
【Neo4j】 エージェント「ツール」:
概要、仕組み、AIエージェントによる活用方法
本稿は Neo4j 公式ブログ「Agent tools: What they are, how they work, and how AI agents use them(2026/May/6)」の和訳記事です。
著者:Enzo Htet & Isobel Krüger
エージェントツール(Agent tools)とは、APIの呼び出し、データベースのクエリ、メッセージの送信、ワークフローの実行など、AIエージェントが現実世界に働きかけるための「関数」や「サービス」のことです。これらによって言語モデルは「単なるテキスト生成」から、ライブシステムと相互作用する「エージェント」へと昇格します。
AIエージェントの能力を引き出すには、タスク完了のためにエージェントが使用できるツールの存在が不可欠です。つまり、最新のデータを返すデータベースクエリ、一連の処理を完結させる電子メールの送信、成果物を生成するファイルへの書き込み、これらがツールの具体例です。エージェントツールがなければ、エージェントは宝の持ち腐れになってしまいます。
本稿では、主なエージェントツールの種類、エージェントがそれらを選択して使用する仕組み、MCP(Model Context Protocol)がツールの統合をどのように標準化するか、そしてそれらの実装方法について解説します。
もくじ
- エージェント「ツール」の種類
- エージェント「ツール」とエージェント「スキル」の違い
- エージェントのツール選択方法と使用方法
- MCPのエージェントツール統合の標準化
- エージェントツールの実装方法
- なぜリトリーバルツールが最も重要か
- AIエージェントに 必要なコンテキストレイヤーを構築する
- 次のステップ
- エージェントツールに関するFAQまとめ
エージェント「ツール」の種類
AIエージェントは、ジョブの種類に応じて異なるツールを使用します。各カテゴリの目的を押さえておくことで、タスクに最適なエージェントツールを選べます。 エージェントツールの主な種類は次の6つです。
| ツールカテゴリ | 最適なユースケース | 具体例 | セキュリティリスク |
| Web検索 (Web search) | 最新の事実、公開されているドキュメントの取得 | 検索APIの統合 | 低 (読み取り専用) |
| 情報の検索と抽出 (Retrieval) | ドメイン固有の社内知識の取得 | ベクトル検索、ナレッジグラフのクエリ | 低〜中(読み取り専用、または書き込み権限) |
| 計算 (Computation) | 決定論的なワークフローや計算の実行 | コードインタープリタ、数学ライブラリ | 中 (コードの実行) |
| ファイル操作(File) | ファイルの読み込みおよび書き込み | ファイルシステムへの読み書き操作、オブジェクトストレージ | 中〜高 (書き込み処理) |
| コンピュータ操作 (Computer-use) | ブラウザやデスクトップのUI自動化 | スクリーンエージェント、ブラウザドライバー | 高 (広範なシステムアクセス) |
| ビジネスと生産性 (Business and productivity) | 実際のワークフローの実行 | 電子メール、カレンダー、CRM、チケット管理API | 高 (外部への影響) |
