
大規模言語モデルによるナレッジグラフ自動化の概念検証[3]
―GraphRAGへの道とNeo4j Vector Index ―
はじめに
ここまでの連載では、ナレッジグラフの構築における2つの工程に、大規模言語モデル(LLM)を活用してきました。
- LLMを使ったグラフデータモデリング
- LLMを使ってソースデータからグラフ構造を抽出し、PythonでCypher生成し、Neo4jへ登録
今回は、その次のステップとして、GraphRAGへ進むために不可欠な要素の一つであるNeo4j Vector Indexについてご紹介します。
既成のフレームワークを使えば、ソースデータからGraphRAGまで一気に構築できる──
そんなデモを見て、「これで十分では?」と思う方もいるかもしれません。
でも、ソースコードをよく見ると、あらかじめ想定されたエンティティや関係性がプロンプトに仕込まれていることが多いのです。
つまり、「データモデリング」の部分は、まだ人の判断に強く依存しています。
何を情報として捉えるか、どこをつなぐか。その設計は、今のLLMには難しい領域です。
現時点では、データモデリングの自動化には明確な限界があります。
もちろん、将来的にはLLM主体で完結する日が来るかもしれません。
ですが今はまだ、人が関わる余地は大きいと感じています。
GraphRAGとNeo4j Vector Index
GraphRAGの意義
大規模言語モデル(LLM)は、自然な文章を生成するのがとても得意です。
ですが、「なぜその答えになったのか?」という根拠を説明したり、事実ベースで正確に答えることは少し苦手なところがあります。そこで使われているのが RAG(Retrieval-Augmented Generation) という仕組みです。
これは、ユーザーの質問に対して「意味が近い文章を外部データから探して、その内容をLLMに提供して回答を作る方法です。ただ、RAG ではバラバラの文章断片を集めてくるだけなので、文脈がつながらなかったり、情報が断片的になることもあります。
そこで登場するのがGraphRAGです。
GraphRAG は、文章同士の意味だけでなく、情報同士の「つながり」や「構造」まで使って回答を作ることができます。具体的には、Embedding を使って似ているノード(情報)を見つけたあとに、そのノードがどんな情報と関係しているのかを、ナレッジグラフを使って広げていきます。
つまり GraphRAG は、
- 「似ている情報を探して終わり」ではなく、
- 「関連する情報を広げて、意味の通った・根拠のある回答を作る」ための仕組みです。
Neo4j Vector Index
Neo4j の Vector インデックスは、文章や画像などの「意味の近さ」をもとに似ているものを探すための仕組みです。たとえば、「ある単語や文に似た意味を持つ他の言葉を探す」といった、類似検索を実現できます。このインデックスは、「K近傍法」という考え方をもとにしており、あるデータに最も近い(=似ている)ものを K 件見つけることができます。
その中でも、Neo4j は「HNSW(Hierarchical Navigatable Small World:階層的ナビゲート可能スモールワールド)」という手法を使っていて、これは検索のスピードと正確さのバランスに優れたアルゴリズムです。たとえば、機械学習モデルで「記事の意味」を数値で表したベクトル(埋め込み)を使えば、「意味が近い別の記事」や「似た話題のノード」をグラフの中から探し出すことができます。
これは、Meta(Facebook)などが開発し、現在最も高性能なベクトル検索アルゴリズムの1つです。
Full-text Index と Vector Indexの違い
Full-text Index:「文字の一致」で探す
- 仕組み: 文章を単語に分解して、その単語で「完全一致」または「部分一致」を探す
- 記事: "GitLabでDevOpsを実践する方法"
- 検索: "GitLab" → ヒット(文字が一致)
- 検索: "DevOps" → ヒット(文字が一致)
- 検索: "CI/CD" → ヒットしない(文字が含まれていない)
- 特徴:
- 速い
- シンプル
- でも「意味」は理解しない
Vector Index:「意味の近さ」で探す
- 仕組み: 文章を数値の配列(ベクトル)に変換
- 数値の近さ = 意味の近さ
- 記事: "GitLabでDevOpsを実践する方法"
- ベクトル化: [0.2, 0.8, 0.3, 0.6, ...]
