
大規模言語モデルによるナレッジグラフ自動化の概念検証[4]
ー 自然言語で探索する GraphRAG 検索の実践 ー
はじめに
この連載では、大規模言語モデル(LLM)を活用しながら、ナレッジグラフを自動生成・構築するための概念検証を進めてきました。もちろん、LLM活用のポイントを探っていたのであって、本気に自動化しようと考えていたわけではありません。そこで、
- セマンティックモデルを定義し、
- ブログ記事からエンティティ・リレーションを抽出し、
- Neo4j を使ってナレッジグラフを構築しました
そして今回は、GraphRAG の「入口」となるVector Indexを50本のサンプルグラフに導入し、ナレッジグラフを完成した上で、自然言語による意味検索(semantic search)を実際にコードで試してみます。
グラフファーストのVector Index作成
ここでは、前回までに作成したナレッジグラフ(graph_extract/*.json に格納された 50 本分の Tech Blog データ)を使って、既存グラフに対して Vector Index を追加し、Embedding を付与する処理を実行していきます。
すでにノードとリレーションシップが定義された状態(=グラフファースト)から、意味検索ができるように整備する手順を、Python コードを交えながら紹介していきます。
50本のグラフデータからVector Indexを実装
import json
import boto3
from dotenv import load_dotenv
import os
from neo4j import GraphDatabase
import glob
# 環境変数の読み込み
load_dotenv()
# AWS Bedrock初期化
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=os.getenv("AWS_REGION", "ap-northeast-1"),
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY")
)
# Neo4j初期化
neo4j_driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", os.getenv('NEO4J_PASSWORD'))
)
def generate_embedding(text, dimensions=None):
"""テキストからエンベディングを生成 (Titan Text Embeddings V2)"""
# 入力検証
if not text or not isinstance(text, str):
raise ValueError(f"Invalid text input: {repr(text)}")
# 空白のみの文字列をチェック
if not text.strip():
raise ValueError(f"Text is empty or whitespace only: {repr(text)}")
# リクエストボディ (シンプル版 - normalizeを削除)
body_dict = {"inputText": text}
# 次元数指定がある場合のみ追加
if dimensions:
body_dict["dimensions"] = dimensions
body = json.dumps(body_dict)
try:
response = bedrock_runtime.invoke_model(
modelId='amazon.titan-embed-text-v2:0',
body=body
)
response_body = json.loads(response['body'].read())
return response_body['embedding']
except Exception as e:
print(f"ERROR generating embedding for text: {text[:100]}...")
print(f"Dimensions: {dimensions}")
raise e
def add_embeddings_from_json(json_file_path):
"""JSONからデータを取得して既存グラフにエンベディングを追加"""
try:
# グラフデータを読む
with open(json_file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
with neo4j_driver.session() as session:
# 1. BlogPostノードにエンベディング追加(1つのみ)
blog_post_node = next((node for node in data['nodes'] if 'BlogPost' in node['labels']), None)
if blog_post_node:
# url(検索キー)とabstract(Embedding対象)を抽出
url = blog_post_node['properties']['url']
abstract = blog_post_node['properties'].get('abstract')
if abstract:
# Embeddingを依頼 (デフォルト次元数を使用)
embedding = generate_embedding(abstract)
# urlでノードを検索してabstract_embedding属性を追加
session.run("""
MATCH (bp:BlogPost {url: $url})
SET bp.abstract_embedding = $embedding
""", url=url, embedding=embedding)
print(f"✓ BlogPost エンベディング追加: {blog_post_node['properties']['title']}")
# 2. 全てのKeywordノードにエンベディング追加(複数のために)
# 各Keywordノードを処理
for node in data['nodes']:
if 'Keyword' in node['labels']:
word = node['properties']['word']
# Embeddingを依頼 (デフォルト次元数を使用)
embedding = generate_embedding(word)
# ワードで検索し、word_embedding属性を追加
session.run("""
MATCH (k:Keyword {word: $word})
SET k.word_embedding = $embedding
""", word=word, embedding=embedding)
return True
except Exception as e:
print(f"✗ エラー: {json_file_path} - {str(e)}")
return False
def process_multiple_files(file_pattern):
"""複数のJSONファイルを処理"""
# ワイルドカードでファイルを取得
json_files = glob.glob(file_pattern)
if not json_files:
print(f"警告: パターン '{file_pattern}' に一致するファイルが見つかりません")
return
print(f"\n{len(json_files)} 個のファイルを処理します\n")
success_count = 0
fail_count = 0
for idx, json_file in enumerate(json_files, 1):
print(f"[{idx}/{len(json_files)}] 処理中: {os.path.basename(json_file)}")
if add_embeddings_from_json(json_file):
success_count += 1
else:
fail_count += 1
print() # 空行
# サマリー表示
print("=" * 50)
print(f"処理完了: 成功 {success_count} / 失敗 {fail_count} / 合計 {len(json_files)}")
print("=" * 50)
# メイン処理
if __name__ == "__main__":
# 複数JSONファイルから取得して既存グラフにエンベディング追加
process_multiple_files('../graph_extract/*.json')
# クリーンアップ
neo4j_driver.close()
print("\nすべてのファイルの処理が完了しました!")