これら6つのカテゴリは有用なメンタルモデル(思考の枠組み)ですが、普遍的な分類ではありません。フレームワークによってその分類方法は異なります。たとえば、OpenAIは、ホスト型/関数型/MCPなど実行場所でツールをグループ化し、Anthropicはクライアントサイド/サーバーサイドで分類し、LangChainは機能ドメインごとに分類しています。重要なのは、各ツールの目的を明確化する独自のメンタルマップを自身が持つことです。そのマップが他者と一致しているか否かは重要ではありません。
これらのカテゴリ分類を活用して、AIエージェントのスコープは、「ジョブに必要なもの」に限定してください。たとえば、「サポートのトリアージ」エージェントは、リトリーバル(情報の検索と抽出)、CRMの更新、チケットの作成のみを担います。「リサーチ」エージェントは、Web検索、ファイルアクセス、コード実行を担います。「金融のコパイロット」エージェントのスコープはさらに狭く、構造化データベースへのアクセスやポリシーのリトリーバルのみを担い、書き込み処理は承認ワークフローによって制御されるようにします。
ツールセットの定義が明確であればあるほど、AIエージェントの信頼性と予測可能性が高まります。
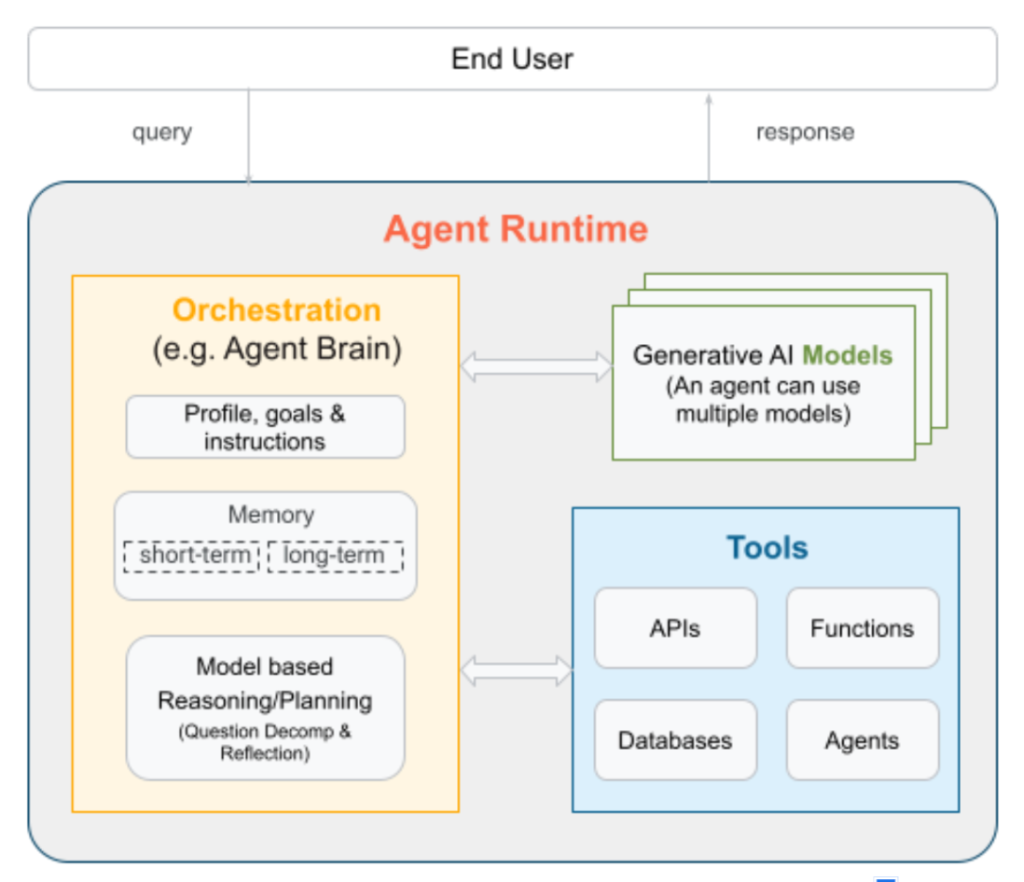
AIエージェントのコアコンポーネントには「ツール」「メモリ」「推論」がある
エージェント「ツール」とエージェント「スキル」の違い
「ツール(Tools)」と「スキル(Skills)」という言葉は混同されがちですが、技術スタックにおいて両者は異なるレイヤーに位置します。
「ツール」とは、Web検索やデータベースクエリのような、個別の呼び出しが可能な関数です。エージェントがいつ呼び出すかを決定し、ツールは1つの処理を実行して結果を返し、そのループを継続します。
「スキル」とは、エージェントが、問題をどのように推論するかを方向付ける、より高次の能力です。Anthropic社は2025年に「Agent Skills」をオープンスタンダードとしてリリースしました。このフォーマットは、指示、スクリプト、リソースをフォルダにバンドルし、関連性がある場合にClaudeが動的にロードします。MicrosoftのSemantic Kernelも同様の「スキル」という概念を採用しています。多くのLangChainやLlamaIndexの構成では、「スキル」という概念を持たず、プロンプトとツールのみで動作を組み立てています。
「ツール」は「エージェントは何ができるか?」に答え、「スキル」は「各ジョブにエージェントがいかにアプローチするか?」に答えるものです。 ほとんどの本番環境エージェントにはこの両者が必要です。「ツール」はエージェントに「手」を与え、「スキル(あるいはフレームワークの同等機能)」は、「ツールをいつ、どのように使うべきか」を教えます。
実際には、その違いは見た目以上に明確です。2つのツール (cypher-read および web-search) と、必要に応じてロードされるスキルファイルのフォルダ(cypherテンプレート、マルチホップパターン、インライン引用など)を有するGraphRAGエージェントを考えてみましょう。「ツール」はアクションを実行します。「スキル」は、計画立案(planner)と実行(executors)がツールを選択する前に、「質問についてどのように推論するか」という方向付けを行います。この2つを統合してしまうと、ツールの説明文が肥大化したり、システムプロンプトが冗長化したりします。2つを分離しておくことでツール数を低く抑え、必要なときにのみ推論のコンテキストをロードすることが可能となります。