- 検索: "CI/CD パイプライン構築"
- ベクトル化: [0.22, 0.78, 0.32, 0.58, ...]
- ヒット!(数値が近い = 意味が似ている)
- 特徴:
- 単語が違っても意味が似ていれば見つかる
- より人間の感覚に近い検索
- 計算コストが高い
比較表
| 項目 | Full-text Index | Vector Index |
|---|---|---|
| 探し方 | 文字の一致 | 意味の近さ |
| 「GitLab」で「CI/CD」記事 | 見つからない | 見つかる |
| 速度 | 速い | やや遅い |
| 精度 | 完全一致のみ | 意味的類似性 |
| 用途 | キーワード検索 | 関連コンテンツ発見 |
Neo4j のベクトルと埋め込み(Embedding)
Vector Indexを使うと、文章や画像などの「意味の近さ」に基づいて、似たデータを検索することができます。たとえば「AIとは何か?」という文章と、「人工知能の仕組みについて」という文章が「意味的に似ている」と判断できるように、
文章や画像の特徴を数値(ベクトル)で表現するのが「埋め込み(embedding)」です。こうした埋め込みは、OpenAI や Google Vertex AI のようなサービスや、sentence-transformers のようなオープンソースツールで自動的に作れます。ベクトルの大きさ(次元数)は、256、768、1536などさまざまです。
Neo4jでは、このベクトル埋め込みをノードやリレーションシップの一部として保存できるため、「この文に似た内容のノードはどれか?」という検索が高速に実行できるようになります。
Vector Index(ベクトルインデックス)の位置づけと役割
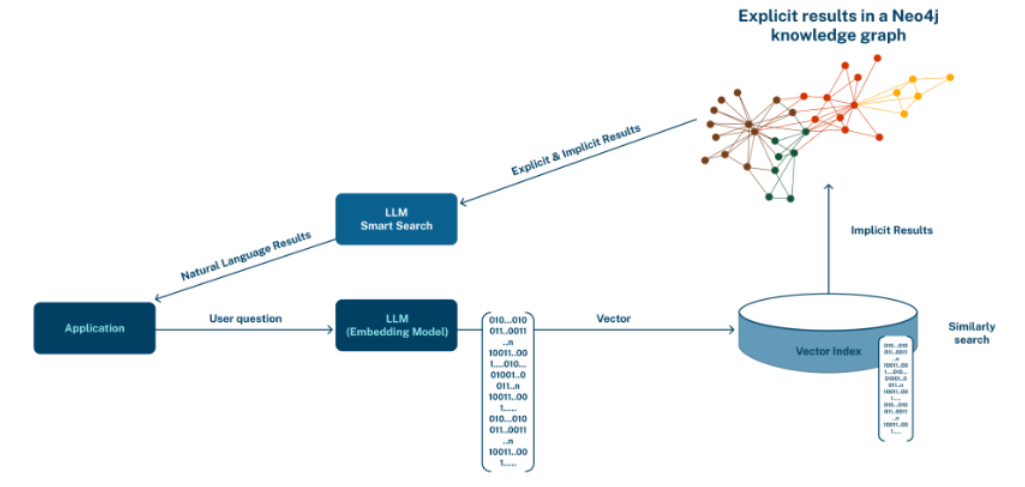
Vector Indexは、テキストや画像、ドキュメントなどを「意味」に基づいて検索するための仕組みです。GraphRAG では、このVector Indexが検索の「スタート地点」になります。
- ユーザーの質問をまず数値(ベクトル)に変換
- その数値に「意味が近い」ノード(情報)をVector Indexで見つける
- 見つけたノードを出発点にして、そのノードとつながっている関連情報を、知識グラフの構造を使ってたどっていく
この流れによって、「似ている情報」を拾うだけでなく、「どうつながっているか」という文脈も加えながら、より深く正確な答えを導き出せるようになります。
つまり、Vector Indexは「意味が近い情報を見つける入口」であり、GraphRAG はそこから知識の広がりをたどって答えを深めていく仕組みです。
Neo4j Vector Indexの作成方法
グラフファースト(Graph-First)
この方法では、まず既存のグラフにVector Indexを作成し、そのあとでアプリケーションを使って Embedding を実行します。
以下の例では、BlogPost エンティティと Keyword エンティティに対してVector Indexを宣言しています。ただし、通常のインデックスと異なり、この段階でベクトルが生成されるわけではありません。あくまでも、後からベクトルが入ることを前提とした空間を先に用意しておくだけです。
Vector Indexの作成
// BlogPost用のVector Index作成
CREATE VECTOR INDEX blog_post_embeddings
FOR (bp:BlogPost) ON bp.abstract_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1024,
`vector.similarity_function`: 'cosine'
}}
// Keyword用のVector Index作成
