
次世代AIインフラはこう作る:Mirantis k0rdentとNVIDIA BlueFieldによる実践的な設計
本稿はMirantisブログ「Mirantis k0rdent and NVIDIA BlueField: A Practical Blueprint for Building Next-Generation AI Infrastructure(2025/06/06)」を和訳、編集したものです。
AIの進化が、クラウドの常識を塗り替える
AI技術の活用が広がるにつれて、クラウドネイティブなシステムにおけるデプロイのあり方が大きく変わってきています。
これまで業界では、「インフラからワークロードを分離する」という考え方が主流でした。インフラ、つまりハードウェアからアプリケーションを切り離すことで、さまざまな環境で動かせるようにするためです。
これは、ハイパースケーラーと呼ばれる大規模クラウド事業者が提供する、多様なニーズに応えるための柔軟なクラウドサービスによって定着しました。
しかし、AIのワークロード、特に計算を高速化する「アクセラレーテッド・コンピューティング」は、このパターンを覆します。これらは、GPUだけでなく、それを支える InfiniBand、NVLink、RoCEなどの「アクセラレーテッド・ネットワーキング」や、高速かつ大容量なストレージといった、インフラの特定の物理的機能に深く依存することが多いからです。
効率的なインフラ活用が不可欠
これらの特殊なリソースには、多大なコストがかかります。そのため、いかに効率よく利用し、ワークロードを最適化して最大限の効果を引き出すかが非常に重要です。
これを実現するには、インフラのあらゆる階層を動的に定義・プロビジョニングしつつ、強固なセキュリティと分離性を保つ必要があります。
つまり、必要なインフラをコードで宣言するだけで自動的に構築できる、宣言的な「Infrastructure as a Service(IaaS)」が必要とされているのです。
AIインフラが抱える課題
高性能コンピューティング向けのインフラには、特有の課題が伴います。たとえば、GPUの割り当てや分割、RDMAネットワークの有効化、高度なスケジューリング、パフォーマンスのチューニング、Kubernetesなどのプラットフォームの効率的なスケーリングなどです。
また、複数のユーザーが動的にワークロードを共有するような環境では、さらに複雑さが増します。クラウドサービスプロバイダーや開発チームなど、複数のユーザーでシステムを共有する「マルチテナンシー」が求められる環境では、ユーザーがクラウドの持つ動的な柔軟性を期待するため、課題と複雑さはさらに増す一方です。
このような背景から、「AIファクトリー」と呼ばれるAI開発基盤では、ワークロードとインフラ両方の設定において、次のような課題に取り組む必要があります。
- 価値実現までの時間:AIインフラは、従来のシステムよりも専門的なチューニングやセットアップが必要で、設定や習得に時間がかかります。
- マルチテナンシー:マルチテナンシーへの対応は、データのセキュリティ、リソースの共有、競合の管理に不可欠です。
- データ主権:AIワークロードは機密データによって実行され、独自のモデルや重みを含むことが多いため、データの利用場所や方法を管理することが重要です。
- 規模と広がり:AI向けのインフラは、多数のコンピューティングシステムで構成されるか、エッジやIoT向けのワークロードのために高度に分散化されるのが一般的です。
