
GitLab Orbit — AIエージェントの「コンテキストの壁」と、その根本解決
GitLabのKnowledge Graphサービス「Orbit」のプロジェクトを、GitLab DuoのPlanner Agentを使って分析しました。その結果を元に、アーキテクチャー、技術背景、そして開発の計画と進捗を紹介します。

GitLab Transcend 2026 が、6月10日にロンドンで開催され、日本を含む世界中に配信されました。そこでは、3つの大きな技術革新が発表されました。
- 次世代ソースコード管理(プライベートベータ)
リポジトリ全体をクローンする従来の方法に代わり、構造化されたAPI経由で必要な情報のみをサーバーサイドで取得します。これにより、AIエージェントのタスク実行速度が最大50倍に向上します。 - GitLab Orbit(パブリックベータ)
ソフトウェアライフサイクル全体(コード、作業項目、パイプライン、デプロイ、運用シグナル)をマッピングする「コンテキストグラフ」です。AIエージェントが共通の信頼できる情報源を参照することで、応答速度が最大11倍に向上し、トークン消費量を最大4.5倍削減、ハルシネーション(誤情報)も最大45倍低減できるとされています。 - AIエージェント向けガバナンス(プライベートベータ)
AIエージェントのアクションに対するアイデンティティ管理、ポリシー設定、監査、承認プロセスを提供します。これにより、コンプライアンス要件を満たしながら、リアルタイムでエージェントの活動を監視・制御可能にします。
前回の次世代ソースコード管理 (Next Gen SCM) に続き、本稿では、このうちのGItLab Orbit (a.k.a. GitLab Knowledge Graph) を取り上げます。
AIエージェントが「見えていない」とき、何が起きているのか
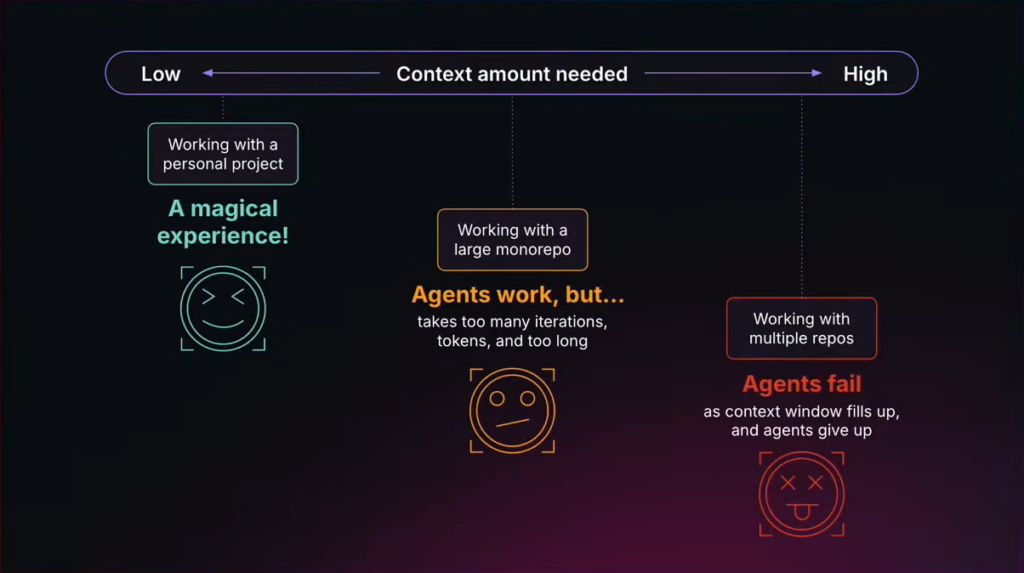
AIコーディングエージェントを使っていると、特定のパターンで不完全な回答が返ってくることに気づきます。
- 「このメソッドをリネームしたい」→ AIが変更箇所を列挙したが、別リポジトリの呼び出し元が漏れていた
- 「このサービスに手を入れても安全か」→ AIが「問題ない」と答えたが、3つ先のマイクロサービスが依存していた
- 「このMRのレビュアーを誰にすべきか」→ AIがコミット履歴から推測したが、実際のオーナーは別のチームだった
これはハルシネーション(モデルが存在しない事実を生成する現象)とは別の問題です。モデルは正常に動いています。ただ、コンテキストに含まれていない情報は、モデルにとっては存在しないも同然です。見えていないものは答えられない。見えていないことすら、モデルには分かりません。
そのとき何が起きるか。モデルは手持ちの情報から確率的に補完します。それがたまたま正しいこともありますが、保証はありません。ハルシネーションと紙一重の状態です。
なぜ「見えない」のか ── 複数APIの連鎖という限界
では、正しい答えを出すために必要な情報はどこにあるのか。GitLabの中に、すべてあります。コードの依存関係、MRとIssueのつながり、パイプラインの成否、誰がどのコードを書いてきたか ── これらはGitLabのデータとして存在しています。
問題は、それを推論に使える形でAIに渡す手段がなかったことです。
GitLabのデータは、本質的にグラフ構造を持っています。
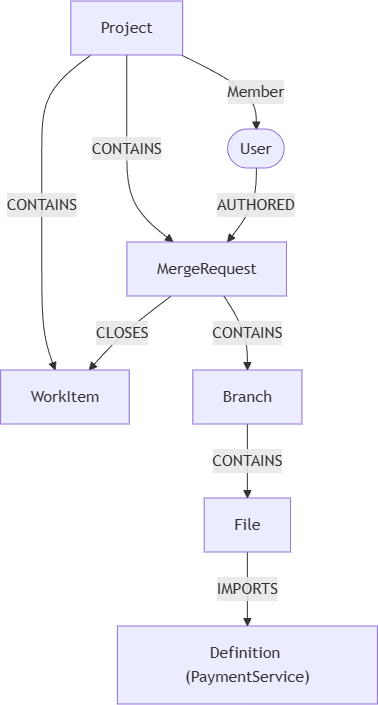
「PaymentService クラスを変更したとき、何が影響を受けるか」という問いは、このグラフを数ホップたどれば答えが出ます。しかし従来のAPIでこれを実現しようとすると、構造的な限界にぶつかります。