CREATE VECTOR INDEX keyword_embeddings
FOR (k:Keyword) ON k.word_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 384,
`vector.similarity_function`: 'cosine'
}}
SHOW INDEXES;
アプリケーションでEmbeddingを実行する例
前項では、Vector Indexの宣言は「ベクトルを格納するための空間を先に用意しておく」イメージだと説明しました。ここでは、実際にアプリケーションからベクトルを登録する方法について、サンプルコードを使って説明します。以下では、アプリケーション内の処理順に従って、2つの属性を読み込み、Embedding を実行している様子を追っていきます。
- BlogPost.abstract
- ①→②→③→④→⑤
- BlogPost.urlはノードを検索するためのキー
- BlogPost.abstractはEmbeddingのためのキー
- Keyword.word
- ①→⑥→⑦→④→⑧
- Keyword.wordは、ノード検索のためのキーであると同時にEmbeddingのためのキー
import json
import boto3
from dotenv import load_dotenv
import os
from neo4j import GraphDatabase
# 環境変数の読み込み
load_dotenv()
# AWS Bedrock初期化
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=os.getenv("AWS_REGION", "ap-northeast-1"),
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY")
)
# Neo4j初期化
neo4j_driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", os.getenv('NEO4J_PASSWORD'))
)
# ④Embeddingを実行
def generate_embedding(text, dimensions=None):
"""テキストからエンベディングを生成 (Titan Text Embeddings V2)"""
# 入力検証
if not text or not isinstance(text, str):
raise ValueError(f"Invalid text input: {repr(text)}")
# 空白のみの文字列をチェック
if not text.strip():
raise ValueError(f"Text is empty or whitespace only: {repr(text)}")
# リクエストボディ (シンプル版 - normalizeを削除)
body_dict = {"inputText": text}
# 次元数指定がある場合のみ追加
if dimensions:
body_dict["dimensions"] = dimensions
body = json.dumps(body_dict)
try:
response = bedrock_runtime.invoke_model(
modelId='amazon.titan-embed-text-v2:0',
body=body
)
response_body = json.loads(response['body'].read())
return response_body['embedding']
except Exception as e:
print(f"ERROR generating embedding for text: {text[:100]}...")
