
AIエージェント時代のコード基盤「GitLab次世代ソースコード管理」

GitLab Transcend 2026 が、6月10日にロンドンで開催され、日本を含む世界中に配信されました。そこでは、3つの大きな技術革新が発表されました。
- 次世代ソースコード管理(プライベートベータ)
リポジトリ全体をクローンする従来の方法に代わり、構造化されたAPI経由で必要な情報のみをサーバーサイドで取得します。これにより、AIエージェントのタスク実行速度が最大50倍に向上します。 - GitLab Orbit(パブリックベータ)
ソフトウェアライフサイクル全体(コード、作業項目、パイプライン、デプロイ、運用シグナル)をマッピングする「コンテキストグラフ」です。AIエージェントが共通の信頼できる情報源を参照することで、応答速度が最大11倍に向上し、トークン消費量を最大4.5倍削減、ハルシネーション(誤情報)も最大45倍低減できるとされています。 - AIエージェント向けガバナンス(プライベートベータ)
AIエージェントのアクションに対するアイデンティティ管理、ポリシー設定、監査、承認プロセスを提供します。これにより、コンプライアンス要件を満たしながら、リアルタイムでエージェントの活動を監視・制御可能にします。
本稿では、このうちの次世代ソースコード管理 (Next Generation Source Code Management) を取り上げます。
次世代ソースコード管理の開発が行われている エピック(&21711 Next gen git backend for the agentic era) と、その下に階層化されている全ての作業アイテム(子エピック、イシュー) を、GitLab DuoのPlanner Agentを使って分析しました。その結果を元に、アーキテクチャー、技術背景、そして開発の計画と進捗を紹介します。
Gitは現代のソフトウェア開発に欠かせないツールです。しかしその内部設計は、人間が1つのリポジトリをcloneしてpushするという、20年前のユースケースを前提にしています。AIエージェントが何十ものリポジトリを並列に、人間の何倍もの速度でアクセスする時代に、その前提は崩れ始めています。
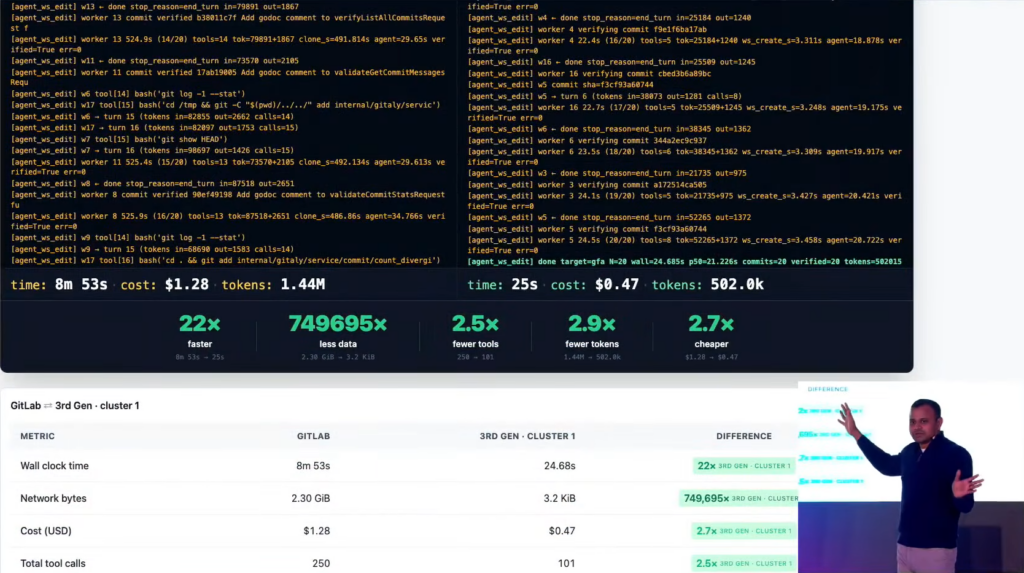
Next Generation Source Code Management、GitLab社内コードネーム「Project Switch」は、この問題に正面から向き合い、Gitとの互換性を保ったまま、最大で、AIエージェントのトークン消費を2分の1に、処理時間を50分の1に、ネットワークトラフィックを1000分の1にします。

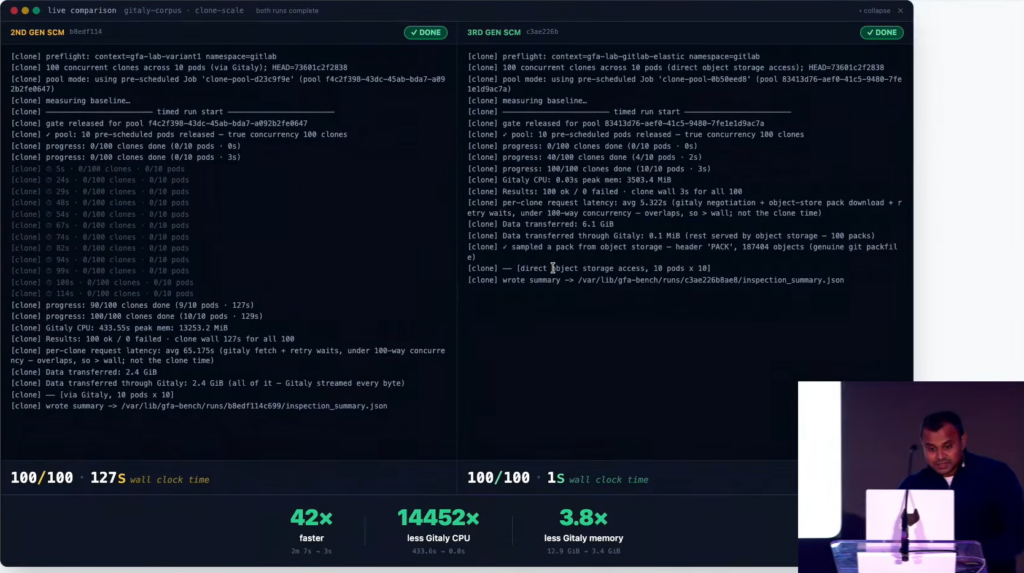