https://github.com/awk256/neo4j-lab-semantic-model
結果は、次のとおりです。50本のブログ記事すべてに対して、Embedding を追加し、Vector Index を活用できる状態になりました。
- BlogPost.abstracty(要旨)
- Keyword.word
$ python vector_index_set_with_aws_all.py
50 個のファイルを処理します
[1/50] 処理中: tech-blog_chatgpt-ai_ai_69246_graph.json
✓ BlogPost エンベディング追加: 【AI駆動開発】ChatGPTはもう古い?Phind(フィンド)に乗り換えてみる!
[2/50] 処理中: tech-blog_cloudnative_chef_23515_graph.json
✓ BlogPost エンベディング追加: [和訳] Chef Workstationの正規版リリースのお知らせ #getchef #chef
...中略...
[50/50] 処理中: tech-blog_others_kaizen_70055_graph.json
✓ BlogPost エンベディング追加: ワークショップ支援サービス導入事例(株式会社MonotaRO様)を発表:急成長企業の共通目的形成への貢献、参加者からは高い実感と価値の声
==================================================
処理完了: 成功 50 / 失敗 0 / 合計 50
==================================================
すべてのファイルの処理が完了しました!
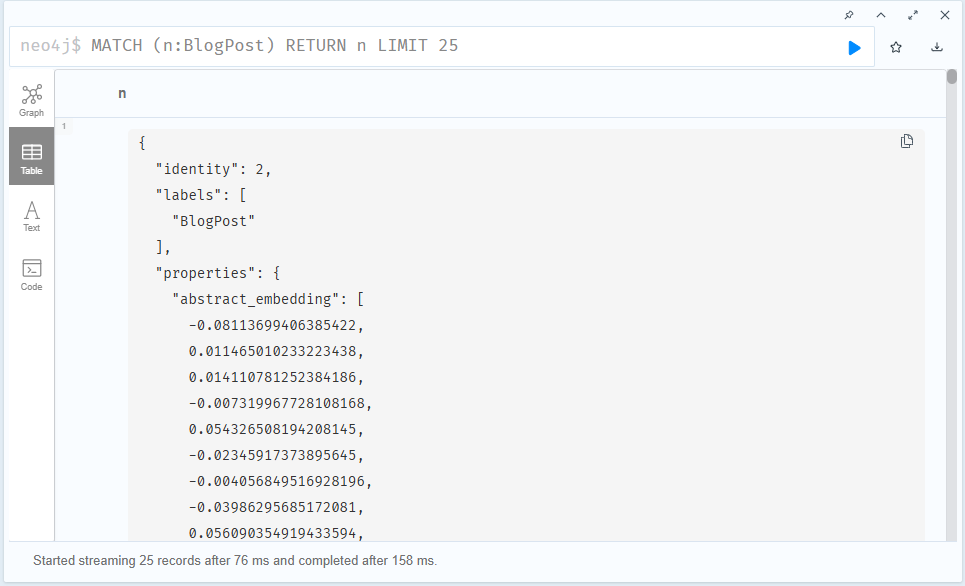
興味のある方は、実際にノードに追加されたベクトル(Embedding)を確認してみてください。
MATCH (n:BlogPost) RETURN n LIMIT 25表示されたノードの中から任意の BlogPost ノードを選び、上の [Table] ボタンをクリックすると、properties.abstract_embedding プロパティとして、非常に長い数値のリスト(ベクトル)が付与されているのが確認できるはずです。
これは、LLM によって生成された意味ベクトル(埋め込み)がノードに格納されていることを示しています。
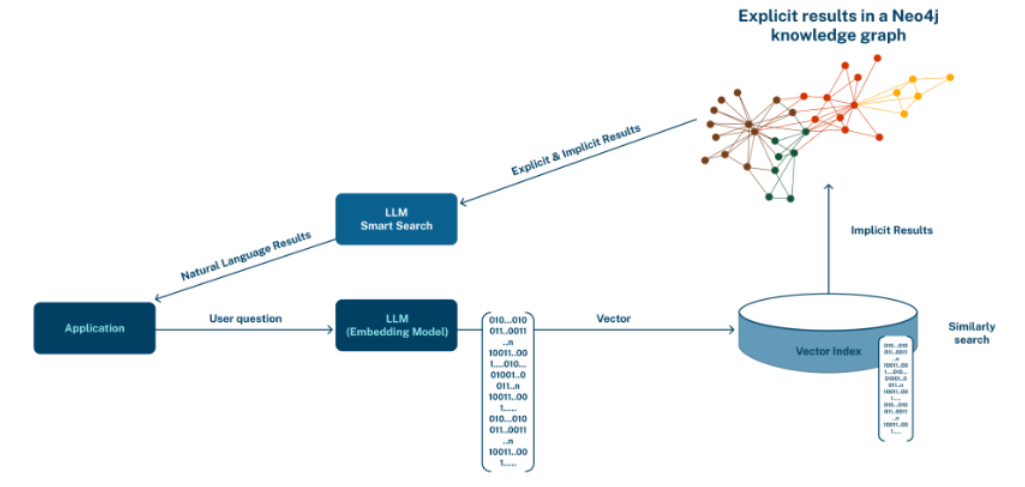
自然言語でナレッジグラフを検索する
自然言語から Cypher へ:LLM を活用したグラフ検索の入り口
ベクトル化されたデータは、自然言語で検索できます。
イメージとしては「◯◯のような情報が知りたい」といったざっくりとした問いを自然言語で投げると、アプリケーションがそれを「意味ベクトル(Embedding)」に変換し、Neo4j の Vector Index を使って、最も意味が近いノードを探し出してくれます。
ここではその仕組みを実際の Cypher クエリのスニペットを使って解説し、コードでベクトル検索をどのように実装できるのかを紹介していきます。
result = session.run("""
CALL db.index.vector.queryNodes('blog_post_embeddings', $top_k, $query_embedding)
YIELD node, score
RETURN node.title AS title,
node.abstract AS abstract,
node.url AS url,
score
ORDER BY score DESC
""", query_embedding=query_embedding, top_k=top_k)| CALL db.index.vector.queryNodes | Neo4j内臓のプロシージャ |
| blog_post_embeddings | Vector Index名 |
| $top_k | 検索するノードの件数。類似度のトップ何件を抽出するか、数字を設定(例:top_k=3) |
| $query_embedding | 自然言語の質問をベクトル化している変数 |
| YIELD node | プロシージャの返還値の識別子 →node.<属性名>のように使用 |
| score | 類似度のスコア(数字) |
シンプルなノード検索の例
自然言語でノードを検索するには、まず質問文をEmbeddingする必要があります。
ただし、Neo4j 自体にはテキストをベクトルに変換する機能はないため、外部の LLM/Embedding API と連携し、アプリケーション側で処理を行う必要があります。
