
非構造化データが主役の時代へ:マルチモーダルDBでデータ活用の壁を打ち破る
はじめに:増え続けるデータ、どう活かす?
先日参加したGoogle社のイベントで、「生成AIはデータドリブン経営の救世主か?」という興味深いセッションがありました。このセッションで、今や生成されるデータの80%が非構造化データであるという事実と、それらを扱う既存データベースの限界について改めて考えさせられました。
あなたは毎日、膨大なデータと向き合っているはずです。テキストや数値データだけでなく、画像、音声、動画、センサーデータといった「非構造化データ」の量は、ここ数年で爆発的に増えています。実際、生成されるデータの80%は非構造化データであると言われています 。
これらのデータはビジネスの鍵を握る一方で、「既存のデータベースじゃ無理」と諦めていませんか?今日は、非構造化データを最大限に活かすための次世代データベース、マルチモーダルデータベースについて、一緒に見ていきましょう。
既存DBの限界:データ活用の壁
まず、現在の既存のデータベースに入れるデータの形式を振り返ります。
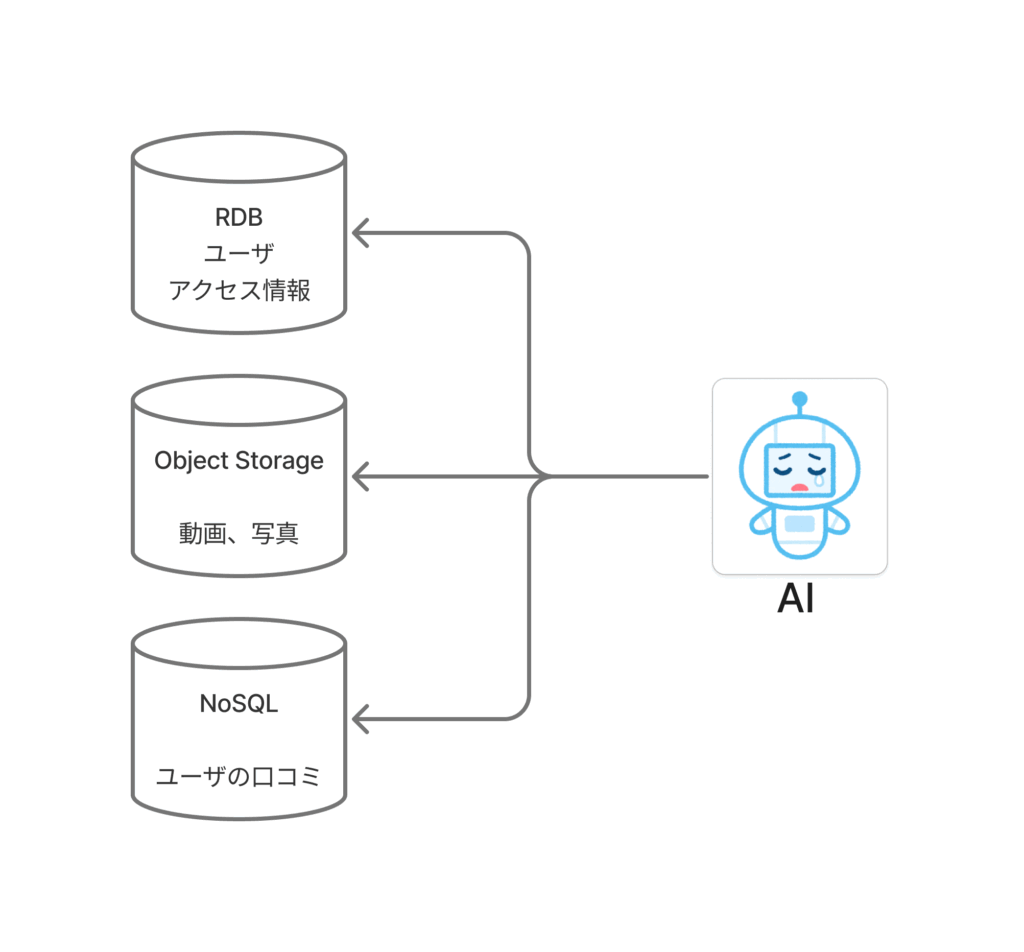
リレーショナルデータベース(RDB)は、構造化データ管理には最適です。しかし、画像や音声のような非構造化データは苦手で、通常は外部に保存し、RDBにはそのパス情報だけを置く形になります。
NoSQLデータベースは、ドキュメント指向DBやグラフDBなど、特定のデータ形式に特化しています。これによりRDBの弱点を補いますが、複数のデータ形式を扱うには、それぞれのDBを組み合わせる必要があり、管理が複雑化します。