- リソースの希少性:GPUなどの重要なコンピューティングリソースは希少なため、利用可能なすべての場所で共有される必要があります。
- スキルのギャップ:多くのAIプロジェクトは、インフラの専門家ではないデータサイエンティストや開発者によって進められており、彼らはインフラを管理する手間を望んでいません。
クラウド・GPUサービスプロバイダーの課題
クラウドおよびGPU as a Service(CSP、GPUaaS)のプロバイダーも、マルチテナントサービスを提供するために、独自の課題を克服しなければなりません。これらの環境には、以下のような要件が求められます。
- 地域別、ユースケース別のモデルデータ基準への準拠
- データのプライバシー、ビジネス、アプリケーションのセキュリティ保護
- リソース利用率と効率の最大化
- GPUの選定とパーティショニングの最適化
- ネットワークレイテンシの削減とパフォーマンスの向上
- パフォーマンスとコストを考慮したストレージの最適化
- サービスの継続性を監視
- CPUおよびGPUの稼働状況と利用率の追跡
- ネットワーク、ストレージ、サポートインフラにおける障害イベントの検出
- モデルとアプリケーションのパフォーマンス、レイテンシーのベンチマーク
- モデルとアプリケーションの迅速な反復開発とデプロイ
- コストの効果的な追跡と管理
- 上記すべてを、サービスを中断することなく迅速に管理
- 常に厳格なテナント間の分離を確保
Infrastructure as a Service
前述の課題に対する明確な答えの1つは、ベアメタルからソフトウェアスタックに至るまで、必要なものをすべてを「宣言的」に定義できる、包括的なInfrastructure as a Service (IaaS) を構築することです。
AI向けにIaaSを活用するには、柔軟かつ再現性のあるパターンでエンドユーザーにサービスを提供できるよう、基盤となる複数のレイヤーを組み合わせる必要があります。鍵となるのはテンプレートの使用です。これにより、インフラを一貫してデプロイでき、コンフィグレーション・ドリフトと呼ばれる「構成のずれ」を防ぐことができます。
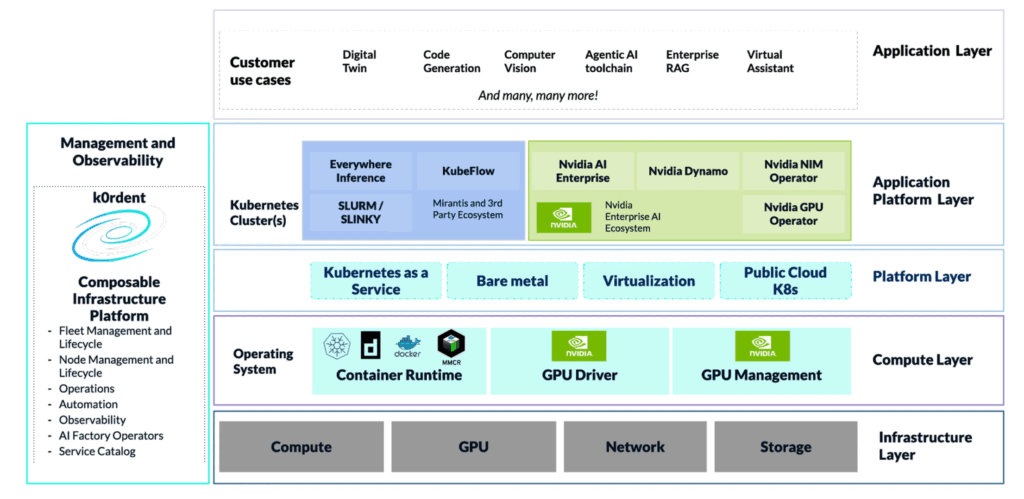
コンセプト概要図
テンプレートモデルを利用することで、インフラレイヤーから仮想マシン、Kubernetesクラスタに至るまで、あらゆるサービスを定義できるようになります。これにより、アプリケーションが必要とするものを正確に提供することが可能になります。
インフラストラクチャのプロビジョニングをサービスとして自動化するこのアプローチは、アプリケーションを実行するために不可欠な複数のレイヤーから構成されています。
- 管理と可観測性: テンプレートに基づく宣言的なモデルを使用し、インフラ全体を制御するコントロールプレーンです。
- インフラストラクチャー レイヤー: コンピューティングホストと、それに関連するネットワークインフラのプロビジョニングと設定を行います。
- オペレーティングシステム レイヤー: ベアメタルホストへのOSのプロビジョニングや、OpenStackやKubeVirtなどの仮想化プラットフォームにおけるゲストOSのプロビジョニングを行います。
- プラットフォーム レイヤー: Kubernetes as a Service、仮想化、ベアメタル専用ホストを自動化します。
- アプリケーションプラットフォーム レイヤー: NVIDIA Dynamo、Run.ai、llm-dなどの推論サービスといった専門的なサービスを提供するためのPaaSソリューションを自動化します。