ここでは、次のような簡単な問いかけを例に、自然言語検索の基本的な流れを紹介します:
自然言語によるノード検索の例
import json
import boto3
from dotenv import load_dotenv
import os
from neo4j import GraphDatabase
# 環境変数の読み込み
load_dotenv()
# AWS Bedrock初期化
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=os.getenv("AWS_REGION", "ap-northeast-1"),
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY")
)
# Neo4j初期化
neo4j_driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", os.getenv('NEO4J_PASSWORD'))
)
def generate_embedding(text):
"""テキストからエンベディングを生成"""
body = json.dumps({"inputText": text})
response = bedrock_runtime.invoke_model(
modelId='amazon.titan-embed-text-v2:0',
body=body
)
response_body = json.loads(response['body'].read())
return response_body['embedding']
def vector_search(query_text, top_k=3):
"""Vector検索を実行"""
# 検索クエリのエンベディングを生成
query_embedding = generate_embedding(query_text)
with neo4j_driver.session() as session:
# Vector検索クエリ
result = session.run("""
CALL db.index.vector.queryNodes('blog_post_embeddings', $top_k, $query_embedding)
YIELD node, score
RETURN node.title AS title,
node.abstract AS abstract,
node.url AS url,
score
ORDER BY score DESC
""", query_embedding=query_embedding, top_k=top_k)
return list(result)
# メイン処理
if __name__ == "__main__":
# 検索実行
query = "Neo4jの新機能について紹介しているブログは"
print(f"検索クエリ: {query}\n")
print("=" * 80)
results = vector_search(query, top_k=3)
# 結果表示
for idx, record in enumerate(results, 1):
print(f"\n【結果 {idx}】(類似度スコア: {record['score']:.4f})")
print(f"タイトル: {record['title']}")
print(f"URL: {record['url']}")
print(f"\nAbstract:")
print(record['abstract'])
print("-" * 80)
# クリーンアップ
neo4j_driver.close()
print(f"\n検索完了: {len(results)} 件の結果")https://github.com/awk256/neo4j-lab-semantic-model
以下は、自然言語検索による結果です。
今回は「Neo4j」「MongoDB」「GKE」「NASAのナレッジグラフ再現」といったトピックを扱った記事がヒットしました。
実際の運用では、質問の表現を変えたり、条件を詳しく指定したりといった工夫が、より正確な検索結果を得るために重要になってくるでしょう。
$ python vector_search_simple.py
検索クエリ: Neo4jの新機能について紹介しているブログは
================================================================================
【結果 1】(類似度スコア: 0.6577)