GitLab REST APIで取得しようとすると、何十回ものリクエストが必要になります。しかも返ってくるのは個別のオブジェクトであり、それらの関係性は呼び出し側が自分でつなぎ合わせなければなりません。GraphQLはネストしたフィールド展開はできますが、「任意の深さまでたどる」という動的なトラバーサルは表現できません。*..N のような可変長パスは設計上サポートされていません。AIエージェントのコンテキストウィンドウと推論時間の中で、これを現実的にこなすことはできません。
Orbitという解法 ── 1クエリで関係をたどる
この問題を解くために作られたのが GitLab Orbit です。GitLabのすべてのデータをプロパティグラフとして統合し、AIエージェントと開発者がそれを高速にクエリできるようにします。
グラフクエリであれば、「PaymentServiceクラスをインポートしているファイルをすべて返せ」が1クエリで完結します。しかも深さを変えれば「そのファイルを含むプロジェクトのパイプラインが直近30日で何回失敗しているか」まで同じクエリの延長で集計できます。
確率的な補完ではなく、事実に基づいた回答がAIエージェントに届くようになります。
これによってOrbitは、最高で11倍高速なレスポンス、4.5倍少ないトークン消費、45倍少ないハルシネーションを実現できます。

Orbitの技術的な核心
ClickHouseの上にグラフエンジンを自前実装
グラフDBといえばNeo4jやMemgraphのような専用製品が思い浮かびます。しかしOrbitはそれらを採用せず、ClickHouse(列指向OLAPデータベース)の上にグラフエンジンを自前で構築しました。
理由は複数あります。GitLabはすでにClickHouseを分析基盤として採用しており、新たなデータベースを調達・運用するコストとリスクを避けられること。そして何より、ClickHouseのクエリ性能がグラフワークロードに対して十分であることが実測で確認されたこと。2000万行・11GBのデータセットに対する3ホップのグラフトラバーサルの95%が300ms以下で処理できます。
実装上の工夫として、エッジテーブルはグラフトラバーサルに最適化された順序で格納されており、ClickHouseの列指向ストレージと組み合わせることで、グラフ専用DBに匹敵するトラバーサル性能を実現しています。
オントロジー駆動の設計
グラフのスキーマ ── どんなノード型とエッジ型が存在し、それぞれどんなプロパティを持ち、どのエンティティが認可上どのロールを必要とするか ── は、config/ontology/ 以下のYAMLファイルで定義されています。
このYAMLが、データの取り込みからクエリの検証・SQL生成・認可制御まで、パイプライン全体を駆動します。新しいエンティティ型を追加するとき、Orbitのコードを変更する必要はありません。YAMLを書けば、インデクサーもクエリエンジンも自動的に対応します。
3層のセキュリティ
「グラフで全データを横断できる」と聞くと、マルチテナント環境でのデータ漏洩が心配になります。Orbitは3層の防御を持っています。
Layer 1 — テナント分離: すべてのデータに組織IDを含むパスが付与されており、クエリエンジンが自動的に自組織のデータのみに絞り込みます。ユーザーが書いたクエリがこの制限を迂回することは構造上できません。
Layer 2 — GitLab権限との連動: GitLab本体がユーザーのグループメンバーシップを計算し、アクセスが許可された範囲を含むトークンをクエリエンジンに渡します。自分がGitLab上で見られないプロジェクトのデータは、クエリ結果に含まれません。