強固な分離性を備えたマルチテナント Kubernetes as a Service (KaaS)
このテンプレートアプローチには多様なパターンがあります。ここでは、サービスプロバイダーや企業が、厳格な分離性を保ったマルチテナント Kubernetes as a Service (KaaS) を、スタック全体の各レイヤーにおいてどのように構築できるかに焦点を当てます。
このアプローチは、テナントにKubernetesクラスタへの完全なアクセスを許可しつつ、複雑なネットワークと分離性に対応します。また、テナントがクラスタレベルで独自のCNI(Container Network Interface)を選択することも可能です。
これにより、必要なサービスが事前にデプロイ・設定されたKubernetesクラスタが提供され、Kubernetesワークロードをすぐにデプロイできるようになります。これらのクラスタは次の特徴を備えています。
- Kubernetesワーカーとコントロールプレーンの厳格な分離。
- 完全にホストされ、管理されたKubernetesコントロールプレーン。
- ネットワークインターフェースレベルでの厳格なネットワーク分離。テナントは割り当てられたインターフェースにのみアクセスでき、そのインターフェースもテナントに割り当てられたVLANにのみアクセス可能。
- 分離された不変のワーカーOS。テナントがホストを侵害できたとしても、ネットワークやハイパーバイザーホストには到達できない。
環境の概要
ここでは、完全にテナントが分離されたオンデマンドKaaS(Kubernetes as a Service)クラスタを提供するため、「k0rdent」というソリューションを使用します。スタックのすべてのレイヤーでセキュアなマルチテナンシーを実現するには、次の構成が必要です。
- NVIDIA BlueField-3 DPUを搭載したベアメタルコンピューティングホスト
- ホスト上にデプロイされたベアメタルKubernetesクラスタ
- BlueField-3 DPU上にデプロイされた、分離されたKubernetesクラスタ(下図参照)
- KubeVirtによってオーケストレーションされる仮想化レイヤー
- KubernetesワーカーがVMとして動作し、コントロールプレーンがホストされている、分離されたテナントクラスタ
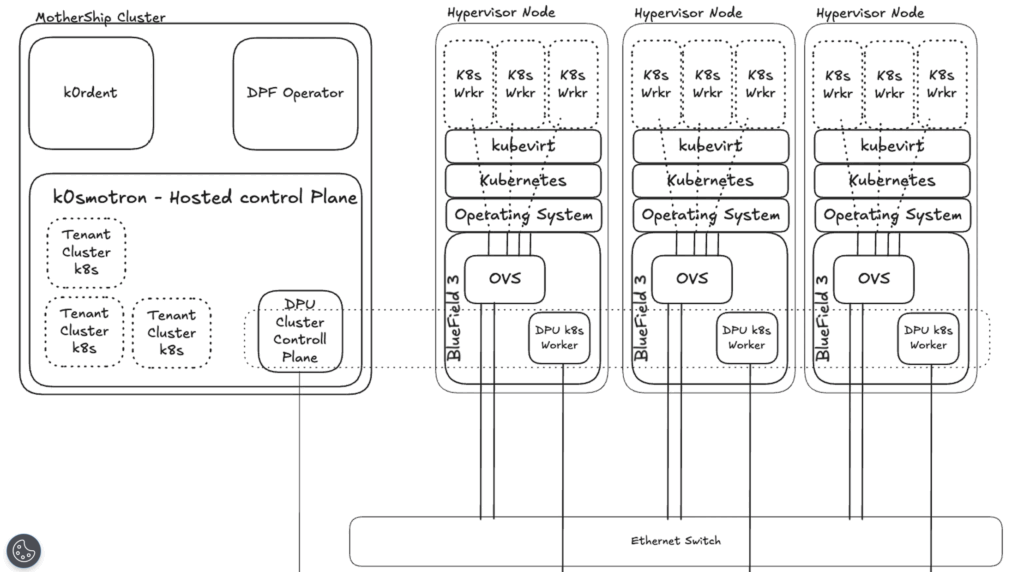
用語解説
ここまでに記述した専門用語について補足します。
- Mothership Cluster(マザーシップ・クラスタ): 管理および可観測性コンポーネントをホストし、全体のコントロールプレーンとなるKubernetesクラスタです。
- Child Cluster(チャイルド・クラスタ): マザーシップ・クラスタ上のk0rdentによってデプロイ・管理されるKubernetesクラスタです。
- 注:これらは、クラスタデプロイメントオブジェクトとして定義されます。
- Cluster Templates(クラスタ・テンプレート): 特定のインフラプロバイダーに合わせた、クラスタ・デプロイメントの種類や設定を定義するテンプレートです。
- Service Templates(サービス・テンプレート): クラスタ上で実行されるKubernetesアプリケーションを定義するテンプレートです。複雑な設定を含めることができ、デプロイ済みのクラスタの情報も利用できます。