print(f"Dimensions: {dimensions}")
raise e
def add_embeddings_from_json(json_file_path):
"""JSONからデータを取得して既存グラフにエンベディングを追加"""
# ①グラフデータを読む
with open(json_file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
with neo4j_driver.session() as session:
# 1. BlogPostノードにエンベディング追加(1つのみ)
blog_post_node = next((node for node in data['nodes'] if 'BlogPost' in node['labels']), None)
if blog_post_node:
# ②url(検索キー)とabstract(Embedding対象)を抽出
url = blog_post_node['properties']['url']
abstract = blog_post_node['properties'].get('abstract')
if abstract:
# ③Embeddingを依頼 (デフォルト次元数を使用)
embedding = generate_embedding(abstract)
# ⑤urlでノードを検索してabstract_embedding属性を追加
session.run("""
MATCH (bp:BlogPost {url: $url})
SET bp.abstract_embedding = $embedding
""", url=url, embedding=embedding)
print(f"✓ BlogPost エンベディング追加: {blog_post_node['properties']['title']}")
# 2. 全てのKeywordノードにエンベディング追加(複数のために)
# ⑥各Keywordノードを処理
for node in data['nodes']:
if 'Keyword' in node['labels']:
word = node['properties']['word']
# ⑦Embeddingを依頼 (デフォルト次元数を使用)
embedding = generate_embedding(word)
# ⑧ワードで検索し、word_embedding属性を追加
session.run("""
MATCH (k:Keyword {word: $word})
SET k.word_embedding = $embedding
""", word=word, embedding=embedding)
print(f"✓ Keyword エンベディング追加: {word}")
# メイン処理
if __name__ == "__main__":
# JSONから取得して既存グラフにエンベディング追加
add_embeddings_from_json('../graph_extract/tech-blog_agile-devops_76256_graph.json')
# クリーンアップ
neo4j_driver.close()
print("\nJSONから取得したデータで既存グラフへのエンベディング追加が完了しました!")
https://github.com/awk256/neo4j-lab-semantic-model$ python vector_index_set_with_aws.py
✓ BlogPost エンベディング追加: 【Agile Kata Series】Part 1 : アジャイルのカタの概要
✓ Keyword エンベディング追加: アジャイルのカタ
✓ Keyword エンベディング追加: 改善のカタ
✓ Keyword エンベディング追加: コーチングのカタ
✓ Keyword エンベディング追加: トヨタのカタ
✓ Keyword エンベディング追加: レトロスペクティブ
✓ Keyword エンベディング追加: スクラム
✓ Keyword エンベディング追加: カンバン
✓ Keyword エンベディング追加: EBM
✓ Keyword エンベディング追加: アジャイルマインドセット
✓ Keyword エンベディング追加: 価値に基づく計測
JSONから取得したデータで既存グラフへのエンベディング追加が完了しました!この処理では、あらかじめ存在しているグラフに対して、あとからVector Indexを追加しています。ただし、このアプローチではソースデータの存在が前提となるため、ソースデータが残っていない場合は既存のグラフをエクスポートするなど、別の方法を取る必要があります。
ベクトルファースト(Vector-First)
この方法では、最初から埋め込み(Embedding)を含めてノードを作成します。
グラフデータベースの設計段階からGraphRAG の活用を想定しており、検索に使う項目が予測できる場合には、このアプローチがより効果的かも知れません。
Vector Indexの作成
// BlogPost用のVector Index作成
CREATE VECTOR INDEX blog_post_embeddings
FOR (bp:BlogPost) ON bp.abstract_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1024,
`vector.similarity_function`: 'cosine'
}}
// Keyword用のVector Index作成
CREATE VECTOR INDEX keyword_embeddings
FOR (k:Keyword) ON k.word_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 384,
`vector.similarity_function`: 'cosine'
}}
SHOW INDEXES;アプリケーションでEmbeddingを実行する例
ベクトルファーストのアプローチでも、基本的な実装の流れはグラフファーストとほとんど同じです。
アプリケーション側で Embedding を実行し、そのベクトル情報を含めて Cypher でノードを作成します。
違いはシンプルで、ノード作成の時点で Embedding を実行しておくかどうかという点だけです。
# BlogPostのEmbeddingを含めてノード作成
session.run("""
CREATE (bp:BlogPost {
title: $title,
url: $url,
abstract: $abstract,
published_date: date($published_date),
abstract_embedding: $embedding
})
""",
title=props['title'],
url=props['url'],
abstract=abstract,
published_date=props.get('published_date'),
embedding=abstract_embedding
)
# KeywordのEmbeddingを含めてノード作成
session.run("""
CREATE (k:Keyword {
word: $word,
normalized: $normalized,
type: $type,
domain: $domain,
word_embedding: $embedding
})
""",
word=word,
normalized=props.get('normalized'),
type=props.get('type'),
domain=props.get('domain'),
embedding=word_embedding
)
[グラフファスト vs ベクトルファースト]
グラフファーストとベクトルファーストのどちらを選ぶべきかは、状況に応じて柔軟に判断することが大切です。必ずこちらを選ぶべき、という決まったルールはありません。実際には、両者を併用するケースも想定されますが、そもそもこの分野はまだ新しく、具体的な運用事例が多くはないのが現状です。だからこそ、自分たちのユースケースに合ったやり方を試しながら探っていく姿勢が求められます。
TIPs
ここでは、Vector Index を実装・運用する際に役立つポイントや注意点を、豆知識としていくつか紹介しています。
「これ、最初に知っておきたかった…」という内容もあるかもしれません。
Embedding の次元数(vector.dimensions)はどう決める?