エージェントのツール選択方法と使用方法
ツールを使用するエージェントは、1つの「ループ(反復処理)」に従います。モデルはタスクについて推論し、ツールを選択して実行し、結果を読み取って、次に何をすべきかを決定します。この「ループ」は、タスクが完了するか、停止条件が発動するまで繰り返されます。
このループを、推論(Reasoning)+行動(Acting)を合わせた造語で ReAct パターンと呼びます。エージェントのランタイム(実行環境)において、「ループ」は次の役割を果たします。モデルが「構造化されたツール呼び出しを出力し、その結果を読み取り、そのまま継続するか否かを判断します。
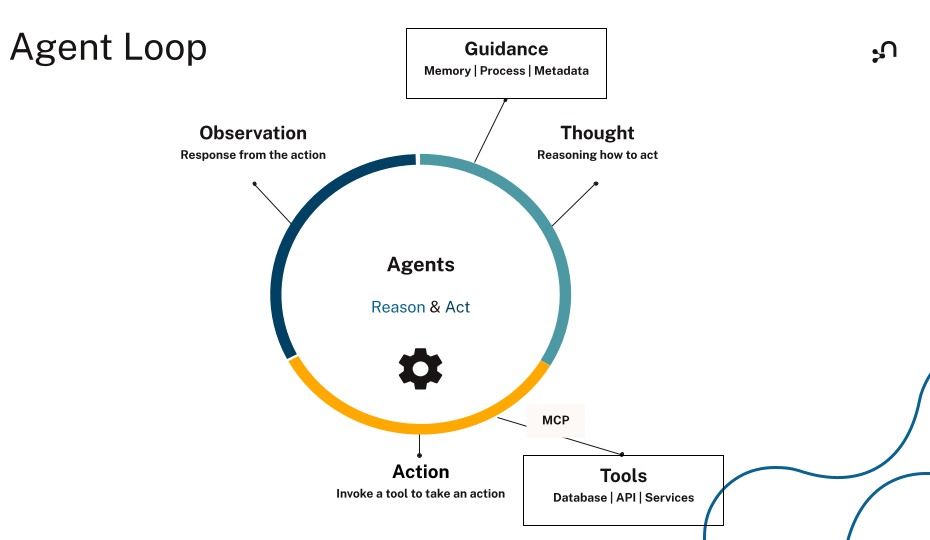
ReActパターンは、エージェントが次に何をすべきかを決めるために、環境からの観察結果を用いて、推論と行動の間をどのように行き来するかを示す
ツールの選択は、開発者がモデルに提供する「定義」から始まります。曖昧な名前、不十分あるいは重複する説明、緩いスキーマ(定義体)などはすべて、モデルに「誤った呼び出し」をさせる原因となります。
「モデル」は、そのツールが何を行うのか、いつ使用すべきなのか、そしてどのような入力を渡すべきなのかを知る必要があります。「ツール」は、「モデル」と「外部システム」との間の「インターフェース(接点)」です。ツールが実行されると、その結果はループの次のステップへとフィードバックされます。
また、エージェントはツールの呼び出しを連鎖(Chain)させます。最初の結果を利用して次の呼び出しを作成します。つまり、呼び出しによって問題を絞り込み、行動や回答を行うための十分な情報が得られるまでエージェントは連鎖を継続させます。これによってエージェントは複数の手順を要するタスクの処理が可能となるのです。
ツールは現実世界のアクションを引き起こす可能性があるため、「ガードレール(適切な制限)」を設けることが重要です。エージェントがメッセージの送信、データの書き込み、ワークフローの開始を行える場合は、その権限範囲を限定し、入力の妥当性を検証し、いつ停止すべきかを明確に定義してください。レコードの削除や外部へのメッセージ送信など、後から取り消せないアクションについては、必ず人間による承認(Human-in-the-loop)を経るようルーティングしてください。また、ツールからの出力は「信頼できない入力」として扱う必要があります。ツールが返す悪意のあるドキュメントやウェブページには、エージェントをリダイレクトさせようとするプロンプトインジェクションが含まれている可能性があるためです。
MCPのエージェントツール統合の標準化
Model Context Protocol (MCP) が登場する前は、ツールの統合はすべて手作業で行われていました。各エージェントスタックは、フレームワークやサービスごとに独自のグルーコードが必要でした。そのため統合は壊れやすく、拡張性も低いものでした。
しかしMCPのクライアントとサーバー間の「共通プロトコル」によってこの状況は一変しました。AIアプリケーションと外部システムを接続するためのオープンソース標準で、エージェントは利用可能なツールを検出し、その入力を読み取り、単一インターフェースを介してサービス間でそれらを呼び出すことができます。