タイトル: MongoDB のデータを Neo4j で可視化してみる #Neo4j #MongoDB #Graph
URL: https://www.creationline.com/tech-blog/data-management/mongodb/54340
Abstract:
MongoDB のデータを Neo4j で可視化する連携を試し、JSON ドキュメントのテキストをグラフ理論によってグラフ化することで、データの表す意味を人間が直感的に理解できるようにする方法を解説
--------------------------------------------------------------------------------
【結果 2】(類似度スコア: 0.6566)
タイトル: Kubernetes(GKE)上にNeo4jをデプロイする #Neo4j #Kubernetes
URL: https://www.creationline.com/tech-blog/data-management/neo4j/52328
Abstract:
Kubernetes上にNeo4jをデプロイする方法を公式ドキュメントの手順に沿って試した記録。GKEを使用してHelmチャートでNeo4jスタンドアローンをデプロイし、スケーリングやオートヒーリング機能による可用性向上のメリットを解説。
--------------------------------------------------------------------------------
【結果 3】(類似度スコア: 0.6549)
タイトル: Neo4jでNASAのナレッジグラフを再現してみた #neo4j #graph #nosql
URL: https://www.creationline.com/tech-blog/hr/31338
Abstract:
弊社の李・朱・細見が社内PoCとして「Neo4jを利用してNASAのナレッジグラフを再現してみた」プロセスについて紹介。AIによるナレッジグラフの自動生成及びナレッジのレコメンド、Cypherによるナレッジ検索エンジン開発のためのPoCを実施し、MVPレベルでのNASAのナレッジグラフの再現に成功した。
--------------------------------------------------------------------------------
検索完了: 3 件の結果結果として、上記のような3件の記事が抽出されました。
期待した記事との類似度の評価には主観が入るため、厳密なコメントは難しいところですが、質問の表現を変えたり工夫しながら探索していく面白さは十分に感じられます。
特に今回は、対象となる記事が約50件と限られていることを考えると、かなり納得感のある結果になっていると思います。
ノード間の関係をたどる探索
グラフ検索の醍醐味は、何よりも、トラバーサルではないでしょうか。ノードを見つけてから、そのノードを起点にして関係性を持つ情報を引き出すことができます。
BlogPost-[CONTAIN_KEYWORD]->Keyword以下のCyhperを見てください。自然言語で検索したノードに対して関係性を持つノードを探索しています。
CALL db.index.vector.queryNodes('blog_post_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node)-[:CONTAINS_KEYWORD]->(k:Keyword)
RETURN node.title AS title,
node.abstract AS abstract,
node.url AS url,
collect(k.word) AS keyword,
score
ORDER BY score DESC| YIELD node | 自然言語で検索して結果値の識別子 |
| MATCH (node)-[:CONTAINS_KEYWORD]->(k:Keyword) | 自然言語による検索結果値(node)を起点にしてリレーションシップ(CONTAINS_KEYWORD)を検索 |
| collect(k.word) | collectは複数の値をリストにします。 →["A","B","C","D"] |
ノード間の関係をたどる探索の例
import json
import boto3
from dotenv import load_dotenv
import os
from neo4j import GraphDatabase
# 環境変数の読み込み
load_dotenv()