-- vector.dimensions: エンベディングベクトルの次元数
CREATE VECTOR INDEX test_index FOR (n:Node) ON n.embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1024, -- この値の意味と制限
`vector.similarity_function`: 'cosine'
}}Embedding の次元数(vector.dimensions)は、どのように決めればいいのでしょうか?
実は、この数値は 使用する Embedding モデルによって基本的に決まっています。固定の次元数のモデルもあれば、256・512・1024など複数のサイズを選べるモデルもあります。
たとえば、今回の概念検証で使用している Amazon Titan Text Embeddings V2 は、次元数として 256・512・1024(デフォルト) から選択可能です。
また、作成した Vector Index の次元数は、あとから変更できません。もちろん、あとから作り直すという選択肢もありますが、再構築には手間がかかるため、用途を見据えて最初に決めておくのがおすすめです。
高次元 or 中次元 or 低次元、どう選ぶ
Neo4j 自体は、特定の LLM プロバイダーや Embedding モデルに制限を設けていません。
つまり、Azure OpenAI、OpenAI、Vertex AI、Amazon Bedrock、Cohere、Hugging Face など、好きなプロバイダーの多様なモデルを自由に使えます。
ただし、選んだモデルによって生成される「ベクトルの次元数」が変わります。
この次元数が、検索の精度・処理のコスト・メモリ使用量などに大きく影響するため、用途に応じて適切な次元数を選ぶことが大切です。
- 高次元モデル(1024〜)
- 文脈理解力が高く、長文にも対応しやすい
- 質の高い検索結果が得られる可能性がある
- ただし、メモリ使用量や処理コストが高め
- 向いている用途:
- ブログ記事やレポートの全文検索
- 複数トピックを含む長文への応答生成
- 中次元モデル(512〜)
- 表現力とコストのバランスが良い
- 多くのユースケースに対応できる汎用型
- 高度すぎる処理も、簡素すぎる表現も避けたい場合に最適
- 向いている用途:
- 技術ドキュメントやFAQ検索
- タグ・カテゴリベースの類似文書検索
- 低次元モデル(256〜)
- 処理が高速で軽量、リソース負荷が少ない
- 短いテキスト・単語ベースの検索で効果的
- 向いている用途:
- 技術用語やプロダクト名の類似検索
- タグやエンティティの識別
ただし、Neo4j には次元数の制限があるので注意してください。
- Minimum:1
- Maximum:2048
- Neo4j 5.x の制限
Vector Index構築時の注意点
Embedding モデルや次元数を選ぶ際は、以下の点に注意が必要です。
- 同じノード × 同じ 属性のVector Index
- 必ず同じ Embedding モデルを使用してください。
- モデルを変えると次元数が異なる可能性があり、データの整合性が崩れます。
- 属性が異なる場合は、異なるEmbeddingモデルでも大丈夫です。
- 次元サイズは、Embedding モデルに合わせた既定のサイズを使用
- 独自に変更することはできません。
- Vector Index 作成後は、次元数の変更はできません
- インデックスを作り直す必要があります。
- メモリ使用量は次元数に比例して増加します
- 不要に大きな次元を選ばないよう、用途に合ったサイズを選定しましょう。
類似度関数(vector.similarity_functionの種類と用度
Neo4j の Vector Index では、以下の 2 種類の類似度関数が使えます。
| 名称 | 特徴 | 適用例 |
| コサイン類似度(cosine) | ベクトルの「向き」が近いかどうかに着目するため、テキストの意味的な近さを測る用途に向いています。 一般的なテキスト検索ではこちらが推奨されます。 | 文書類似度検索 意味的類似性判定 レコメンドシステム |