Layer 3 — 個別リソースの最終確認: 機密Issueなど、グループ権限だけでは判断できない細粒度の権限を、GitLab本体が個別にチェックして結果から除外します。
GitLabの既存の権限モデルがそのままOrbitに適用されるため、Orbitを有効にしてもユーザーが見られるデータの範囲は変わりません。
LLM向け出力フォーマット(GOON)
AIエージェントへの応答には、Orbitチームが独自に設計した GOON(Graph Object Output Notation) というフォーマットを使用しています。JSONと比べてコスト11%減、レイテンシ15%減、正確性4.8ポイント増という実測結果が出ており(Claude Haiku 4.5での計測)、AIとの対話効率を最大化するために出力フォーマットレベルまで最適化されています。
インデックスされるデータの範囲
Orbitがインデックスするデータの範囲は、想像以上に広いです。
SDLCデータ(変更から数分以内に反映):
| カテゴリ | 対象 |
|---|---|
| 組織構造 | グループ、プロジェクト、ユーザー、コメント |
| コードレビュー | マージリクエスト、変更差分、変更ファイル |
| CI/CD | パイプライン、ステージ、ジョブ |
| プランニング | イシュー、エピック、タスク、マイルストーン、ラベル |
| セキュリティ | 脆弱性、スキャン結果、CVE/CWE識別子 |
ソースコード(13言語以上):
Ruby、Java、Kotlin、Python、TypeScript、JavaScript、Rust、Go、C#、C、C++、PHP、Bash/Shell の関数・クラス定義と、ファイル間のインポート・参照関係をすべて抽出します。デフォルトブランチが変更されると自動的に再インデックスされます。フィーチャーブランチはインデックス対象外ですが、MRの差分情報(変更ファイル名等)はSDLCデータとしてインデックスされます。
そして重要なのは、SDLCデータとコードグラフが同一のグラフ上に統合されている点です。「このMRを書いたのは誰で、そのMRが変更したファイルはどのサービスにインポートされているか」という横断的な問いに、一つのクエリで答えられます。
AIエージェントからのアクセス方法
GitLab Duo Agent Platform(UIから自然言語で)
GitLab UIのDuo Chatや各種エージェント(Planner、Security Analyst、Developer Flow等)から、自然言語で質問するだけでOrbitが動きます。設定不要、追加コストなし(ゼロレート)。エージェントが裏側でグラフクエリを自動生成・実行し、ライブデータに基づいた回答を返します。
MCP(Claude Code、Cursor、Codex等から)
外部のAIコーディングエージェントからはMCP(Model Context Protocol)経由で接続できます。/
# Claude Codeへの登録
claude mcp add --transport http gitlab-orbit https://gitlab.com/api/v4/orbit/mcpCursor、Codex、Gemini CLI、opencode等の主要エージェントにも対応しています。
Orbit Local(ローカルリポジトリ、オフライン)
GitLab.comへの接続なしに、手元のリポジトリだけをインデックス化して使うこともできます。データストアはDuckDB(ローカルファイル)で、インストールは1コマンドで完了します。
curl -fsSL "https://gitlab.com/gitlab-org/orbit/knowledge-graph/-/raw/main/install.sh" | bash
orbit index .