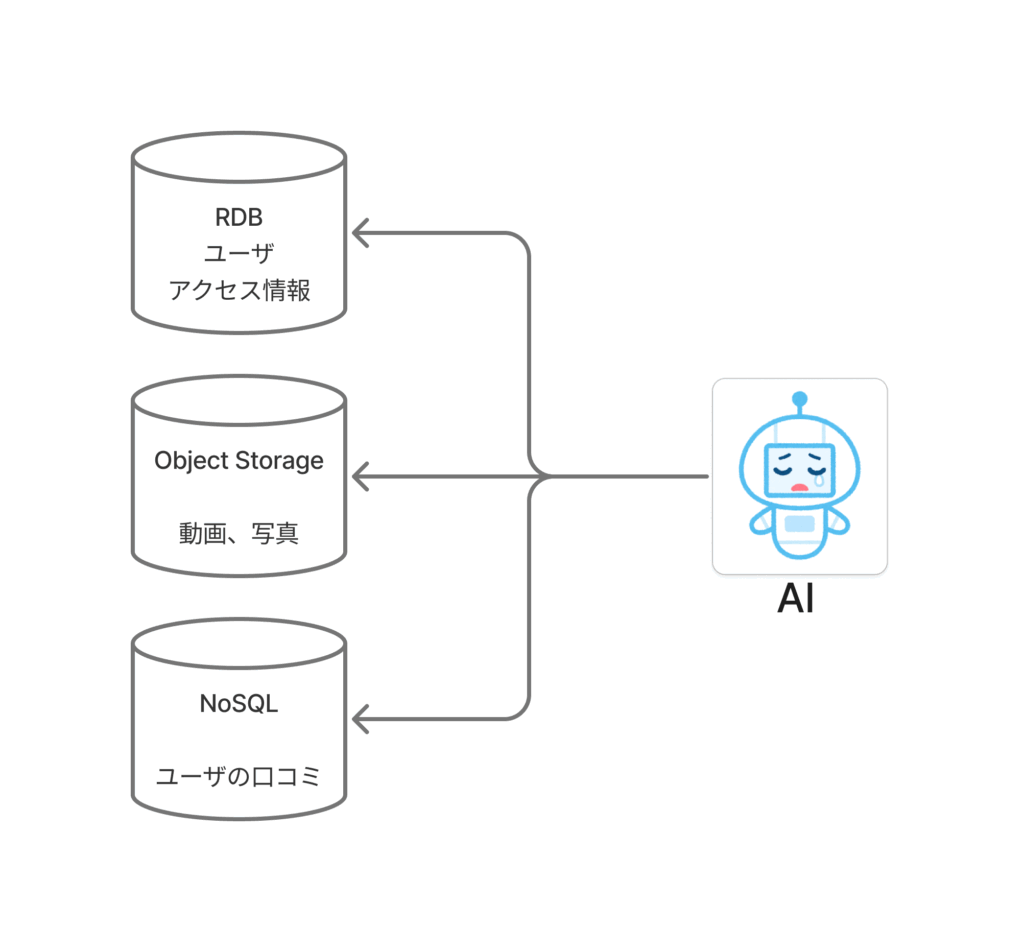
AI時代における既存のデータベースの限界は、まさにこの「多様なデータを統合的に管理し、活用することの難しさ」にあります。AIモデルは様々な非構造化データを学習しますが、それらがバラバラのデータベースに散らばっていると、データの前処理や統合に多くの手間と時間がかかります。
非構造化データを活用できないことで、企業は莫大な価値を失っているのが現状です。具体的には、顧客体験の劣化、業務効率の低下、収益につながるインサイトの損失、といった問題が生じています 。画像検索で画像そのものだけでなく、関連するテキスト情報やユーザーのレビューも一緒に検索したい場合、従来のDBではデータがサイロ化し、横断的な検索や分析、高速な処理が困難になる、という壁にぶつかります。
マルチモーダルデータベースが打ち破る壁
そこで登場するのが、マルチモーダルデータベースです。
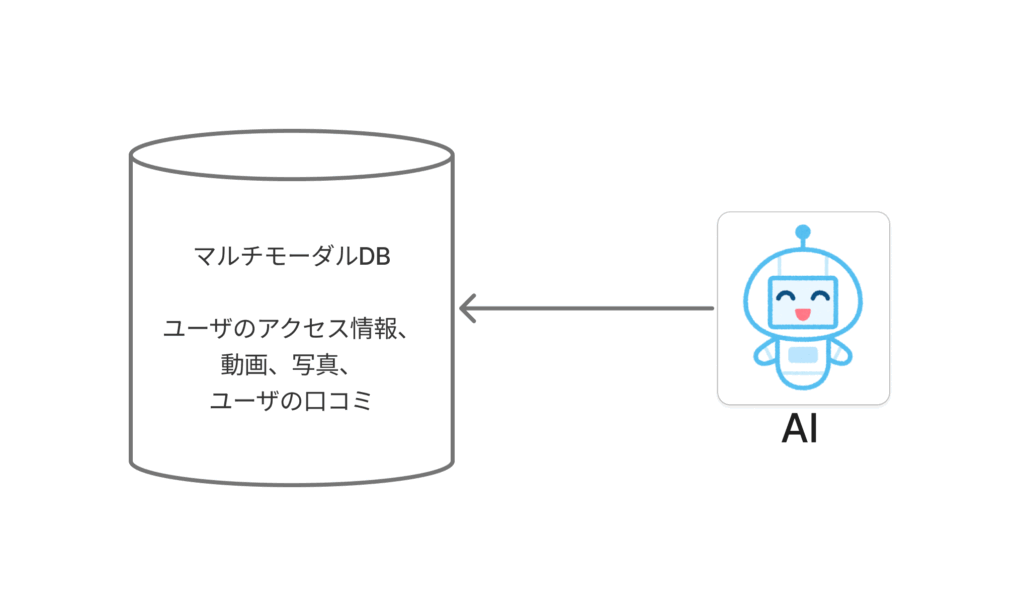
マルチモーダルデータベースは、複数のデータ形式を単一のデータベースで統合的に管理できます。テキスト、数値はもちろん、画像、音声、動画、それらの「特徴量」を表すベクトルデータ、時系列データ、グラフデータなどを、シームレスに扱えるようになります。これは、AIネイティブでマルチモーダルなデータ活用を可能にします 。例えば、GoogleのGeminiは、テキスト、画像、音声、動画などを組み合わせたプロンプトに対応する、マルチモーダルな生成AIです 。
具体的にできることは、以下の通りです。