| ユークリッド距離(euclidean) | 数値の大きさも含めて「どれだけ近いか」を評価します。 センサー値や数値系列など、物理的な距離を重視したいケースに向いています。 | 画像類似度検索 音声認識 異常検知 |
Vector Indexに複合インデックスが使えますか。
いいえ。Vector Index に複合インデックスは存在しません。
複数ベクトルの組み合わせによる検索は、数学的に定義が難しく、現在はサポートされていません。
同エンティティ(ラベル)に複数のVectorインデックスが作られますか。
はい。同じエンティティ(ラベル)に対して、複数の Vector Index を作成することは可能です。
たとえば、以下のように 2種類の異なるベクトル属性に対して、それぞれインデックスを作成して運用できます。
// 1. BlogPostのabstract用Vector Index
CREATE VECTOR INDEX blog_post_abstract_embeddings
FOR (bp:BlogPost) ON bp.abstract_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1024,
`vector.similarity_function`: 'cosine'
}}
// 2. BlogPostのtitle用Vector Index
CREATE VECTOR INDEX blog_post_title_embeddings
FOR (bp:BlogPost) ON bp.title_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 512,
`vector.similarity_function`: 'cosine'
}}属性別のVector Indexの判断基準がありますか
一般的に、意味を求める検索対象となる各属性ごとにVector Indexを作成することで、自然言語での意味検索やテキストの類似性検索、ユーザーの検索クエリやレコメンデーションの対象など、さまざまな用途に応じた柔軟かつ高精度な検索を実現します。
- title_embedding: [...]
- タイトル検索用
- content_embedding: [...]
- 全文検索用
- abstract_embedding: [...]
- 概要検索用
Vector Indexの対象にならないケースは、完全一致検索や範囲検索、関係による取得、数値比較、管理用メタデータ、バージョン管理などの項目であり、具体的には以下のようなものがあります。
- id: "doc_001"
- 完全一致検索
- created_date: "2025-01-01"
- 範囲検索
- author_id: "user_123"
- 関係で取得
- word_count: 1500
- 数値比較
- file_path: "/docs/file.txt"
- 管理用メタデータ
- version: 1.2
- バージョン管理
まとめ
今回は、「大規模言語モデルによるナレッジグラフ自動化の概念検証」の流れの中で、GraphRAG へ進む前に不可欠な要素のひとつである Neo4j Vector Index についてご紹介しました。
具体的には、
- 既存のグラフにVector Indexを追加する方法
- グラフ作成と同時にVector Indexを作成する方法
この2つのアプローチと、それぞれにおける注意点や実装上のポイントについても触れました。
次回は、今回作成したNeo4j Vector Index をサンプルグラフ全体に適用し、基本的な検索パターンを試しながら、GraphRAG への足がかりを築いていきます。
お楽しみに。
🧭連載
- 全工程を LLM のコンソール上で完結
- LLM とコード処理を分離し、役割を明確化
- GraphRAGへの道とNeo4j Vector Index
- 自然言語で探索する GraphRAG 検索の実践
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