# AWS Bedrock初期化
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=os.getenv("AWS_REGION", "ap-northeast-1"),
aws_access_key_id=os.getenv("AWS_ACCESS_KEY_ID"),
aws_secret_access_key=os.getenv("AWS_SECRET_ACCESS_KEY")
)
# Neo4j初期化
neo4j_driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", os.getenv('NEO4J_PASSWORD'))
)
def generate_embedding(text):
"""テキストからエンベディングを生成"""
body = json.dumps({"inputText": text})
response = bedrock_runtime.invoke_model(
modelId='amazon.titan-embed-text-v2:0',
body=body
)
response_body = json.loads(response['body'].read())
return response_body['embedding']
def vector_search(query_text, top_k=3):
"""Vector検索を実行"""
# 検索クエリのエンベディングを生成
query_embedding = generate_embedding(query_text)
with neo4j_driver.session() as session:
# Vector検索クエリ
result = session.run("""
CALL db.index.vector.queryNodes('blog_post_embeddings', $top_k, $query_embedding)
YIELD node, score
MATCH (node)-[:CONTAINS_KEYWORD]->(k:Keyword)
RETURN node.title AS title,
node.abstract AS abstract,
node.url AS url,
collect(k.word) AS keyword,
score
ORDER BY score DESC
""", query_embedding=query_embedding, top_k=top_k)
return list(result)
# メイン処理
if __name__ == "__main__":
# 検索実行
query = "Neo4jの新機能について紹介しているブログは"
print(f"検索クエリ: {query}\n")
print("=" * 80)
results = vector_search(query, top_k=3)
# 結果表示
for idx, record in enumerate(results, 1):
print(f"\n【結果 {idx}】(類似度スコア: {record['score']:.4f})")
print(f"タイトル: {record['title']}")
print(f"URL: {record['url']}")
print(f"\nAbstract:")
print(record['abstract'])
print(f"\nキーワード:")
print(record['keyword'])
print("-" * 80)
# クリーンアップ
neo4j_driver.close()
print(f"\n検索完了: {len(results)} 件の結果")https://github.com/awk256/neo4j-lab-semantic-model
以下の結果をご覧ください。
ブログの要旨に加えて、関連するキーワードとの関係性もたどっているため、より特徴が際立つ情報になっています。
python vector_search_traversal.py
検索クエリ: Neo4jの新機能について紹介しているブログは
================================================================================
【結果 1】(類似度スコア: 0.6577)
タイトル: MongoDB のデータを Neo4j で可視化してみる #Neo4j #MongoDB #Graph
URL: https://www.creationline.com/tech-blog/data-management/mongodb/54340
Abstract:
MongoDB のデータを Neo4j で可視化する連携を試し、JSON ドキュメントのテキストをグラフ理論によってグラフ化することで、データの表す意味を人間が直感的に理解できるようにする方法を解説
キーワード:
['JSON', 'データ可視化', 'Docker', 'APOC', 'NoSQL', 'グラフデータベース', 'Neo4j', 'MongoDB']
--------------------------------------------------------------------------------
【結果 2】(類似度スコア: 0.6566)
タイトル: Kubernetes(GKE)上にNeo4jをデプロイする #Neo4j #Kubernetes
URL: https://www.creationline.com/tech-blog/data-management/neo4j/52328
Abstract:
Kubernetes上にNeo4jをデプロイする方法を公式ドキュメントの手順に沿って試した記録。GKEを使用してHelmチャートでNeo4jスタンドアローンをデプロイし、スケーリングやオートヒーリング機能による可用性向上のメリットを解説。
キーワード:
['StatefulSet', 'Persistent Volume', 'オートヒーリング', 'スケーリング', 'Helm', 'GKE', 'Neo4j', 'Kubernetes']
--------------------------------------------------------------------------------
【結果 3】(類似度スコア: 0.6549)
タイトル: Neo4jでNASAのナレッジグラフを再現してみた #neo4j #graph #nosql
URL: https://www.creationline.com/tech-blog/hr/31338
Abstract:
弊社の李・朱・細見が社内PoCとして「Neo4jを利用してNASAのナレッジグラフを再現してみた」プロセスについて紹介。AIによるナレッジグラフの自動生成及びナレッジのレコメンド、Cypherによるナレッジ検索エンジン開発のためのPoCを実施し、MVPレベルでのNASAのナレッジグラフの再現に成功した。
キーワード:
['PoC', 'レコメンドシステム', 'RDF', 'オントロジー', '自然言語処理', '機械学習', 'グラフデータベース', 'Cypher', 'Neo4j', 'ナレッジグラフ']
--------------------------------------------------------------------------------
検索完了: 3 件の結果まとめ
今回は、自然言語の質問からナレッジグラフを探索し、意味的に近いブログ記事を検索してみました。
さらに、そこから関係性をたどって関連キーワードを抽出することで、GraphRAGが持つ文脈拡張の力も体験していただけたかと思います。
これで、LLM を活用してナレッジグラフを自動構築し、検索・活用までをつなげていく一連の流れ――
すなわち、「ナレッジグラフ自動化の概念検証」という当初の目的は、ひとまず達成できたのではないかと感じています。
実際にコードを試してみようとした方の中には、環境構築の壁にぶつかった方もいたかもしれません。
しかし、連載ではコードや実行結果も紹介してきたので、特別なフレームワークがなくてもGraphRAGは簡単に実装できるということ、そして、GraphRAGの考え方が決して遠い世界の話ではないということが、少しでも伝わっていれば幸いです。
なお、自然言語の質問から Cypher を生成するといったさらなる発展的なトピックについては、また別の機会に扱ってみたいと考えています。
ここまでお読みいただいた皆さま、本当にありがとうございました。
🧭連載
- 全工程を LLM のコンソール上で完結
- LLM とコード処理を分離し、役割を明確化
- GraphRAGへの道とNeo4j Vector Index
- 自然言語で探索する GraphRAG 検索の実践
Author
モダンアーキテクチャー基盤のソリューションアーキテクトとして活動しています。
[著書]
・Amazon Cloudテクニカルガイド―EC2/S3からVPCまで徹底解析
・Amazon Elastic MapReduceテクニカルガイド ―クラウド型Hadoopで実現する大規模分散処理
・Cypherクエリー言語の事例で学ぶグラフデータベースNeo4j
・Neo4jを使うグラフ型データベース入門(共著)
・RDB技術者のためのNoSQLガイド(共著)