下記は、Transcendのステージで行われたデモの様子で、左側の現行 (2nd Gen) SCM と 右側の Next-Gen (3rd Gen) SCM を比較したものです。前者は clone を、後者は push を 100回、実際に実行した結果を示しています。さまざまな指標が大幅に向上しているのがわかります。
GitとGitalyが抱えてきた構造的な限界
Gitのオブジェクト(コミット、ファイル、ツリー)は長年、ローカルディスク上の2種類のファイル形式で管理されてきました。新しいオブジェクトは個別ファイル(loose object)として書かれ、定期的にまとめてpackfileに圧縮されます。シンプルで堅牢な設計ですが、スケールの壁があります。
ブランチやタグ(refs)の管理も同様です。mainというブランチは、.git/refs/heads/mainという1つのファイルとして存在します。ブランチが数万本になると、その一覧を取得するだけでも長時間かかります。複数のブランチを同時にアトミックに更新することもできません。
そして最大の問題が並列アクセスへの弱さです。Gitはファイルロックで競合を防ぐ設計になっており、読み取りと書き込みが互いにブロックし合います。人間が使う分には許容できたこの制約が、AIエージェントの登場によって致命的なボトルネックになりつつあります。
GitLabのGitサーバー実装であるGitalyも、この前提の上に構築されています。各Gitalyノードはリポジトリデータをローカルディスクに持ち、複数ノードへのレプリケーションと整合性管理(Praefect)が必要です。ノードを増やすたびにデータを複製し、「どのレプリカが最新か」を管理する複雑さが増していきます。
AIエージェントが顕在化させた喫緊の課題
これらの構造的な限界は以前から存在していましたが、AIエージェントの出現がそれを一気に顕在化させました。
GitLab Duo AgentのようなAIエージェントは、コードレビュー、バグ修正、リファクタリングを自律的に行います。その過程で、同一リポジトリへの大量の並列fetch、短時間での繰り返しclone、複数ブランチへの同時アクセスが発生します。人間の開発者が1日に行うGit操作を、エージェントは数分で行います。
従来のGitバックエンドはこの負荷に耐えられません。そしてこれは将来の話ではなく、今まさに起きている問題です。
次世代ソースコード管理のアーキテクチャ
次世代ソースコード管理は下図の青い部分で、アーキテクチャは2つの層に整理できます。
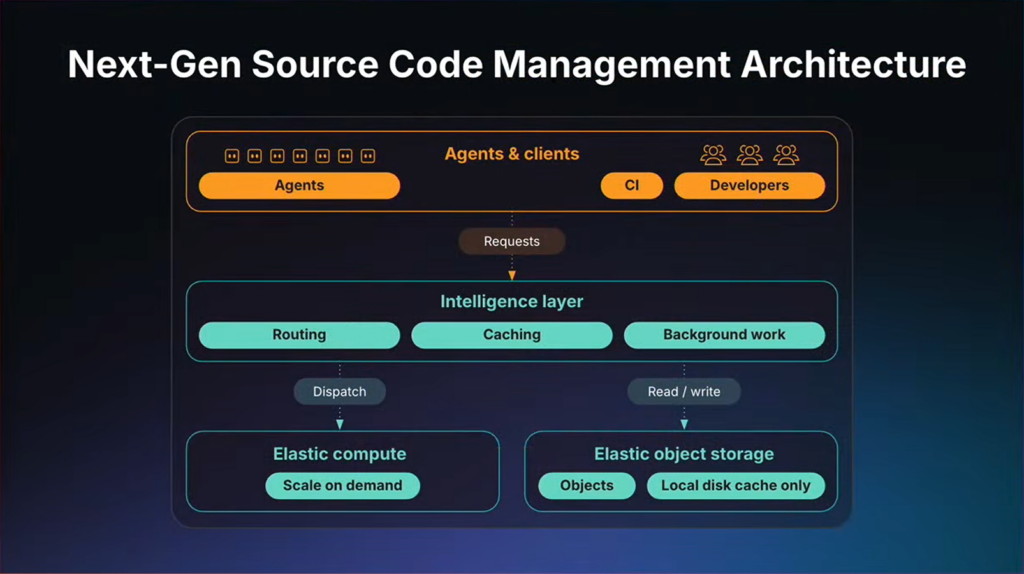
従来はGitalyがComputeとStorageを同一ノード内で兼ねており、密結合していました。次世代ソースコード管理はこの2つを独立した水平なコンポーネントとして切り離し、その上にIntelligence Layerを置きます。この構造の変化が、以降で説明するすべての改善を可能にします。
技術の核心:4つの革新