直接的なAPI統合とは異なり、MCPでは各サービスに関するハードコードされた知識は必要ありません。なぜならLanguage Server Protocol(LSP)から着想を得たJSON-RPC 2.0プロトコルは、MCPサーバーが公開しているツール、リソース、プロンプトをAIアプリケーションが検出し、呼び出す方法を標準化したものだからです。サーバーはstdio経由のローカル、または、ストリーミング可能なHTTP経由のリモートで実行できるため、同一のサーバー定義を開発者のラップトップから本番環境へ、そのままデプロイできます。機能の調整はプロトコルレベルで行われるため、エージェントは実行時に機能を検出して呼び出すことが可能です。
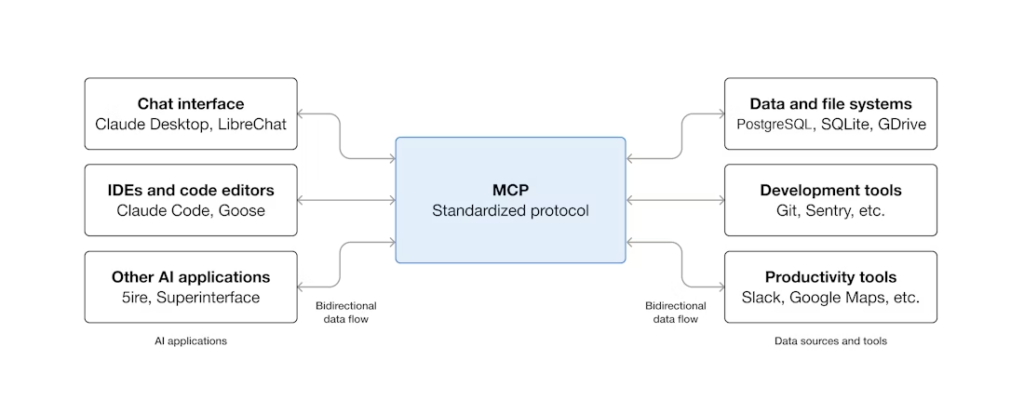
MCPとファンクションコーリング(関数呼び出し)は、競合する規格ではありません。ファンクションコーリングはモデル側の機能です。LLMは、ツールの定義がプロンプトとして与えられると、構造化された呼び出しを発行します。一方、MCPはサーバー側のプロトコルです。ツールがどのように記述、ホスト、および呼び出されるかを標準化するものです。エージェントフレームワークは、MCPサーバーからツールの定義を読み取り、それをファンクションコーリングの形式でモデルに渡し、モデルから返される構造化された呼び出しをサーバーへとルーティングします。つまり、MCPは「輸送手段」であり、ファンクションコーリングはモデルが使用する「通信フォーマット」なのです。
MCPのエコシステムは急速に拡大しています。データベース、SaaSプラットフォーム、開発者ツールが次々とMCPサーバーを公開しています。LangChain、LangGraph、LlamaIndex、GoogleのAgent Development Kitなど主要なエージェントフレームワークもMCPをすでにサポートしているか、そうでない場合はサポートの組み込みを進めています。ChatGPT、Claude、VS Codeといったクライアントは、すでに標準でMCPに対応しています。一度統合を構築してしまえば、MCPを認識できるすべてのエージェントがツールを利用可能となります。
ただし、「標準化=ガバナンス不要」ではありません。エージェントがデータを書き込んだり、アクションを承認したり、機密性の高いシステムにアクセスしたりできる場合は、これまでと同様のガードレールを適用します。つまり、権限のスコープを制限し、入力を検証し、影響の大きいアクションは人間による承認(Human-in-the-loop)を経るようにルーティングしてください。
エージェントツールの実装方法
まず最初に決めるべきは、どのフレームワークを使用するかです。LangChain、LangGraph、OpenAI Agents SDKは、いずれもツールの登録、ReActループ、ツールの結果をモデルのコンテキストにフィードバックする処理を扱っています。開発者が実行ループを自作する必要はありません。フレームワークを選んでその処理を任せ、開発者はツールの開発そのものに時間を使いましょう。
ツールとは、モデルに紐づけされた、以下の3つの要素を持つ関数です。
- モデルがツールを選択するために使用する名前(Name)
- モデルにいつそれを呼び出すべきかを伝える説明(Description)
- どのような引数を渡すべきかを定義する入力スキーマ(Input Schema)
これら3つすべてが正確である必要があります。次の例では、LangChainとlangchain-neo4jパッケージを使用して、既存のNeo4jベクトルインデックスに対するベクトル類似性検索ツールを公開しています。まず、依存関係をインストールします。
