、厳密に計算するために毎回 Tokenizer にコピー&ペーストするのもいかがなものかと思います。トークナイザーのページの下のほうを見ると、次の文があることに気がつきます。
If you need a programmatic interface for tokenizing text, check out our tiktoken package for Python. For JavaScript, the community-supported @dbdq/tiktoken package works with most GPT models.
このトークン化を行うための tiktoken という Python ライブラリがあるようです。某ショート動画SNSとそっくりな名前ですが、まったく関係ないようです…。こちらを見てみると、
tiktoken is a fast BPE tokeniser for use with OpenAI's models.
とあります。どうやら バイト対符号化 という方法でトークン化を行っているようです。
頻出するバイト列とトークンの組み合わせはどのようになっているのでしょうか? tiktoken では、この組み合わせのことを「エンコーディング」と呼んでいるようです。各モデルで使われているエンコーディングは tiktoken/model.py ファイルに記載があります。GPT-4 では「cl100k_base」というエンコーディングを使っているようです。他には「r50k_base」や「p50k_base」などがあるようです。
ライブラリ内にエンコーディング自体は含まれていません。tiktoken_ext/openai_public.py ファイルを見ると、どうやら Azure Blob Storage からダウンロードしている模様です。
GPT-4で使われている cl100k_base エンコーディングファイルを実際にダウンロードしてみましょう。中身は単なるテキストファイルでした。
IQ== 0 Ig== 1 Iw== 2 JA== 3 JQ== 4 Jg== 5 Jw== 6 KA== 7 KQ== 8 Kg== 9 (中略) IHLDqXN1bHRhdHM= 100246 IG1vZGVu 100247 IEljZWxhbmRpYw== 100248 O2Q= 100249 LmFsbG93ZWQ= 100250 KG5ld1VzZXI= 100251 IG1lcmNpbGVzcw== 100252 LldhaXRGb3I= 100253 IGRheWNhcmU= 100254 IENvbnZleW9y 100255
どうもエンコーディング名の cl100k_base の「100k」とは、トークン数が約10万である、という意味のようです。本稿では取り上げませんが「r50k_base」や「p50k_base」の 50k は約5万を示しているようです。なお、「cl」「r」「p」が何を意味しているのかはわかりませんでした。
cl100k_base の中身をさらに見てみましょう。ファイル先頭の「IQ== 0」からの並びからすると「IQ」のトークンが「0」である、というイコールの意味を取ってしまいそうですが、ファイル末尾のほうを見ると必ずしもイコールを含んでいるわけではないようです。ということは…これは Base64 でエンコーディングされたバイト列と予想できます! 「IENvbnZleW9y」をデコードしてみましょう。
% python3 -c 'import base64; print(base64.b64decode("IENvbnZleW9y"))'
b' Conveyor'
%
英単語が出てきました! どうやらtiktokenでcl100k_baseエンコーディングを使ってトークン化すると、「 Conveyor」(注:先頭にスペースを含む)は100255になるのでしょう。このcl100k_baseエンコーディングの中に日本語の単語はおそらく含まれていないため、あのように細切れになってしまっているのでしょう。なお、cl100k_baseがそもそもどういう理論で生成されたものなのかはわかりませんでした。
tiktokenを使ってみよう
tiktokenの理屈はなんとなくわかってきたので、実際にtiktokenを使ってみましょう。単純に Python のワンライナーで実行してみます。
% python3 -c 'import tiktoken; enc = tiktoken.get_encoding("cl100k_base"); print( enc.encode(" Conveyor"))'
[100255]
%
「 Conveyor」(注:先頭にスペースを含む)は確かに100255にトークン化されました。「賢者の贈り物」の冒頭1文目をトークン化してみましょう。
% python3 -c 'import tiktoken; enc = tiktoken.get_encoding("cl100k_base"); print( enc.encode("One dollar and eighty-seven cents."))'
[4054, 18160, 323, 80679, 79125, 31291, 13]
%
Tokenizer に入力した際もこの文は7トークンになっていました。tiktokenでも同じく7トークンになっているようです。日本語文だとどうでしょうか?
% python3 -c 'import tiktoken; enc = tiktoken.get_encoding("cl100k_base"); print( enc.encode("1ドル87セント。"))'
[20713, 45923, 33710, 66115, 66224, 64810, 52414, 1811]
%
8トークンと、Tokenizer と同じ結果になっています。ところでよく見ると「セント」は「セ」「ン」「ト」ではなく「セ」「ント」になっているようです。7トークン目の「52414」が「ント」のようです。cl100k_baseエンコーディングファイルの52414を見てみましょう。
44Oz44OI 52414
「44Oz44OI」をBase64デコードすると…?
% python3 -c 'import base64; print(base64.b64decode("44Oz44OI"))'
b'\xe3\x83\xb3\xe3\x83\x88'
% python3 -c 'import base64; print(base64.b64decode("44Oz44OI").decode("utf-8"))'
ント
%
「ント」が出てきました! 「セント」が「セ」「ント」のようにトークン化されたのは、「ント」がcl100k_baseエンコーディングに含まれていたからということがわかりました。前述の通りcl100k_baseがどういう理屈で生成されたのかわからなかったため、「ント」が含まれていたことの理由もまた不明です。
ともかく、tiktokenを使えばGPT-4に文章を入力する前に、その文章が何トークンあるのかを知ることができそうです。
まとめ
本稿ではChatGPTやAzure OpenAI Serviceが利用するGPT-4で扱っている「トークン」とは何かについて調べてみました。トークンとはバイト対符号化により分割した一単位であり、規則に基いてトークン化を行っていると考えられます。このトークン化の規則である「cl100k_base」やライブラリのtiktokenが公開されているため、これらを利用することで入力する前におおよそのトークン数を知ること・利用料金の予測を立てることが可能です。
一方で、次の点が気になります:
- 事前に知ることができるのはあくまでも「入力」トークン数である。
- どれだけのトークン数が「出力」されるかはわからないため、結局どれだけの料金がかかるか正確な値は不明である。
- 出力のほうがトークン当たりの費用が高いことに注意が必要である。
- 実際にtiktokenやcl100k_baseを使っているのか不明である。
- 本稿で確認した限り一致しているようだが、サンプル数は少ない。
- プロプライエタリサービスであるので、最終的にはサービス提供者を信用するしかない。
トークンにかかるコストが膨大になる場合、もしかするとローカルLLMという選択肢も一考の余地はあるかもしれません。ローカルLLMの意義に関しては「おうちでChatGPTやってみたい! ローカルLLM(大規模言語モデル)はどこまでできるか?」も参照してください。
クリエーションラインでは今後も生成AIに関する調査や情報発信を続けていきたいと思います。
生成AIについて興味関心があり、
ご相談があれば以下よりお問い合わせください

Author
はやりの技術要素に加えて、会議の進め方・文章の書き方などの業務改善にも取り組んでいます。「Chef活用ガイド」共著のほか、Debian Official Developerもやっています。