1. オブジェクトストレージをSingle Source of Truth (唯一の正) に
最も根本的な変更は、GitデータをS3やGCSなどのオブジェクトストレージに移すことです。
現行のGitalyはリポジトリデータをローカルディスクに持ちます。これがスケールの限界を生む根本原因です。データがローカルにある以上、ノードを増やすにはデータを複製しなければならず、複製間の整合性管理が複雑化します。
オブジェクトストレージをSSoT(Single Source of Truth、唯一の正)にすると、この問題が根本から解消されます。全Gitalyノードが同じS3/GCSバケットを参照するため、ノード間でデータを同期する必要がなくなります。ノードがダウンしても、別のノードがオブジェクトストレージから最新状態を読み込むだけで即座に代替できます。Praefectのような複雑な調停者も不要になります。
2. MVCCで「読み書きが互いをブロックしない」世界へ
オブジェクトストレージへの移行で新たな問題が生じます。複数のGitalyノードが同じバケットに同時に書き込もうとしたとき、どう競合を防ぐか。
答えがMVCC(Multi-Version Concurrency Control)です。
MVCCの発想はシンプルです。「書き込みは新しいバージョンを作る。読み取りは開始時点のバージョンを見続ける」。ロックで互いをブロックするのではなく、バージョンを分けることで並列処理を実現します。(下図参照)
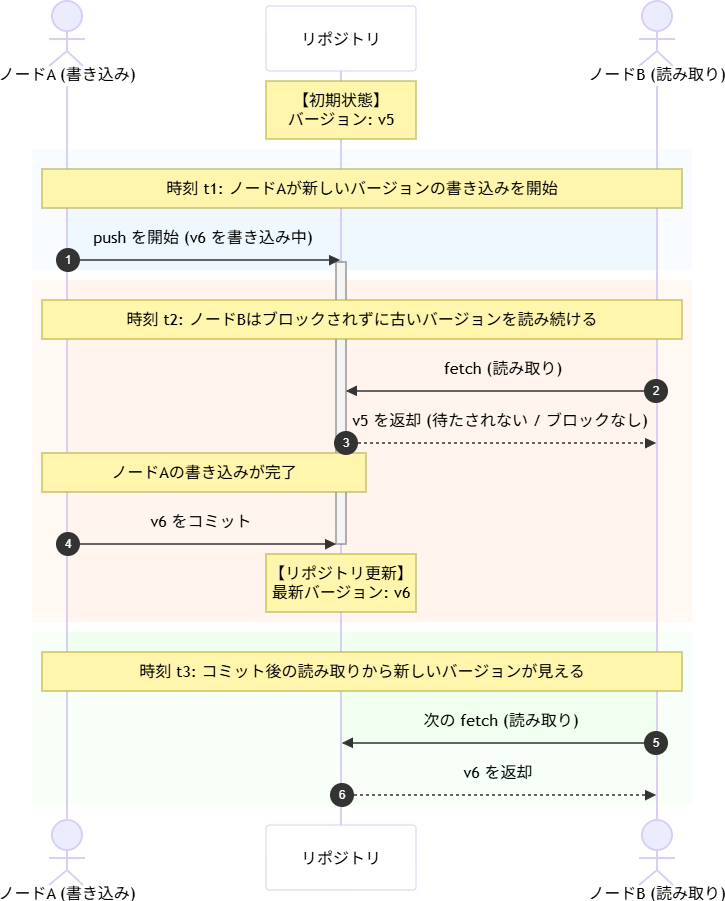
書き込み同士の競合解決にはCAS(Compare-And-Swap)を使います。「現在の値が期待値と一致する場合のみ書き込む」という不可分操作で、S3/GCSが標準で提供している機能です。分散ロックサーバーを別途用意する必要がなく、オブジェクトストレージ自体が競合解決の仕組みを持ちます。
3. Reftableで参照管理を刷新
ブランチ管理の問題にはReftableで対処します。
1参照=1ファイルの従来方式を廃止し、全参照をB-treeライクな構造の単一ファイルにまとめます。ブランチ数が増えても検索はO(log n)で高速なまま。複数ブランチの一括更新もアトミックに行えます。MVCCのスナップショット読み取りとも相性が良く、バージョン番号付きブロックで過去の参照状態を安全に参照できます。
4. Pluggable ODBでGitのオブジェクト格納層を抽象化
S3/GCSバックエンドへの切り替えを可能にするには、Gitのコードベース自体を変える必要があります。Gitはこれまでオブジェクトの格納をファイルシステムに直接依存して実装していました。
Pluggable ODB(Object Database)はこの格納層をインターフェースとして抽象化し、バックエンドを差し替え可能にします。既存のloose objectsとpackfileをまずODBインターフェース越しにアクセスするよう書き直し、その後でS3/GCSバックエンドを差し込みます。