orbit sql 'SELECT count(*) FROM gl_definition'Next Generation SCMとの組み合わせ ── 1+1が2を超えるとき
前回の記事でご紹介したNext Generation SCMは、Gitのバックエンドを再設計してAIエージェントが高速にコードにアクセスできるようにするものでした。Orbitはそのコンテキスト供給源として機能します。
Next Gen SCMは「AIエージェントが大量並列でコードにアクセスしても競合や遅延が起きないインフラ」を、Orbitは「何をどう変えるべきかという正確なコンテキスト」を提供します。Agentはその両方を使って初めて、確率的な補完ではなく事実に基づいた作業を、人間の何倍もの速度で実行できます。Next Gen SCMだけでは「速いが不正確」、Orbitだけでは「正確だが実行基盤が追いつかない」。両者が揃うことで1+1が3になります。
具体的なシナリオで見てみましょう。
「deploy_user メソッドをリネームしたい」
| Agent(Orbitなし) | Agent + Next Gen SCM + Orbit | |
|---|---|---|
| 影響範囲の把握 | コードを読んで確率的に補完 | Orbitがグラフをトラバースして確実に列挙 |
| MRの作成 | ドラフトMRを生成 | 影響を受ける全サービスのファイルを含むMRを生成 |
| レビュアーの特定 | コミット履歴から確率的に補完 | Orbitが実際の変更頻度・オーナーシップから最適なレビュアーを特定 |
| マージ後の確認 | 手動でCI結果を確認 | 関連パイプラインの成否をOrbitが横断集計 |
GitLab Developer Flowでは、すでにこの統合が実現しています。WorkItemを渡すと、OrbitがSDLCグラフから依存関係・オーナーシップ・影響範囲を調べ、その情報を元にDeveloper Flowがドラフトのマージリクエストを作成します。Next Gen SCMがコードへの高速・大量並列アクセスを担い、Orbitが文脈を与え、Agentが実行する ── これが1+1が2を超える理由です。
現在の状況
Orbitは現在 Public Beta (GitLab 19.1〜)として、GitLab.comのPremium・Ultimateプランで提供されています。有効化するとサブグループ・プロジェクトは自動的にインデックス対象になります。
Self-Managed版は現在開発中で、GitLab.comでの実績を積んだ後に提供予定です。
今後のロードマップとしては、複数プロジェクトをまたいだコードグラフ(Phase 2)、コードとSDLCの完全統合クエリ(Phase 3)、そしてユーザー定義のカスタムエンティティ追加が計画されています。
まとめ
AIエージェントが確率的な補完に頼らざるを得ない根本原因は、モデルの能力ではなくコンテキストの構造にあります。GitLabのデータは関係構造として存在しているにもかかわらず、複数APIの連鎖ではその関係性をAIに渡せませんでした。
Orbitはその問題を、GitLabの全データをプロパティグラフとして統合し、1クエリで横断的に問い合わせられるようにすることで解決します。ClickHouseの上に実装したグラフエンジン、オントロジー駆動の設計、3層のセキュリティモデル、LLM向けに最適化された出力フォーマット ── これらが組み合わさって、AIエージェントが確率的な補完ではなく事実に基づいて動ける基盤を作っています。
Next Generation SCMと組み合わせることで、AIが組織全体のソフトウェアを理解した上でコードを書き、レビューし、デプロイする ── そのサイクルが現実のものになりつつあります。
参考リンク:
- Orbit公式サイト
- Orbit公式ドキュメント
- 公式ブログ: GitLab Orbitのご紹介:コードとライフサイクル全体のコンテキストを、ひとつのクエリで
- 前回記事: AIエージェント時代のコード基盤「GitLab次世代ソースコード管理」 (Project Switch)
Author
カスタマー サクセス エンジニア。
主にGitLabを担当。GitLab利用&運用歴10年。
GitLab認定 プロフェッショナル サービス エンジニア。
DASA認定 プラットフォーム エンジニア。
好奇心ドリブン。技術課題の解決が三度の飯より好き。