pip install langchain-neo4j langchain-openai
次に、ツールを定義します。
from langchain.tools import tool
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings
# Neo4jベクトルインデックスと同じ埋め込みモデルを使用する
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 既存のNeo4jベクトルインデックスへ接続
vector_store = Neo4jVector.from_existing_index(
embedding=embeddings,
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name="vector", # インデックス名に合わせて変更してください
)
@tool
def search_vector_index(query: str) -> str:
"""
クエリに関連する一節をNeo4jベクトルインデックスから検索します。
エージェントがNeo4jに格納された埋め込みコンテンツを取得する必要がある際に使用します。
グラフの書き込み処理には使用しないでください。
"""
results = vector_store.similarity_search(query, k=5)
if not results:
return "関連する一節が見つかりませんでした。"
return "\n\n".join(doc.page_content for doc in results)これで、ユーザーのquery(クエリ)を入力として受け取る search_vector_index という名前のツールが作成されました。説明文(docstring)は、エージェントに対し、Neo4jに保存された埋め込みコンテンツを取得する必要があるときにこれを使用し、グラフへの書き込みには使用しないよう指示しています。
この「説明(Description)」は、モデルが正しいツールを選択するかどうかを決定づける最大の要因となります。曖昧な説明や記述の欠落は、誤った呼び出しに直結するため、そのツールが何を行うのか、どのような結果を返すのか、そしてどのような用途に適さないのかを明確に記述してください。
なぜリトリーバルツールが最も重要か
前述の6つのカテゴリの中で、大多数のエージェントが最も時間を費やすのが「リトリーバル(情報の検索・抽出)」であり、出力の精度の低さが最も悪影響を及ぼすのもリトリーバルです。不十分なコンテキストを抽出すれば、後続の呼び出しはすべて、その不十分な情報に基づいて実行されることになるためです。
前述の実装例にあるベクトル検索ツールは、クエリを埋め込み化し、最も近いチャンクを返すという一般的なユースケースをカバーしています。これは、非構造化テキストや、1ステップで済む単純な質問に対してはうまく機能します。しかし、例えば顧客関係、サプライチェーンの依存関係、コンプライアンスポリシーなど、エンティティ間の関係性にその回答が依存する場合には問題が生じます。この段階では「類似性」は適切なプリミティブ(基本要素)ではなくなり、「トラバーサル(探索)」こそが適切な手段となります。