この作業ではGit本体のupstreamへパッチをコントリビュートします。GitLabのエンジニアがGitコミュニティと協力しながら、Gitそのものを進化させています。
Intelligence Layerの役割
ComputeとStorageを分離したことで、その上に「賢い処理層」を独立して設計できるようになりました。
Routing(ルーティング) は、どのGitalyノードにリクエストを送るかを決めます。単純なラウンドロビンではなく、リポジトリIDをハッシュキーとして担当ノードを決定論的に選びます(Rendezvous Hashing)。同じリポジトリへのリクエストは常に同じノードへ向かうため、キャッシュが効率よく機能します。フォーク関係にあるリポジトリを同じノードへルーティングすることで、オブジェクトの重複排除効果もキャッシュレベルで活かせます。
Caching(キャッシング) は、各GitalyノードがS3/GCSのフロントエンドキャッシュとして機能する仕組みです。MVCCスナップショットをローカルに保持し、同一バージョンへの繰り返しアクセスをS3/GCSへの往復なしに処理します。さらにPackfile URIという仕組みで、頻繁にfetchされるデータをS3/GCS上にキャッシュしてクライアントへ直接URLを返します。GitalyのCPUと帯域を消費せずに大量のfetchをさばけます。
Background work(バックグラウンド処理) は、読み取りパスを高速に保つための非同期処理群です。git blameや変更パス探索のような「同じグラフ構造を繰り返しウォークする」高コスト操作を事前計算してインデックス化します(Derived Data)。古くなったMVCCスナップショットのガーベジコレクションや、packfileの最適化も担います。
Orbitと次世代ソースコード管理が組み合わさると何が起きるか
次世代ソースコード管理が「Gitデータを100倍速く届けるインフラ」だとすれば、Transcendで発表されたもうひとつの技術革新 Orbit(GitLab Knowledge Graph) は、「そのデータの意味を理解するインテリジェンス」です。
Orbitはコードのシンボル・関数・依存関係といったコードグラフに加え、Issue、MR、Pipeline、脆弱性といったSDLCメタデータを統合したグラフデータベースです。AIエージェントはこのグラフに対してNeo4JのCypherに似たクエリを投げることで、「このMRが閉じたIssueに関連するファイルを変更したPipelineで検出された脆弱性は何か」のような複雑な問いに一発で答えられます。
この2つが組み合わさると、単純な足し算以上の効果が生まれます。