- DPU Cluster(DPUクラスタ): ワーカーがBlueField-3 DPUのARMコア上で動作するKubernetesクラスタです。
BlueField-3 のセットアップ
BlueField-3は、ホスト分離のためにDPUモードとZeroTrustモードで設定された後、k0rdentを使ってプロビジョニングされます。
物理的な接続は、ホスト上のBlueFieldカードの数や環境のニーズに応じて指定でき、1つのホストでEthernetとInfiniBandの両方に対応します。ここでは、両ポートをEthernetスイッチに接続する構成とします。
BlueField-3 DPUには、k0rdentのベアメタルオペレーターによって、専用のマシンテンプレートに基づいたカスタムイメージが初期化時に書き込まれます。
カードの初期化時には、以下の設定が行われます。
- ZeroTrustをredfish経由で有効化します('{"Oem": {"Nvidia": {"HostPrivilege": "Restricted"}}}')
- VirtIOエミュレーションとPCIスイッチエミュレーションを有効化し、ホストのPCIe RShimインターフェースを無効化します。
コードの例
mlxconfig -d set \
VIRTIO_NET_EMULATION_ENABLE=1 \
VIRTIO_NET_EMULATION_NUM_PF=10 \
VIRTIO_NET_EMULATION_NUM_VF=10 \
PCI_SWITCH_EMULATION_ENABLE=1 \
PCI_SWITCH_EMULATION_NUM_PORT=10 \
RSHIM_ENABLE=0k0rdent の主なアクション
k0rdentは、クラスタ定義テンプレートに基づき、以下のタスクを実行します。
- k0rdentベアメタルオペレーターを使用し、k0sのワーカーを含むカスタムイメージでDPUを登録・プロビジョニングします。(k0sは、CNCF Sandboxに承認されたKubernetesディストリビューションです。)
- k0smotronが提供するセキュアなコントロールプレーンを利用し、ホストされたコントロールプレーンテンプレートを使ってDPU上にKubernetesクラスタをプロビジョニングします。これにより、ワーカーとコントロールプレーンの厳格な分離が保証されます。
- k0rdentのサービステンプレートを使って、NVIDIA DOCA Platform Framework (DPF) のコンポーネントをDPUクラスタにデプロイします。
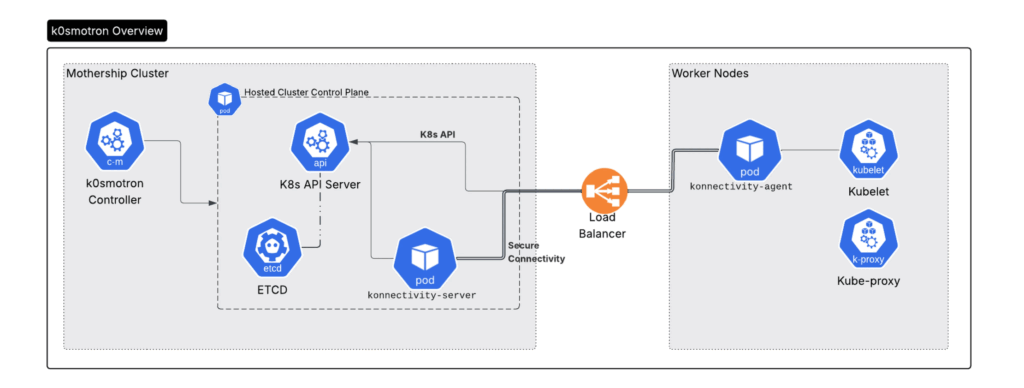
K0smotron 概略図
ハイパーバイザーとベアメタルホストのプロビジョニング
ハイパーバイザーホストは、k0rdentのベアメタルプロバイダーとk0smotronがホストするコントロールプレーンを使用して、ベアメタルホスト上にプロビジョニングされたKubernetesワーカーです。このパターンは、テナントに提供される専用のKubernetesクラスタとして、分離されたネットワーキングとともに提供することも可能です。このKubernetesクラスタには、仮想マシンのオーケストレーションレイヤーを提供するためにKubeVirtがデプロイされます。
デプロイ手順