- ベクトル検索:画像や音声の「意味」を数値化したベクトルデータをDBに直接保存し、類似度で高速に検索できます。「この画像と似た画像を探す」「この音声と似た特徴を持つ顧客を探す」といったことが可能になります。
- 全文検索の強化:テキストデータだけでなく、画像キャプションや音声の文字起こし結果も統合的に全文検索の対象にできます。
これにより、これまでバラバラだった非構造化データが「宝の山」に変わります。データ統合の手間が大幅に減り、より深い洞察や高度なアプリケーション機能の実装が可能になるのです。
代表的なマルチモーダルDB製品・OSSの紹介
マルチモーダルデータベースの領域は進化が速く、様々なアプローチのサービスやOSSが登場しています。
- ベクトルデータベース
- Milvus
- Pinecone
- Weaviate
- Elasticsearch(ベクトル検索機能)
- MongoDB(ベクトル検索機能)
- PostgreSQL (pgvector拡張)
- Redis(ベクトル検索モジュール)
- データプラットフォームの統合
これらは、それぞれ異なる得意分野を持っています。あなたのプロジェクトの要件や既存の技術スタックに合わせて、最適なマルチモーダルDBを選択することが重要です。
おわりに
マルチモーダルデータベースは、AI時代におけるデータ活用のあり方を根本から変える可能性を秘めています。非構造化データがビジネスの主役となりつつある今、この波に乗れるかどうかで、エンジニアとしての価値も、企業の競争力も大きく変わるでしょう。
これは、新しい知識とスキルを身につけ、キャリアを次のステージに進める絶好のチャンスです。この変化を、ぜひあなたのエンジニアリングの未来を拓く追い風として捉えてみてください。