次世代ソースコード管理はコードの書き込みパスを制御しています。pushが発生した瞬間に、Orbitのインデクサーへブランチのイベントをリアルタイムで通知できます。Orbitはその通知を受けてGitalyからコードを取得し、グラフを更新します。インデックスが常に最新の状態に保たれます。
外部ツールがGitLabのwebhookに依存してインデックスを更新する場合、通知のラグや取りこぼしが生じえます。次世代ソースコード管理はその通知源そのものです。
さらに次世代ソースコード管理のBackground workが事前計算するDerived Data(git blame、変更パス探索など)は、Orbitのグラフクエリの精度と速度を直接底上げします。「どのファイルがいつ誰によって変更されたか」という情報がリアルタイムで正確に提供されることで、AIエージェントの判断の質が上がります。
Gitインフラの刷新とコードインテリジェンスの統合。この2つが揃ったとき、GitLabはAIエージェントのための開発プラットフォームとして、単なる「高速なGitホスティング」を超えた存在になります。
段階的な移行戦略
次世代ソースコード管理は一気に切り替えるのではなく、4つのステージで段階的に移行します。
Stage 1(2026年7月目標、現在進行中): まず参照(refs)だけをMVCC化します。Reftableバックエンドへの移行で、ブランチ管理の問題を先に解決します。
Stage 2(2026年9月目標): オブジェクトもMVCC化します。Pluggable ODBの整備が完了し次第、参照とオブジェクト両方でMVCCが機能する状態にします。
Stage 3: オブジェクトストレージをSoTにします。オブジェクトストレージへの書き込みを開始し、段階的にローカルディスクへの依存を排除します。
Stage 4: クラスタリングを導入します。Rendezvous Hashingによるルーティングで、ノードを追加するだけでスケールアウトできる構成にします。
おわりに
次世代ソースコード管理は地味に見えて、実は壮大なプロジェクトです。Git本体のupstreamにパッチを送ってGitのオブジェクト格納層を抽象化し、オブジェクトストレージをSoTにし、MVCCで並列処理を実現し、クラスタリングを刷新する。それぞれが独立した難題であり、しかも段階的に、本番環境を止めずに移行しなければなりません。
AIエージェントが当たり前になる世界で、コード基盤がそのスピードに追いつけるかどうか。GitLabはその問いに、Gitのバックエンドそのものを再設計することで答えようとしています。
Author
カスタマー サクセス エンジニア。
主にGitLabを担当。GitLab利用&運用歴10年。
GitLab認定 プロフェッショナル サービス エンジニア。
DASA認定 プラットフォーム エンジニア。
好奇心ドリブン。技術課題の解決が三度の飯より好き。