- ネットワークの作成: テナント用にネットワークオブジェクトが作成されるk0rdentネットワーキングが、テナントネットワーク名、IPAMサポートを含むIPアドレス、およびVXLAN IDを定義します。
- 管理インターフェース: k0rdentネットワークオペレーターが、ホスト上のkubernetesクラスタ管理ポートにポートを割り当て、OVSを設定します。通常のVMデプロイではこの手順は不要です。
- ノードの検出:IronicとMetal3を活用した k0rdentベアメタルがノードを調査し、IOシステムとノード構成に関する詳細情報を収集します。管理ネットワークポートの検出も行います。
- ノードプール: ノードがノードプールに割り当てられ、デプロイに使用できるようになります。
- クラスタのデプロイ: ノードプールと使用するネットワークを参照するk0rdentの
Cluster Deploymentオブジェクトが作成されます。 - ノードのプロビジョニング: CAPIとMetal3 Providerを活用したk0rdentによって、オペレーティングシステムとKubernetesがデプロイされます。
- GPUオペレーター:
Cluster Deploymentオブジェクトで定義されたサービステンプレートによって、NVIDIA GPUオペレーターがクラスタにデプロイされます。設定内容によって構成オプションが適用されます。 - KubeVirtのデプロイ:
Cluster Deploymentオブジェクトで定義されたサービステンプレートによって、KubeVirtがクラスタにデプロイされます。
ベアメタルホスト
ベアメタルホストのテンプレートには、cloud-init を使用して環境固有の設定を記述し、ホストが仮想化に適切に準備されていることを保証する項目が含まれます。
次は、Intelベースのホストを前提とした設定例です。
- IOMMUを有効化し、ホスト上での分離性を高める。
intel_iommu=on iommu=pt- PCI再割り当てを有効化し、PCIアドレスの再利用を可能にする。
pci=realloc- nouveau モジュールを無効化し、NVIDIA GPUドライバーをデプロイする。
echo "blacklist nouveau" | sudo tee /etc/modprobe.d/blacklist-nouveau.confecho "options nouveau modeset=0" | sudo tee -a /etc/modprobe.d/blacklist-nouveau.confGPUオペレーター
ハイパーバイザーをデプロイする際、GPUオペレーターのサービステンプレートで**vm-passthrough (VFIO)とvm-vGPU (vGPU)**のどちらを使用するかを選択します。両方ともデプロイすることも可能ですが、その場合はホストレベルで設定が必要です。
この選択は、Cluster Deployment オブジェクトで設定されます。これにより、デプロイメントの構成が正しく、ノードラベルが適切に設定されます。たとえば、vGPUの場合、以下のようになります。- ノードラベル:
nvidia.com/gpu.workload.config=vm-vgpu - サンドボックス(VMワークロード)を有効化:
sandboxWorkloads.enabled=true
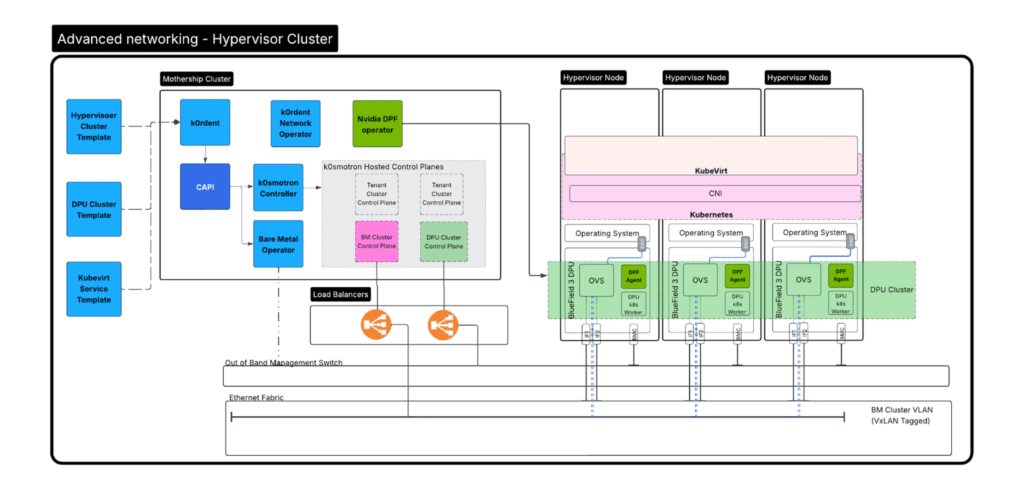
高度なネットワーク - ハイパーバイザー クラスター
ハイパーバイザークラスタの完成