そこで真価を発揮するのが、「グラフリトリーバル(グラフ検索)」です。ナレッジグラフは、ノードと関係性を紐づけしたデータを保管し、エンティティそのものと、エンティティの周辺ですべてがどのようにつながっているかを捉えます。GraphRAGはその探索とRAG(Retrieval-Augmented Generation)を組み合わせるため、エージェントは単にチャンクに順位をつけるだけでなく、パスを辿ることができるようになります。辿ったパスは、エージェントが提示できる「根拠」としても機能します。
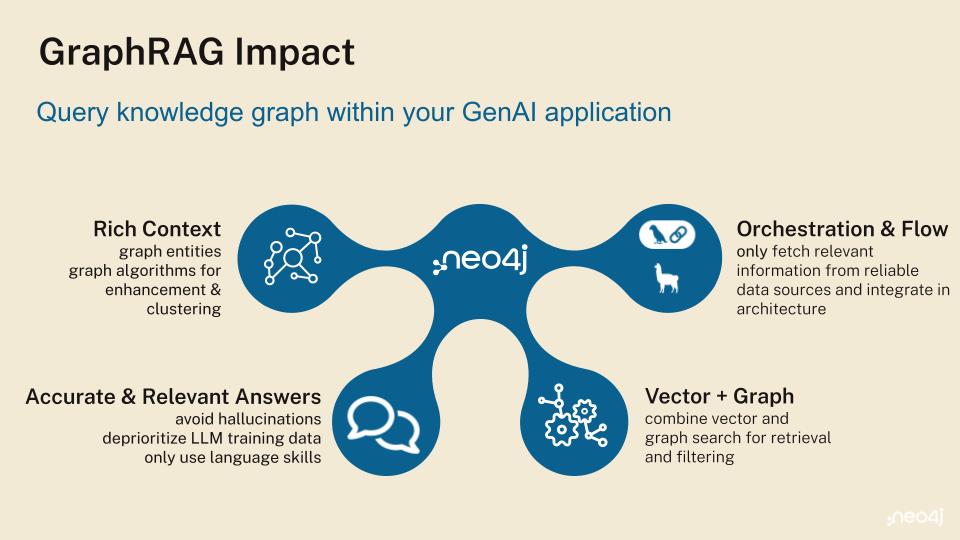
GraphRAG はグラフの探索とベクトル検索を組み合わせることで、より豊かで、より関連付けされた文脈をエージェントに提供する
ツールを通じてこれを公開するために大きな変更は不要です。Neo4j MCP サーバ (ドキュメント) には、MCP対応エージェントが呼び出せる4つのプリミティブが用意されています。グラフモデルを読み取るための get-schema、 Cypher®でのトラバーサルやベクトル類似性検索を行うための cypher-read、更新用の cypher-write、 そして Graph Data Science がインストールされている場合に、PageRank、コミュニティ検出、最短経路などのグラフアルゴリズムを利用可能にする list-gds-procedures です。これらを前述のベクトルツールの代わりに、あるいは追加して使用するだけで、エージェントはスキーマの検査、関係性の探索、アルゴリズムの実行ができ、その結果に基づいて行動できるようになります。
リトリーバルツールは、エージェントが次に正しい判断を下すために必要な文脈を返すことで、その価値を発揮します。意味的な類似性は必要な文脈を見つけるための1つの方法ですが、カスタマーサポート、金融リスク、サプライチェーン、サイバーセキュリティ、コンプライアンスといった相互に関連する分野では、通常、関係性を辿る方がより効果的です。
AIエージェントに 必要なコンテキストレイヤーを構築する
ビジネスに関して、正確で説明可能な回答を提供してくれるエージェントを構築する際、リトリーバルを後回しにすることはできません。まずはタスクを解決できる最小限のツールセットから始めてください。そして、活用する価値のあるコンテキストレイヤーを構築してください。多くの企業のユースケースにおいて、これは、「孤立したドキュメント」や「個別の検索」から、エージェントが推論の各ステップで検査、探索、再利用できる「連携されたデータ」へと移行することを意味します。
グラフインテリジェンスプラットフォームであるNeo4j は、ナレッジグラフやベクトル検索、そして65種類のグラフアルゴリズムを「エージェント型AI」向けに構築した単一のプラットフォームに統合しています。ネイティブのベクトルストア、リトリーバー、およびツールラッパーを、LangChain、LlamaIndex、LangGraphに搭載しています。
あなたの次期エージェントに、関係性を踏まえて推論を行い、回答の根拠を示し、関連する企業コンテキストに基づいて行動させたいならば、「エージェント型GraphRAG」をツールセットに組み込みましょう。
次のステップ
現在の開発状況に合わせて、いずれかを選択してください。
- 構造化されたナレッジグラフをあなたのAIエージェントに提供するために、Neo4j AuraDB Free でクラウド上に無料のグラフデータベースインスタンスを作成する。
- LLM Knowledge Graph Builderを使用して、非構造化データからナレッジグラフを構築する。
- Neo4j MCP server を介して、グラフ検索とベクトル検索をツールとしてエージェントに提供する。
- 無料ハンズオンコースで、独自のGraphRAG MCPツールを構築する方法を学ぶ: GraphAcademy: Building GraphRAG Python MCP tools

エージェントツールに関するFAQまとめ
Q: エージェントツールとは何ですか?
A: エージェントツールとは、AIエージェントが外部システムと相互作用し、テキスト生成を超えたタスク(Webの検索、データベースのクエリ、電子メールの送信、Webページの閲覧など)を実行できるようにするための関数やサービスです。
Q: エージェントはどのようにツールを選択し、使用しますか?
A: モデルは実行時に各ツールの名前と説明を読み取り、どのツールがタスクに適しているかを判断します。その後、引数を含む構造化された呼び出しを出力し、結果を受け取り、続行するか停止するかを決定します。このサイクルは、タスクが完了するか、停止条件が発動するまで繰り返されます。
Q: エージェントツールにはどのような種類がありますか?
A: ほとんどのエージェントツールは次の6つのカテゴリに分類されます。①Web検索、②検索(リトリーバル)、③計算、④ファイル操作、⑤コンピュータ使用(ブラウザやデスクトップの操作)、⑥電子メール、カレンダー、CRM統合などのビジネス・生産性ツール
Q: MCPはどのようにしてエージェントによるツールの使用を可能にするのですか?
A: Model Context Protocol(MCP)は、エージェントがどのツールをサーバーが提供しているかを動的に検出できるようにするオープン標準のプロトコルです。サービスやフレームワークごとに固有のカスタム統合コードを書くことなく、一貫したインターフェースを通じて入力スキーマを読み取り、ツールを呼び出すことができます。
Q: エージェントツールとエージェントスキルは、どう違うのですか?
A: ツールとは、エージェントが1つの処理を実行するために呼び出す、個別の呼び出し可能な関数です。スキルとは、エージェントがあるクラス(種類)の問題をどのように推論するかを方向付ける、より高次の能力(通常、指示、文脈、サブワークフローの集まり)です。ほとんどの本番環境のエージェントには両者が必要です。
Q: エージェントツールは安全ですか?
A: エージェントツールは、適切なガードレールを設けることで安全に運用できます。ベストプラクティスとしては、権限のスコープ制限、厳格な入力検証、不可逆的なアクションに対する人間の承認、そしてプロンプトインジェクション攻撃を防ぐためにツールの出力を「信頼できない入力」として扱うことなどが挙げられます。
Q: なぜエージェントのパフォーマンスにおいて情報の検索と抽出(リトリーバル)が重要なのですか?
A: エージェントのパフォーマンスは、正確で、関連性が高く、関連付けられた文脈(コンテキスト)に依存します。まずはタスクを解決する最小限のツールセットから始め、検索レイヤーを強化してください。ほとんどのエンタープライズのユースケースにおいて、それは孤立したドキュメントやピンポイントの検索から、エージェントが推論ステップ全体で検査、探索、および再利用できる「関連づけられた知識(Connected Knowledge)」へと移行することを意味します。
Neo4jの国内取り扱いに関してはクリエーションラインにお気軽にお問い合せください。
Neo4jのサービス詳細はこちら。