この時点で、ベアメタル上で完全に管理され、厳格な分離性を備えたKubernetesクラスタが完成しました。このクラスタは、KubeVirtとKVMが動作しており、テナント用のチャイルドクラスターをデプロイする準備が整っています。
ここでは、分かりやすくするためにこれを「ハイパーバイザークラスタ」と呼びます。実際にはチャイルドクラスタの一種です。いわゆる「入れ子構造」になっています。
この環境は、GPUのパススルーをサポートするように設定されており、ワークロードの要件に応じてネットワークのSR-IOVにも対応可能です。
チャイルドクラスター
チャイルドクラスターのデプロイは、ベアメタルクラスターと非常によく似ています。唯一異なる点は、ベアメタルオペレーターの代わりにKubeVirtプロバイダーがプロビジョナーとして機能する点です。クラスタは、Cluster Deployment オブジェクトを定義することで宣言的に構築され、このオブジェクトがKubeVirtクラスタテンプレートを利用してクラスタをデプロイします。
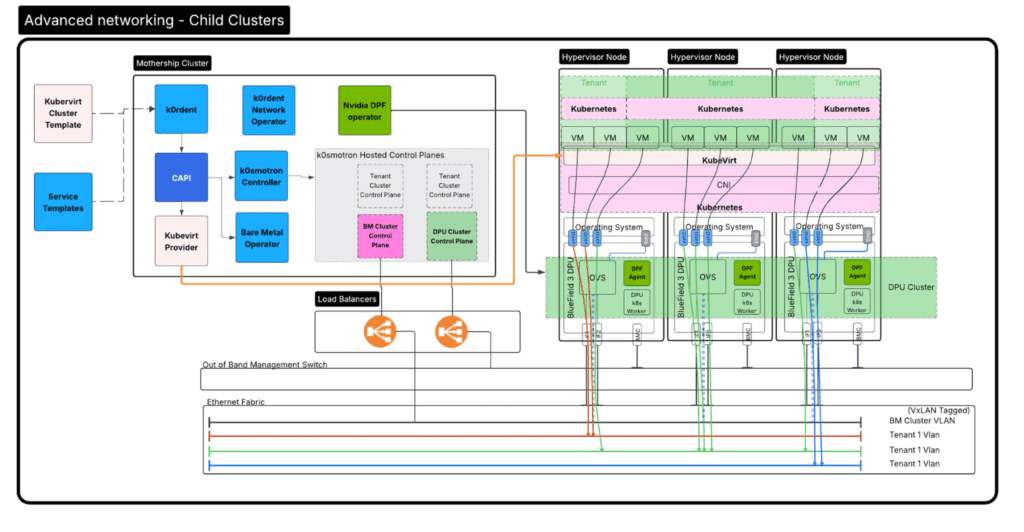
高度なネットワーク - チャイルドクラスタ
クラスタ・テンプレート
使用されるチャイルドクラスタテンプレートは、以前に選択したGPUのプロビジョニング戦略によって異なります。この場合も、クラスタごとに一意の Cluster Deployment オブジェクトが作成され、それがk0rdentのKubeVirtプロバイダーとネットワークプロバイダーを活用してクラスタをプロビジョニングします。
システムが実行する手順は次の通りです。
- ネットワークオペレーターが、IPAMルール、またはユーザーが割り当てたルールに基づいてネットワークを作成します。
- 次に、ネットワークオペレーターはML2プラグインメカニズムを介してOvS(Open vSwitch)ネットワークフローを設定し、Virtioポートを適切なネットワークに接続・タグ付けします。
- k0rdentがVMを作成し、割り当てられたポートに接続してクラスタをデプロイします。
まとめ
AIワークロードがインフラの要件を再定義し続ける中、従来のクラウドネイティブアーキテクチャの抽象化だけではもはや不十分であることは明らかです。これらのワークロードには、特殊なハードウェアによる、高い精度で緊密に統合されたネットワーキング、セキュアなマルチテナンシー、そしてリアルタイムなプロビジョニングが、すべて効率的かつ大規模にオーケストレーションされることが求められます。
Mirantis k0rdentの宣言的でKubernetesネイティブな機能と、NVIDIA BlueField DPUの高性能なデータ処理および分離機能を組み合わせることで、組織はAIに最適化されているだけでなく、ガバナンスが効き、柔軟で、費用対効果の高いインフラを構築できます。このアプローチにより、コンポーザブルでセキュア、かつ動的でデータドリブンなワークロードのニーズに合わせてカスタマイズされた、新しいクラスのIaaSが実現します。
GPUaaSソリューションを設計するプラットフォームチームであれ、AIサービスをスケールアウトするサービスプロバイダーであれ、k0rdentとBlueFieldの統合は、AI時代のパフォーマンス、ガバナンス、およびアジリティの要求を満たす、次世代インフラ構築のための実践的な青写真を提供するでしょう。
Mirantis製品、K0rdent、K0s に関する詳細なご説明をご希望の方は、お気軽に お問い合わせください。



